Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OpenSearchでレガシーな検索処理の大幅改善をやってやろう
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
DPon
April 12, 2025
Technology
1.1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OpenSearchでレガシーな検索処理の大幅改善をやってやろう
DPon
April 12, 2025
More Decks by DPon
See All by DPon
TiDBのアーキテクチャから学ぶ分散システム入門 〜MySQL互換のNewSQLは何を解決するのか〜 / tidb-architecture-study
dznbk
1
370
『自分なんかが…』を超える。 プロポーザル提出までの心理的ハードルの外し方 / proposal-output
dznbk
1
1.9k
つよつよな人の理解の早さを理解する
dznbk
0
180
テスト書きたいけど 書けてないのは 何でなんだぜ
dznbk
0
180
php-fpmのプロセスをコントロールする
dznbk
0
35
Other Decks in Technology
See All in Technology
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
130
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
380
シンガポールで登壇してきます
yama3133
0
110
Making sense of Google’s agentic dev tools
glaforge
1
190
ゼロをイチにする仕事が終わったあと
smasato
0
340
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
210
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
KiCAD講習会②
tutcreators
0
110
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.1k
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2.3k
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
4
2.8k
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
2
760
Featured
See All Featured
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Code Reviewing Like a Champion
maltzj
528
40k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Transcript
OpenSearchでレガシーな検索処理の 大幅改善をやってやろう PHPカンファレンス小田原2025
自己紹介 • 堂薗 伸樹(どうぞの のぶき) / DPon(@DPontaro) ◦ 園 薗 •
