Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Capsule Network Introduction
Search
koki madono
January 06, 2020
Education
0
370
Capsule Network Introduction
研究室のゼミで紹介したスライドです
不明点・指摘など議論お願いします.
koki madono
January 06, 2020
Tweet
Share
More Decks by koki madono
See All by koki madono
MIRU2020若手の会グループA発表
madonokouki
0
240
perception_distortion_tradeoff.pdf
madonokouki
1
140
AAAIWS2020_oral_pptx
madonokouki
0
120
modeling_point_cloud.pdf
madonokouki
0
66
Other Decks in Education
See All in Education
今も熱いもの!魂を揺さぶる戦士の儀式:マオリ族のハカ
shubox
0
210
仮説の取扱説明書/User_Guide_to_a_Hypothesis
florets1
4
300
社外コミュニティと「学び」を考える
alchemy1115
2
160
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
1.7k
2025年度春学期 統計学 第1回 イントロダクション (2025. 4. 10)
akiraasano
PRO
0
170
より良い学振申請書(DC)を作ろう 2025
luiyoshida
1
3.2k
OJTに夢を見すぎていませんか? ロールプレイ研修の試行錯誤/tryanderror-in-roleplaying-training
takipone
1
150
著作権と授業に関する出前講習会/dme-2025-05-01
gnutar
0
200
登壇未経験者のための登壇戦略~LTは設計が9割!!!~
masakiokuda
2
430
Gaps in Therapy in IBD - IBDInnovate 2025 CCF
higgi13425
0
480
プレゼンテーション実践
takenawa
0
4.2k
Design Guidelines and Principles - Lecture 7 - Information Visualisation (4019538FNR)
signer
PRO
0
2.4k
Featured
See All Featured
How to Think Like a Performance Engineer
csswizardry
24
1.7k
The Power of CSS Pseudo Elements
geoffreycrofte