職業:エンジニア • 所属:スターフェスティバル株式会社 • 家族:妻 子👦👦 犬 • ゲーム好き • 大阪からきました • 🎉 カンファレンス初登壇 🎉
会社とサービスの話 • https://gochikuru.com/ • 法人・団体向けの宅配弁当 ケータリング・オードブルの デリバリーサービス。
前段 プロジェクトの説明
プロジェクトの特徴 • ごちクルとは別の特定業界向けのお弁当デリバリーサービス • Initial Commitは2015年 • コロナ禍で需要減。リソース都合もあり、しばらく専任のエンジニアがついていない 状態。 •
ときどき改善依頼があった際、手が空いてる人がスポットでアサインされる
パフォーマンスの課題 • 2024年春、サイトのパフォーマンスは少し触れただけでも体感できるくらいに悪い • 需要が戻りつつあるなか、マイナスの印象を与えるわけにもいかない
レガシーな環境
初手の改善
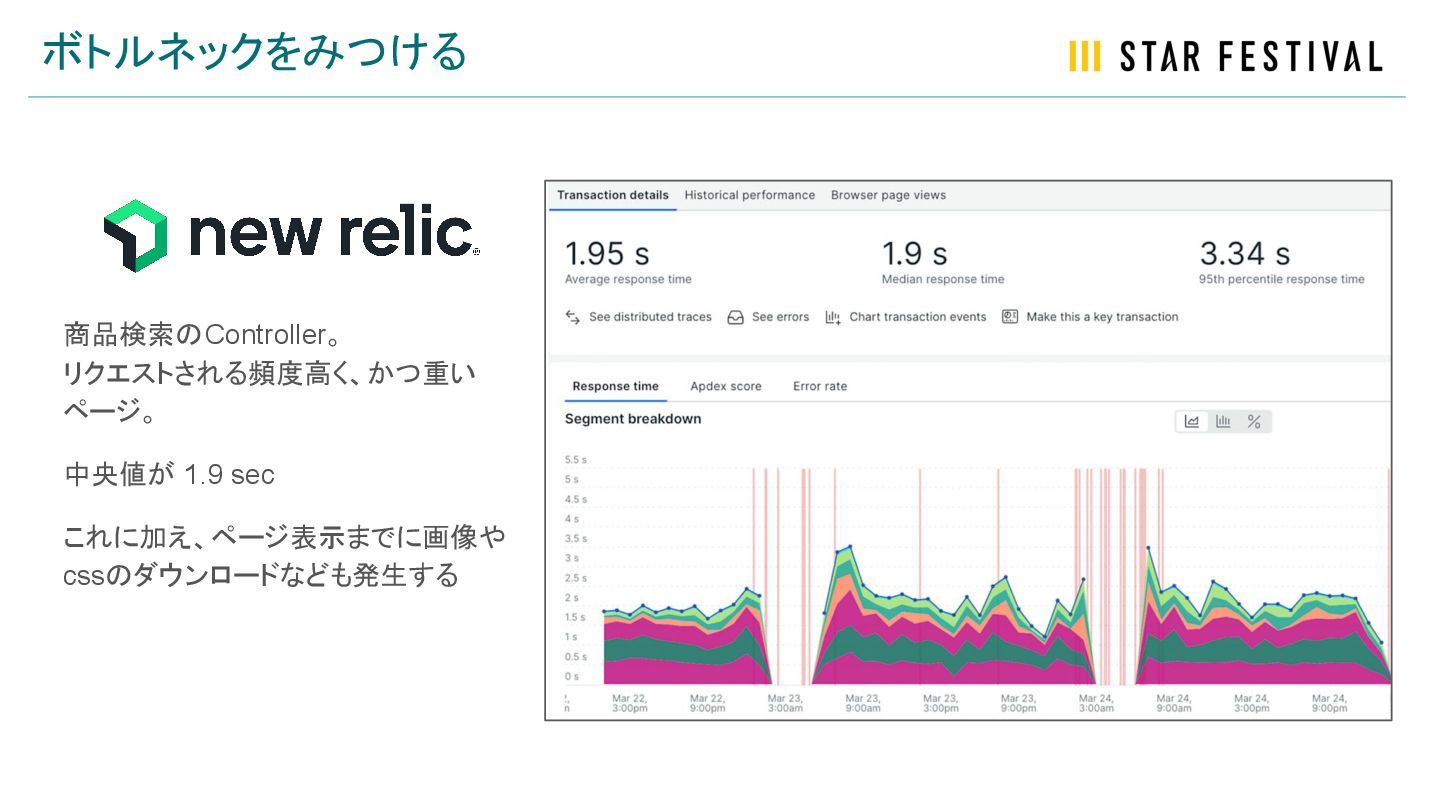
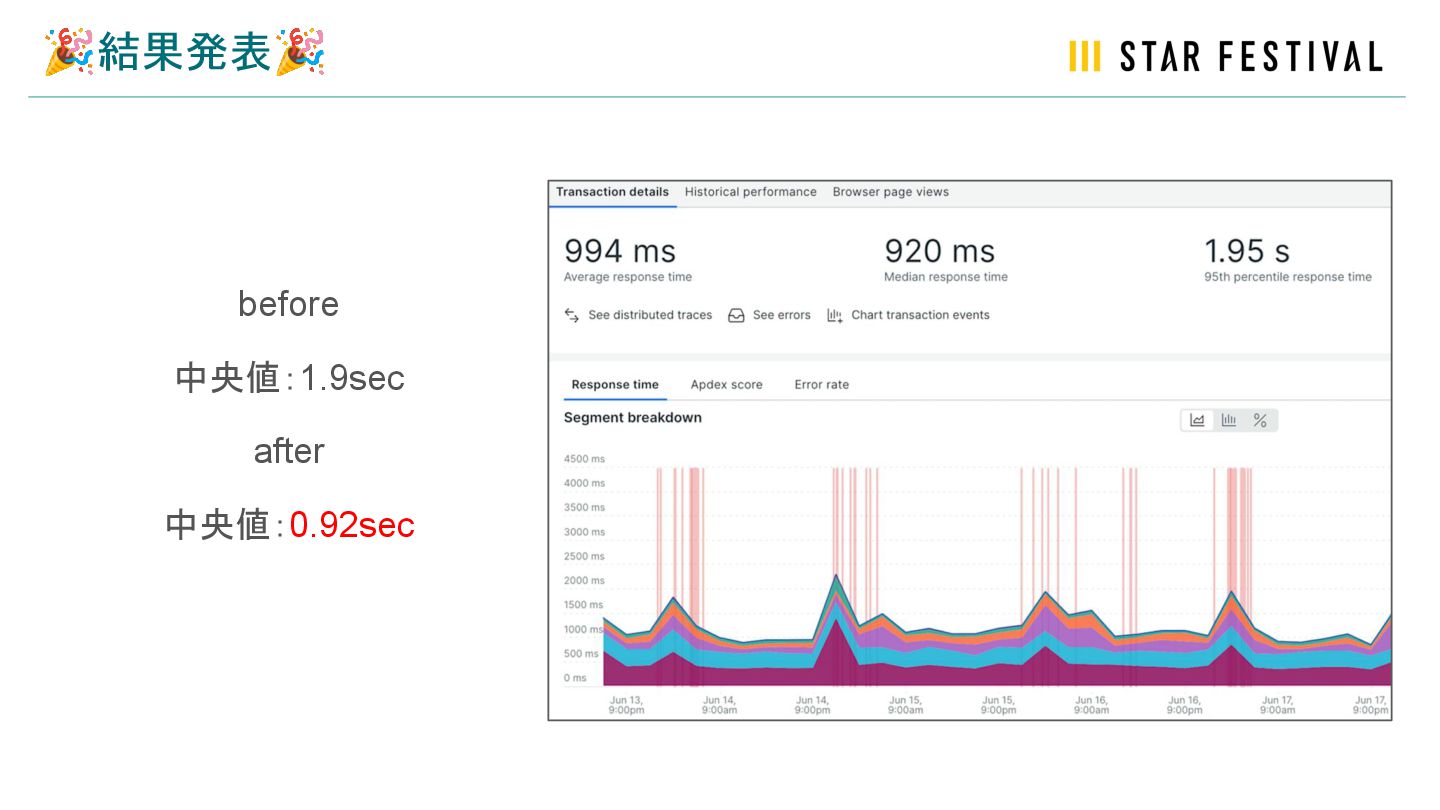
ボトルネックをみつける 商品検索のController。 リクエストされる頻度高く、かつ重い ページ。 中央値が 1.9 sec これに加え、ページ表示までに画像や cssのダウンロードなども発生する
初手の改善 スロークエリに手を入れてみる • INDEXの追加 • 該当箇所のコードを調整し、発行されるクエリを修正 結果200msec くらいは改善したが焼け石に水。
さてどうしたものか 長年専任がついていないプロジェクト、コードはツギハギで無駄も多い。 複雑に絡み合ったコードの解消のために、検索ロジック全体を組み直す必要がありそ う。 → それならもう OpenSearch に移行してもいいのでは?
OpenSearchとは • 分散型の検索エンジン。Elasticsearchのフォーク版 • クラスタ構成、複数のノードにデータ分散。 • 高速な全文検索が可能
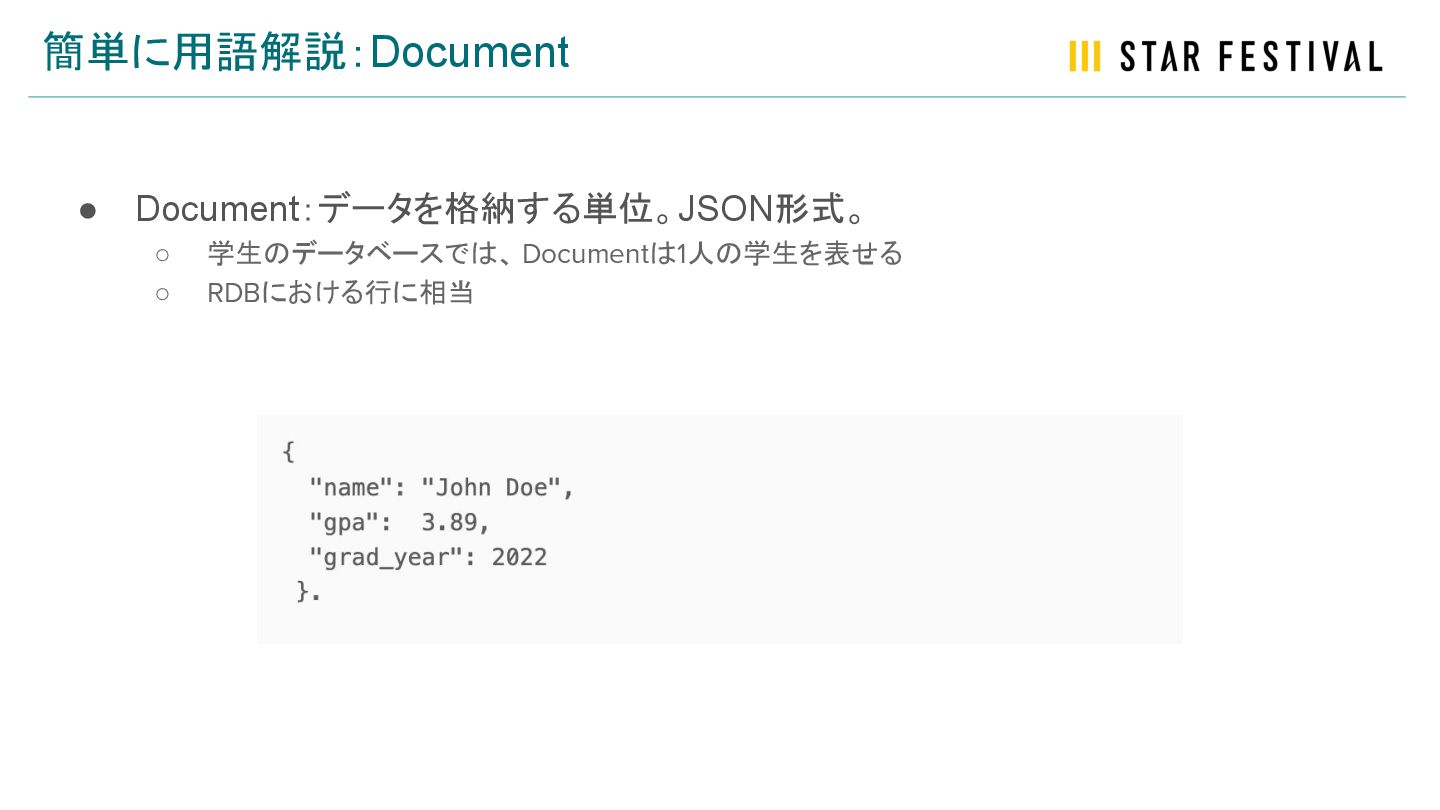
簡単に用語解説:Document • Document:データを格納する単位。JSON形式。 ◦ 学生のデータベースでは、 Documentは1人の学生を表せる ◦ RDBにおける行に相当
簡単に用語解説:Index • Index:Documentの集まり ◦ RDBでいうテーブル ◦ 学生のデータベースでは、 Indexはすべての学生を表す
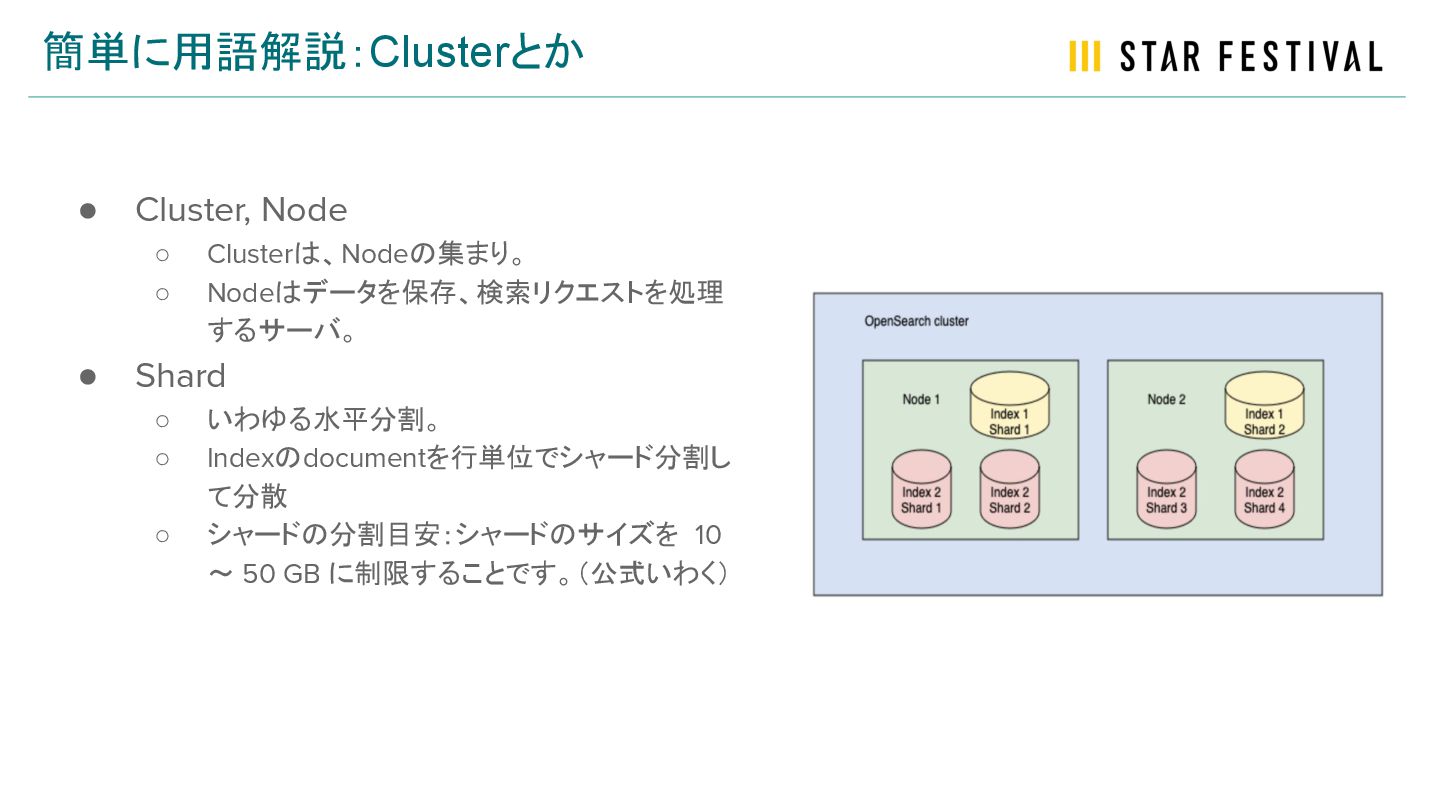
簡単に用語解説:Clusterとか • Cluster, Node ◦ Clusterは、Nodeの集まり。 ◦ Nodeはデータを保存、検索リクエストを処理 するサーバ。 •
Shard ◦ いわゆる水平分割。 ◦ Indexのdocumentを行単位でシャード分割し て分散 ◦ シャードの分割目安:シャードのサイズを 10 ~ 50 GB に制限することです。(公式いわく)
OpenSearchへの移行
OpenSearch公式のPHPクライアント まぁバージョン下げたら対応してるやつあるやろ。 https://github.com/opensearch-project/opensearch-php
おっかしいなー
真面目にどうするか 理想はPHPのバージョンアップ。そうはいっても • スポット的なアサインでもあり、メインは別プロジェクトの人員 • 元のミッションはパフォーマンス改善。 →バージョンアップはスコープ外では? • 認知負荷の高いコードの理解、スロークエリの対応など既にある程度時間もかけて いる。
→このタイミングからバージョンアップまでやる? ※言わずもがなテストはメンテされておらず
戦略的後回し // TODO PHPバージョンアップ 結局公式のPHP7.3が対応してるバージョンのクライアントを落としてから、7.1で動くよう にエラーが出る箇所をつぶして対応させました。 ※バージョンアップはパフォーマンス改善後に対応しました(7.4までですけど...