77
5.8k
Designing Experiences People Love
moore
142
24k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.3k
The Illustrated Children's Guide to Kubernetes
chrisshort
48
50k
Rails Girls Zürich Keynote
gr2m
94
14k
Rebuilding a faster, lazier Slack
samanthasiow
81
9k
It's Worth the Effort
3n
184
28k
Typedesign – Prime Four
hannesfritz
42
2.7k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
26k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
29
2.7k
Site-Speed That Sticks
csswizardry
10
650
Transcript
Capsule Network (Introduction)
2 Geoffrey Hinton talk "What is wrong with convolutional neural
nets ?”, December, 4, MIT https://www.youtube.com/watch?v=rTawFwUvnLE The pooling operation used in CNN is a big mistake and the fact that it works so well is a disaster. (2014, MIT talk)
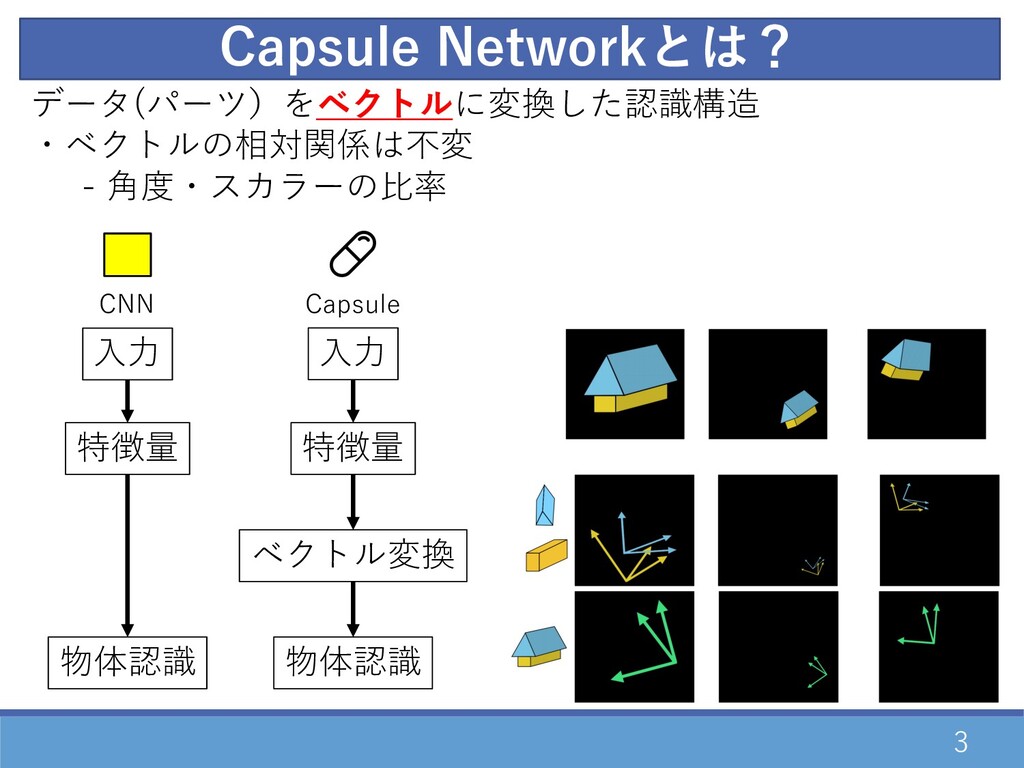
3 データ(パーツ)をベクトルに変換した認識構造 ・ベクトルの相対関係は不変 - ⾓度・スカラーの⽐率 Capsule Networkとは? ⼊⼒ ベクトル変換 物体認識
⼊⼒ 特徴量 特徴量 物体認識 Capsule CNN
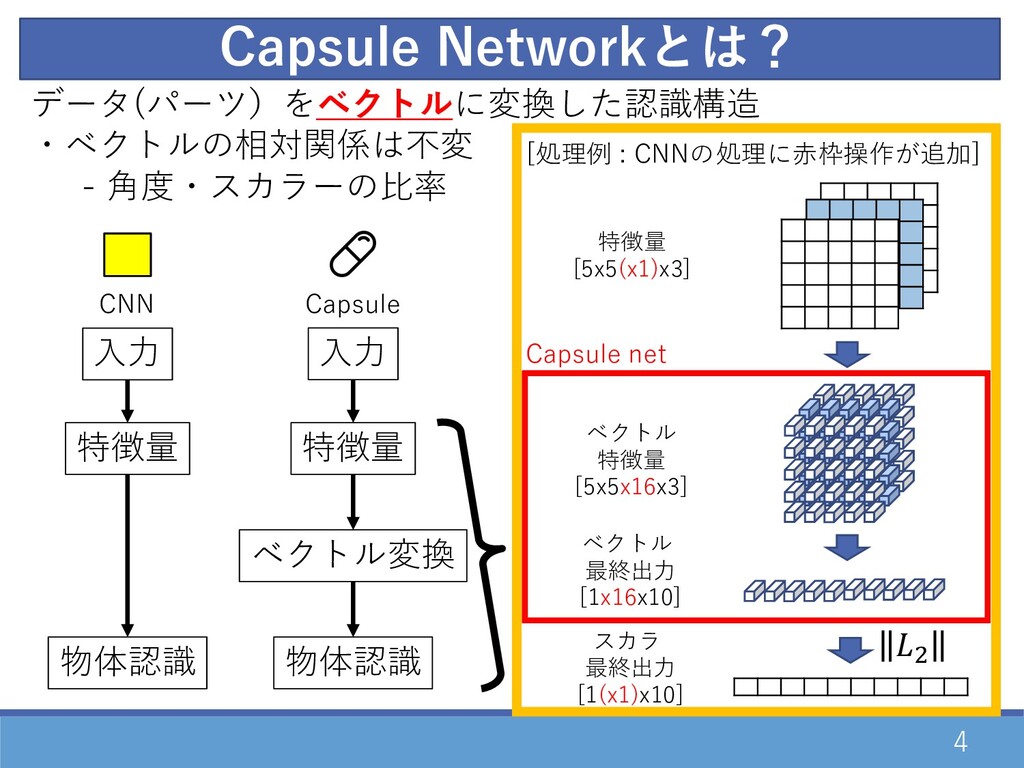
4 データ(パーツ)をベクトルに変換した認識構造 ・ベクトルの相対関係は不変 - ⾓度・スカラーの⽐率 Capsule Networkとは? ⼊⼒ ベクトル変換 物体認識
⼊⼒ 特徴量 特徴量 物体認識 Capsule CNN 特徴量 [5x5(x1)x3] ベクトル 特徴量 [5x5x16x3] ベクトル 最終出⼒ [1x16x10] スカラ 最終出⼒ [1(x1)x10] Capsule net [処理例 : CNNの処理に⾚枠操作が追加] "
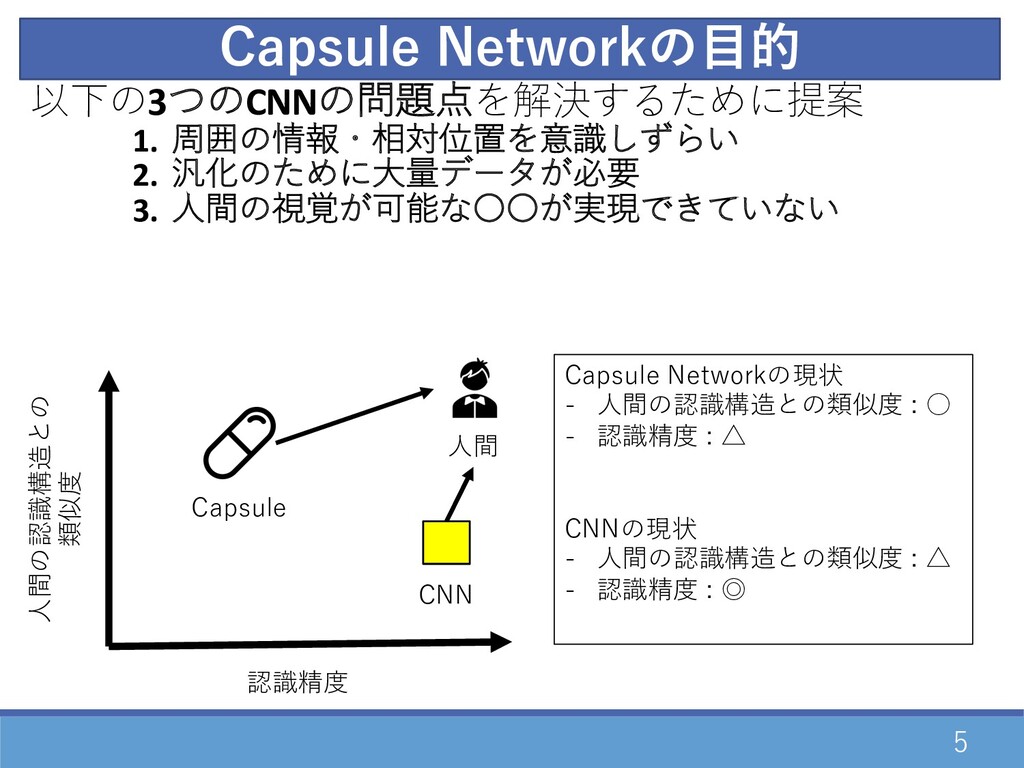
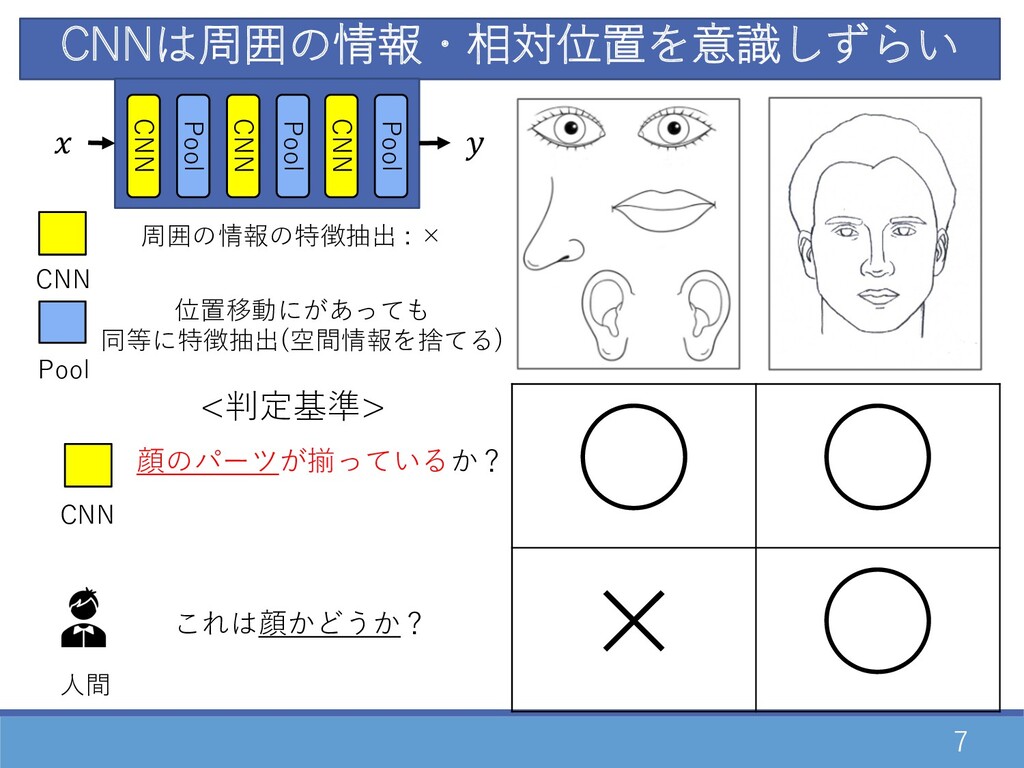