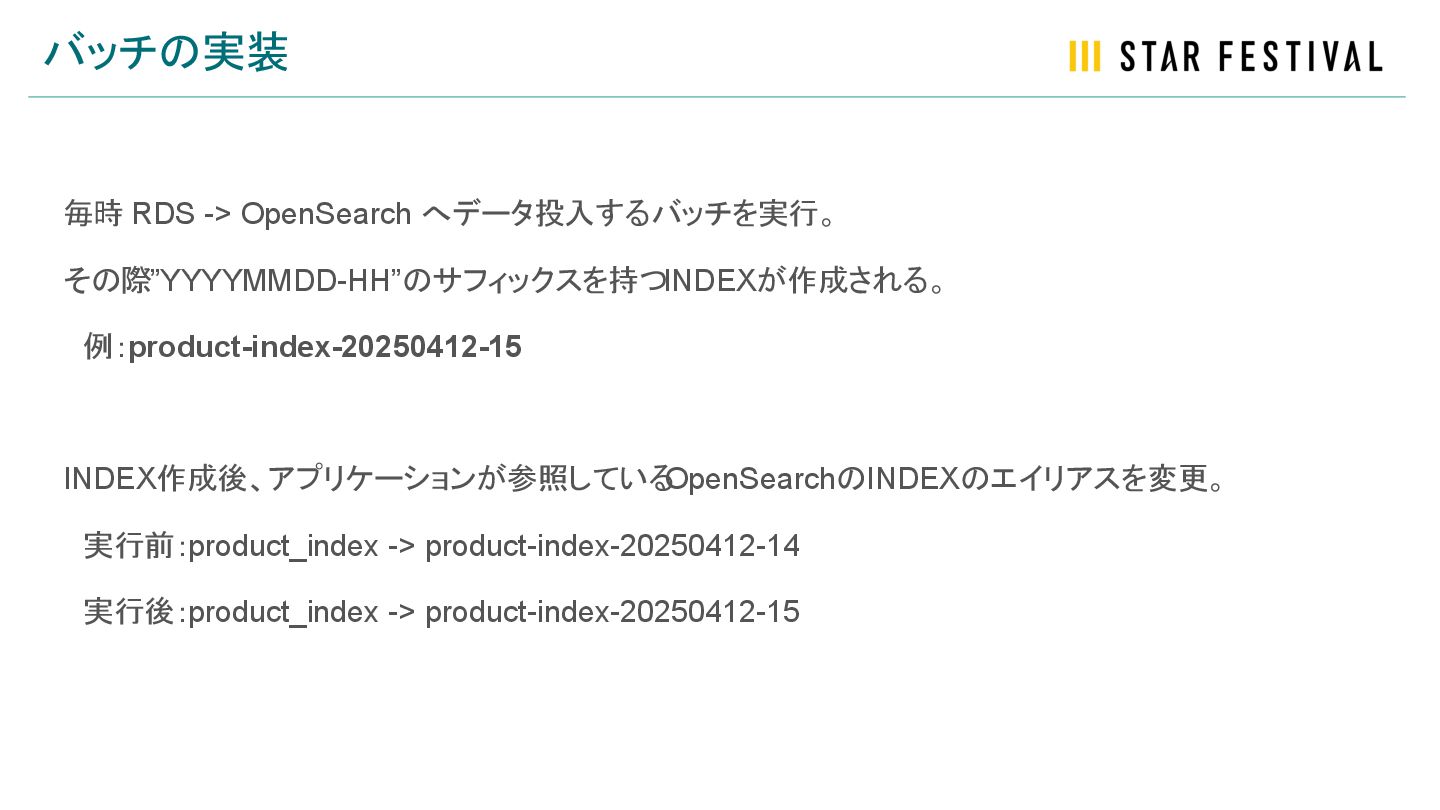
バッチの実装 毎時 RDS -> OpenSearch へデータ投入するバッチを実行。 その際”YYYYMMDD-HH”のサフィックスを持つINDEXが作成される。 例:product-index-20250412-15 INDEX作成後、アプリケーションが参照している OpenSearchのINDEXのエイリアスを変更。
実行前:product_index -> product-index-20250412-14 実行後:product_index -> product-index-20250412-15
マッピングの話 マッピングはOpenSearchに、ドキュメントとそのフィールドの保存方法とインデックスを指示します。 各フィールドのデータ型を指定することで (例えば、年を日付にするなど )、保存やクエリをより効率的に行うこと ができます。 Dynamic mapping (動的マッピング) 新しいデータやフィールドが自動的に追加される。
Explicit mapping (明示的マッピング) 推奨。正確な構造とデータ型を前もって定義できる。 パフォーマンスや正確性を高めることができる
マッピング一例 "id": map[string]string{"type": "integer"}, "product_name": map[string]interface{}{ "type": "text", "analyzer": "product_index_analyzer",
"search_analyzer": "product_search_analyzer", },
analyze 文字列を検索に使えるように「分かち書き(トークン化)」&「正規化」する処理
analyzer と search_analyzer "product_name": map[string]interface{}{ "type": "text", "analyzer": "product_index_analyzer", "search_analyzer":
"product_search_analyzer", }, analyzer:インデックス時(保存時)に使用する analyzer を指定。 search_analyzer:検索時に使用する analyzer を指定
synonym_filter search_analyzer には上記のsynonym_filterという同義語の設定がされている。 この設定により曖昧検索に対応できる "synonym_filter": map[string]interface{}{ "type": "synonym", "synonyms": []string{
"ウナギ,ウナジュウ", "子供,お子様",
やってみてどうだった
🎉結果発表🎉 before 中央値:1.9sec after 中央値:0.92sec