Capsule Networkの⽬的 5 以下の3つのCNNの問題点を解決するために提案 1. 周囲の情報・相対位置を意識しずらい 2. 汎化のために⼤量データが必要 3. ⼈間の視覚が可能な〇〇が実現できていない
⼈間 CNN 認識精度 ⼈間の認識構造との 類似度 Capsule Capsule Networkの現状 - ⼈間の認識構造との類似度 : ◦ - 認識精度 : △ CNNの現状 - ⼈間の認識構造との類似度 : △ - 認識精度 : ◎
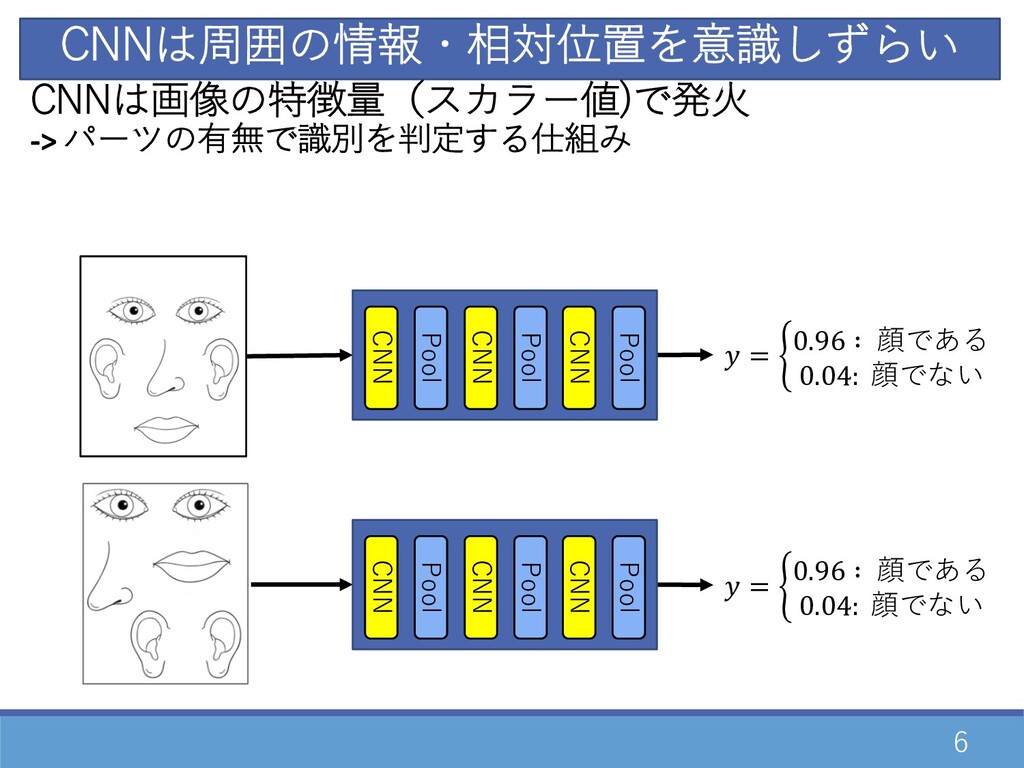
6 = % 0.96 ∶ 顔である 0.04: 顔でない CNNは周囲の情報・相対位置を意識しずらい =
% 0.96 ∶ 顔である 0.04: 顔でない CNN Pool CNN Pool CNN Pool CNN Pool CNN Pool CNN Pool CNNは画像の特徴量(スカラー値)で発⽕ -> パーツの有無で識別を判定する仕組み
7 CNN これは顔かどうか? 顔のパーツが揃っているか? ◦ ◦ × ◦ <判定基準> CNN
Pool CNN Pool CNN Pool CNN Pool 周囲の情報の特徴抽出 : × 位置移動にがあっても 同等に特徴抽出(空間情報を捨てる) CNNは周囲の情報・相対位置を意識しずらい ⼈間
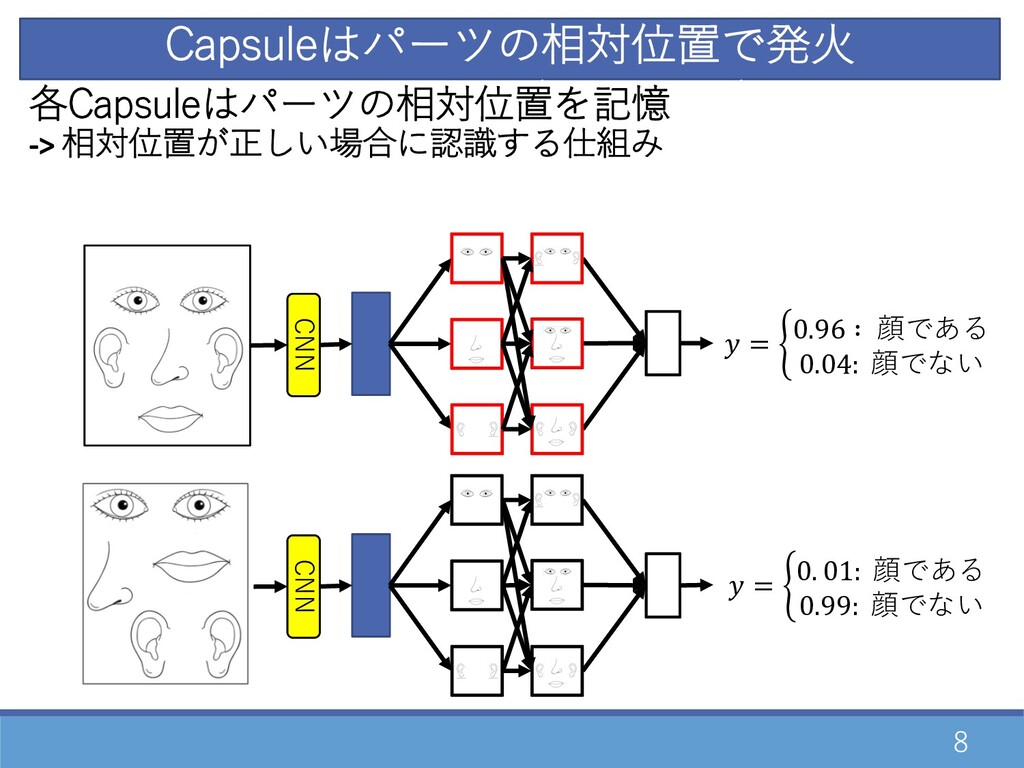