売上につながった? ここ1年で売上の数値はしっかり伸びている 🎉 複数要因があるものではありますが、パフォーマンス改善で下支えが出来た ※余談 社内の営業の方々から直接 DMでめちゃ助かったと何人か声かけていただいて、好感触
他改善するなら • 毎時のバッチ実行 ◦ 日々商品のデータは更新されているが、最大 1時間の遅延を許容している状態 ◦ よりリアルタイムに更新したい場合、イベント駆動な仕組みを取り入れたり • インフラのあいのり
◦ ごちクルと同じインスタンスなので障害発生した際は、どちらも検索処理が機能しなくなる(今のとこ ろ発生はしていない) ◦ 切り離せば懸念はなくなるが、コスト増にはなるのでバランス考えて • synonym_filterなどがコード中に定義されている ◦ 変更の際にエンジニアの手が入る状態となっているので、できれば外部ファイルに逃がしたほうが 良い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![マッピング一例 "id": map[string]string{"type": "integer"}, "product_name": map[string]interface{}{ "type": "text", "analyzer": "product_index_analyzer",](https://files.speakerdeck.com/presentations/c8c8d736fbca4e0080da43771d815641/slide_22.jpg){kind=link}
{kind=link}
![analyzer と search_analyzer "product_name": map[string]interface{}{ "type": "text", "analyzer": "product_index_analyzer", "search_analyzer":](https://files.speakerdeck.com/presentations/c8c8d736fbca4e0080da43771d815641/slide_24.jpg){kind=link}
![synonym_filter search_analyzer には上記のsynonym_filterという同義語の設定がされている。 この設定により曖昧検索に対応できる "synonym_filter": map[string]interface{}{ "type": "synonym", "synonyms": []string{](https://files.speakerdeck.com/presentations/c8c8d736fbca4e0080da43771d815641/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}