8 = % 0.96 ∶ 顔である 0.04: 顔でない Capsuleはパーツの相対位置で発⽕ =
% 0. 01: 顔である 0.99: 顔でない CNN CNN CNNは画像の特徴量(スカラー値)で発⽕ 各Capsuleはパーツの相対位置を記憶 -> 相対位置が正しい場合に認識する仕組み
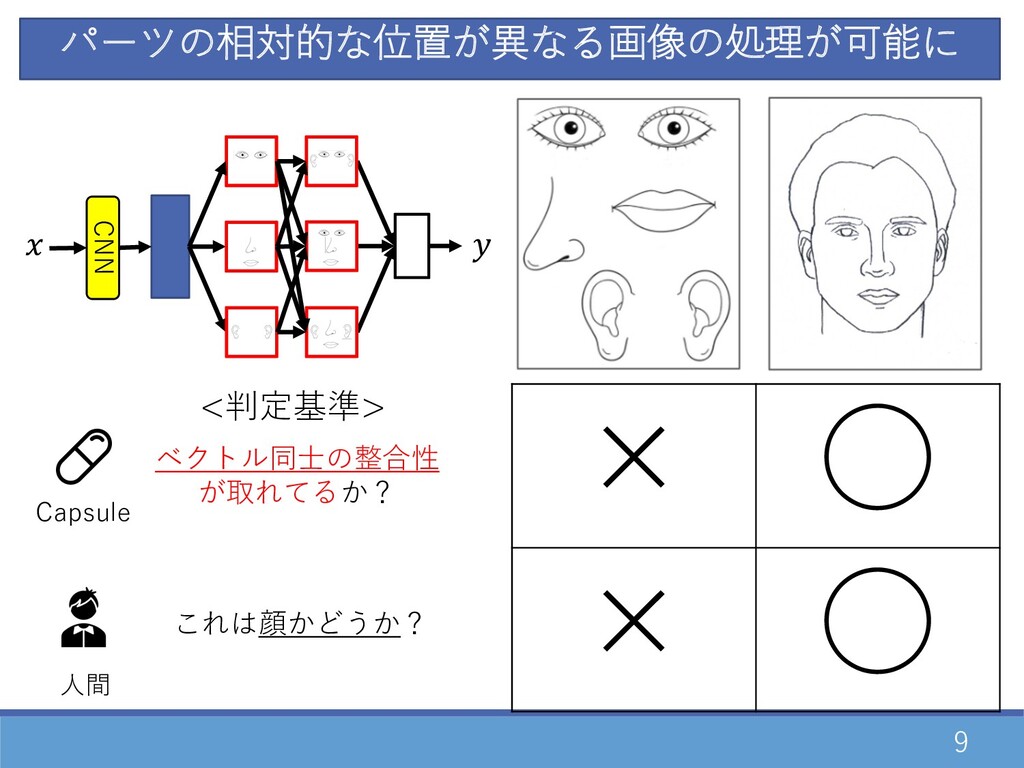
9 ⼈間 Capsule これは顔かどうか? ベクトル同⼠の整合性 が取れてるか? × ◦ × ◦
<判定基準> パーツの相対的な位置が異なる画像の処理が可能に CNN
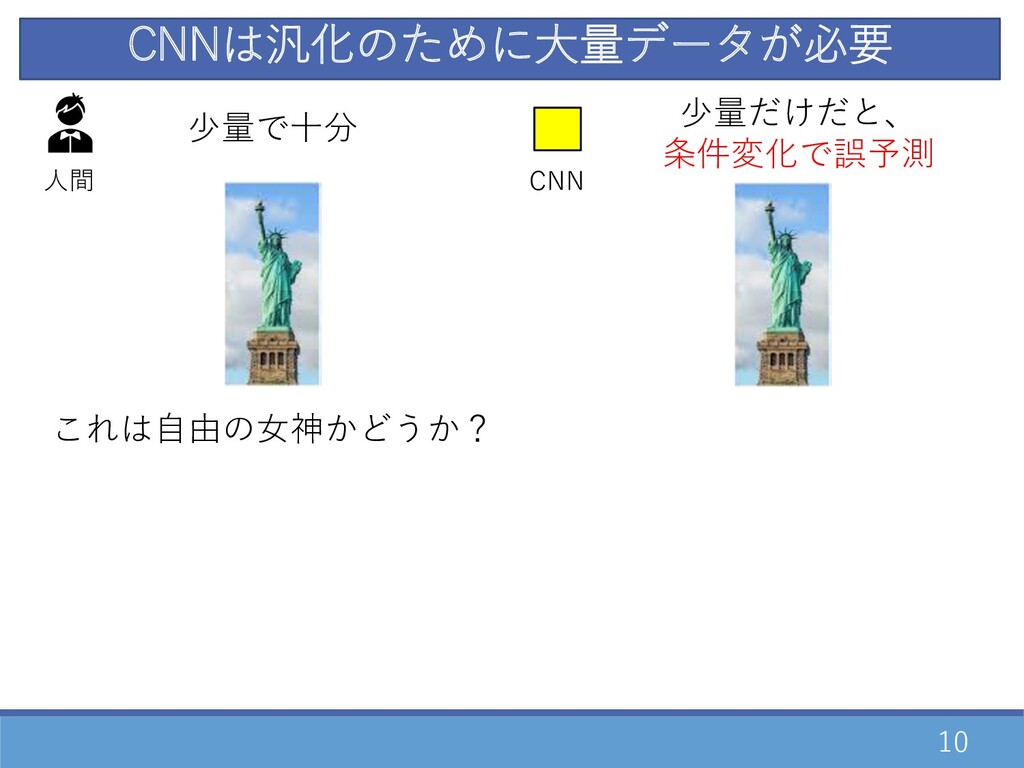
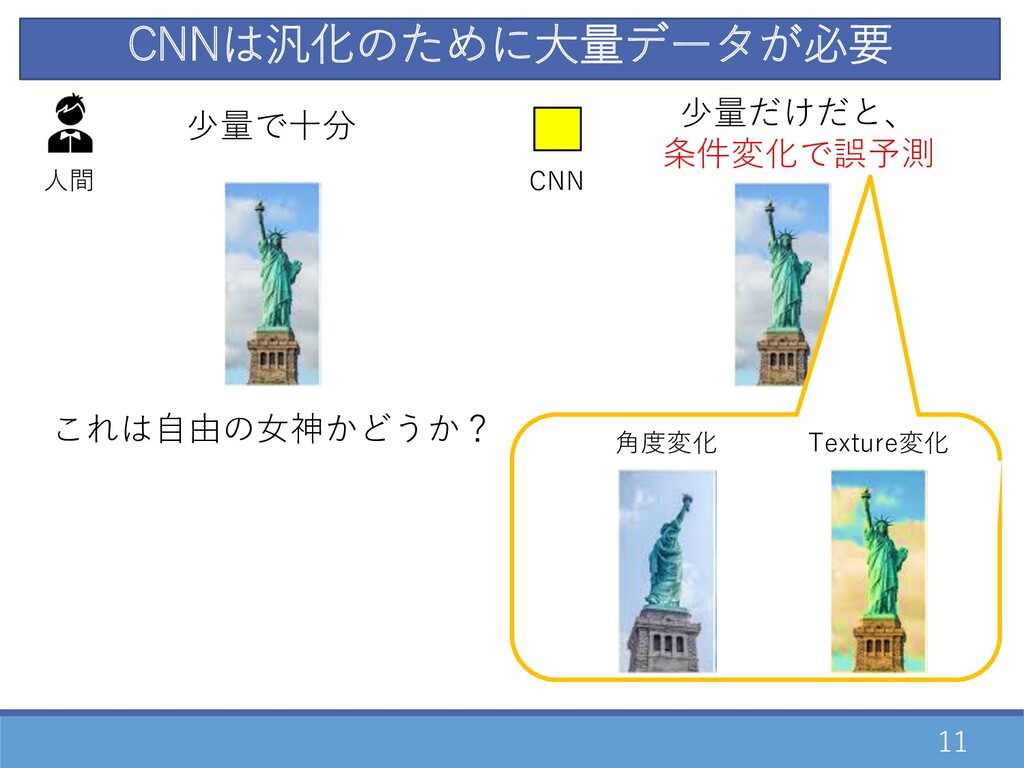
10 CNNは汎化のために⼤量データが必要 ⼈間 これは⾃由の⼥神かどうか? 少量で⼗分 CNN 少量だけだと、 条件変化で誤予測
11 CNNは汎化のために⼤量データが必要 ⼈間 これは⾃由の⼥神かどうか? 少量で⼗分 CNN 少量だけだと、 条件変化で誤予測 ⾓度変化 Texture変化
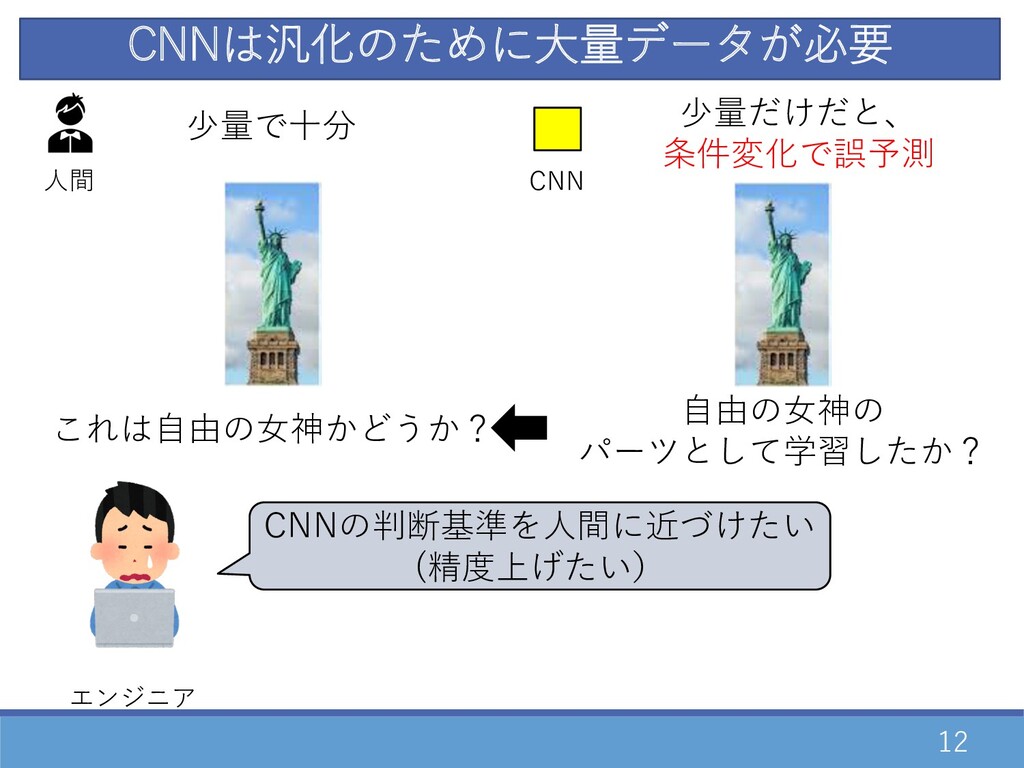
12 CNNは汎化のために⼤量データが必要 ⼈間 これは⾃由の⼥神かどうか? 少量で⼗分 CNN 少量だけだと、 条件変化で誤予測 エンジニア CNNの判断基準を⼈間に近づけたい
(精度上げたい) ⾃由の⼥神の パーツとして学習したか?
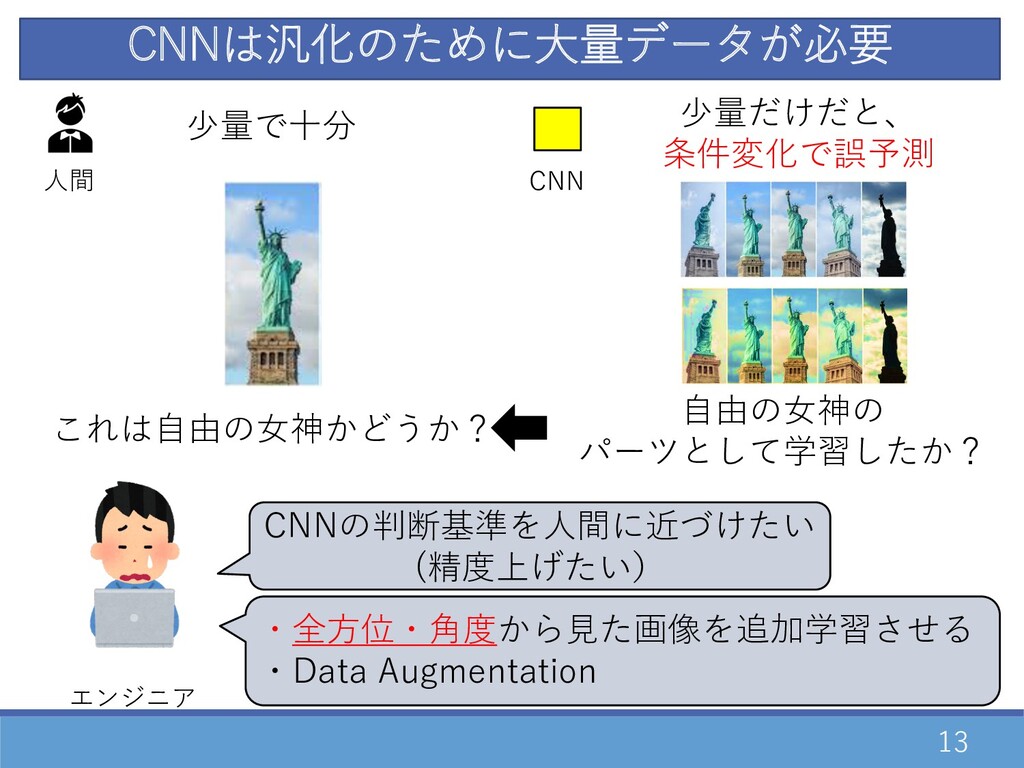
13 CNNは汎化のために⼤量データが必要 ⼈間 これは⾃由の⼥神かどうか? 少量で⼗分 CNN 少量だけだと、 条件変化で誤予測 エンジニア CNNの判断基準を⼈間に近づけたい
(精度上げたい) ⾃由の⼥神の パーツとして学習したか? ・全⽅位・⾓度から⾒た画像を追加学習させる ・Data Augmentation
14 Capsule Netは⼈間同様少量で⼗分 ⼈間 これは⾃由の⼥神かどうか? 少量で⼗分 エンジニア ⾃由の⼥神の パーツの整合性が正しいか? Capsule
少量で⼗分 Capsule Netの利⽤ → 全⽅位・⾓度の学習を追加でする必要なし *パーツの相対位置が学習済みなため
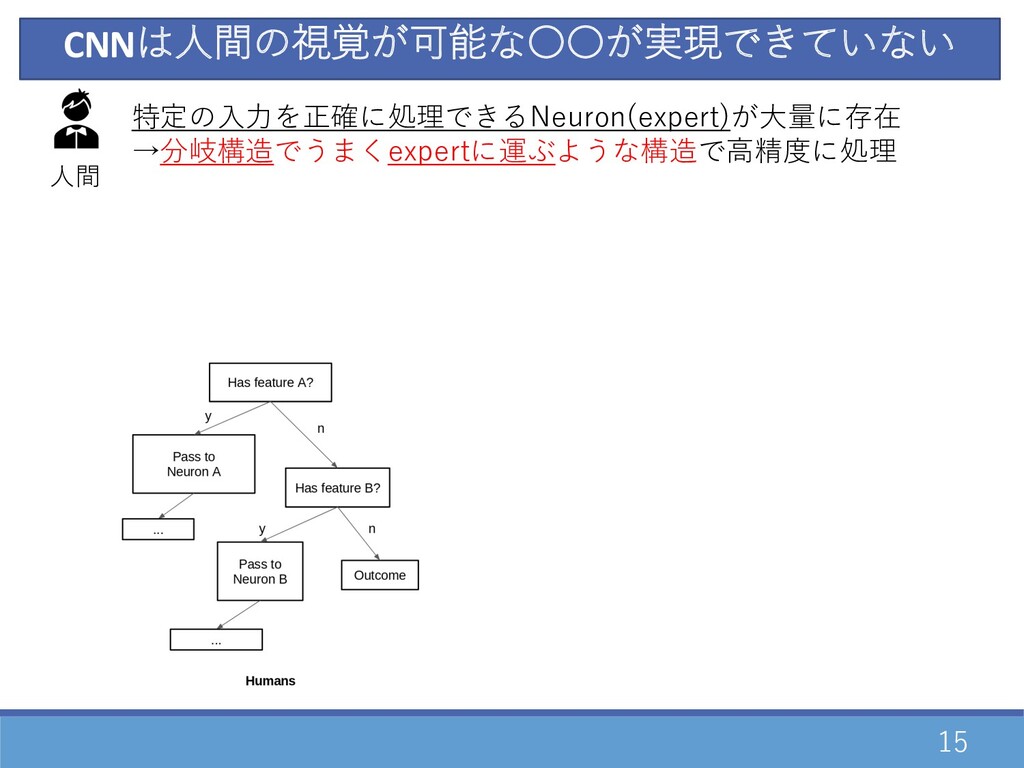
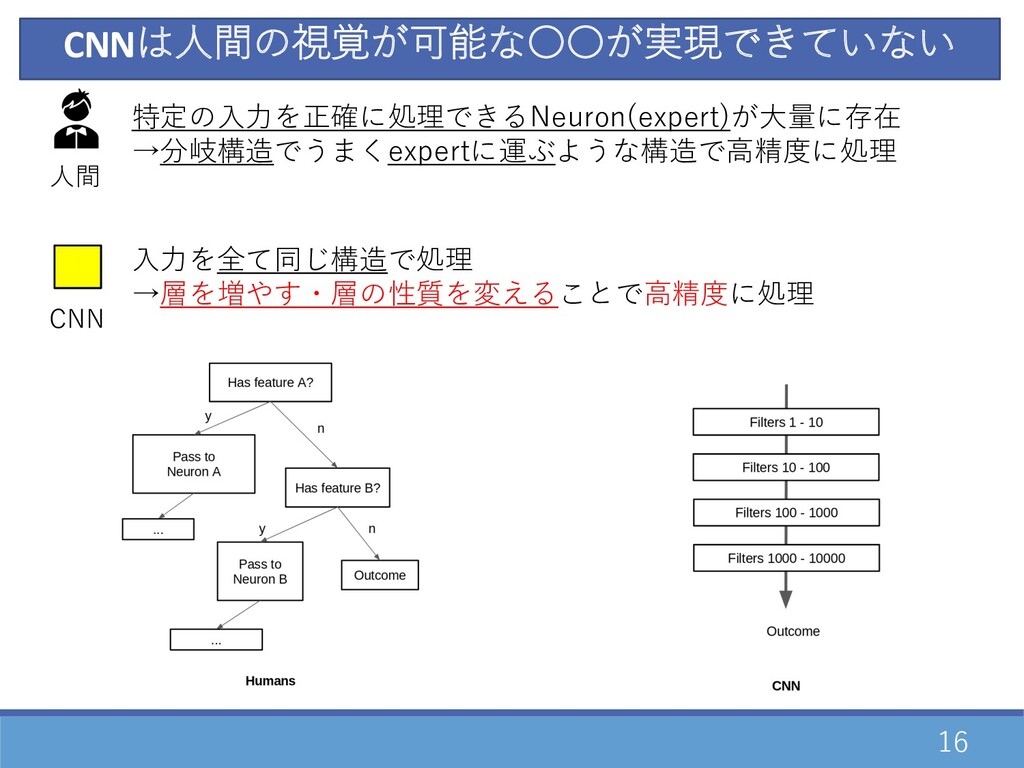
15 CNNは⼈間の視覚が可能な〇〇が実現できていない 特定の⼊⼒を正確に処理できるNeuron(expert)が⼤量に存在 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 ⼈間
16 CNNは⼈間の視覚が可能な〇〇が実現できていない 特定の⼊⼒を正確に処理できるNeuron(expert)が⼤量に存在 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 ⼈間 CNN ⼊⼒を全て同じ構造で処理 →層を増やす・層の性質を変えることで⾼精度に処理
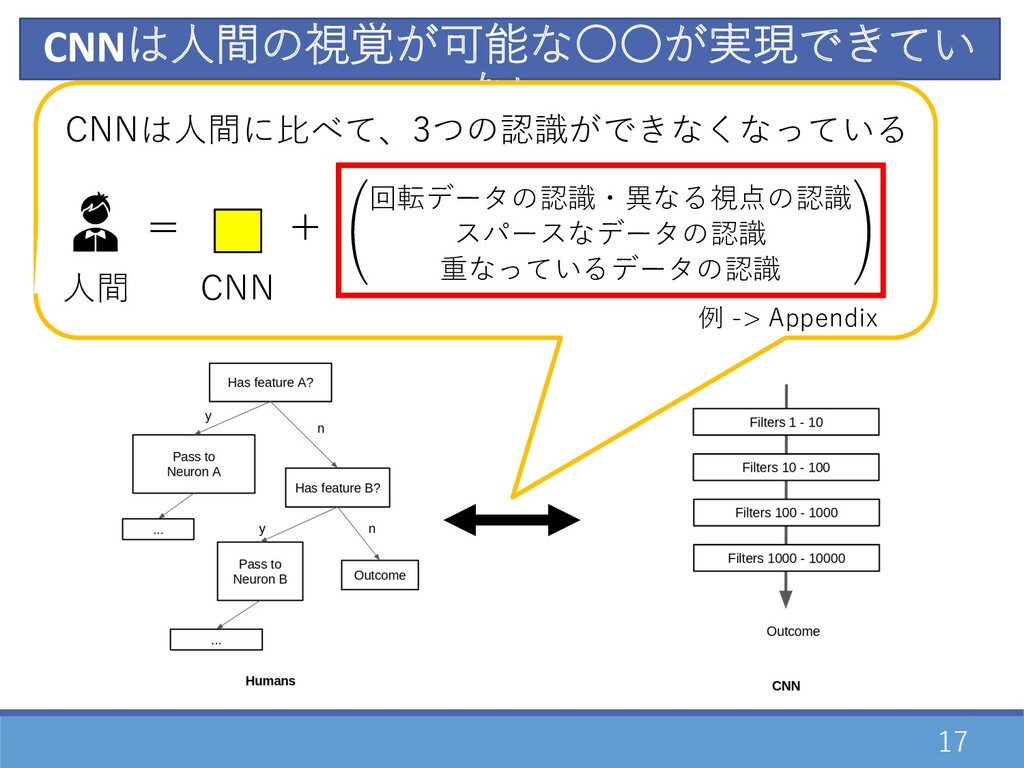
17 CNNは⼈間の視覚が可能な〇〇が実現できてい ない 特定の⼊⼒を正確に処理できるNeuron(expert)が⼤量に存在 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 ⼈間 CNN ⼊⼒を全て同じ構造で処理 →層を増やす・層の性質を変えることで⾼精度に処理 ⼈間
CNN 回転データの認識・異なる視点の認識 スパースなデータの認識 重なっているデータの認識 = + CNNは⼈間に⽐べて、3つの認識ができなくなっている 例 -> Appendix
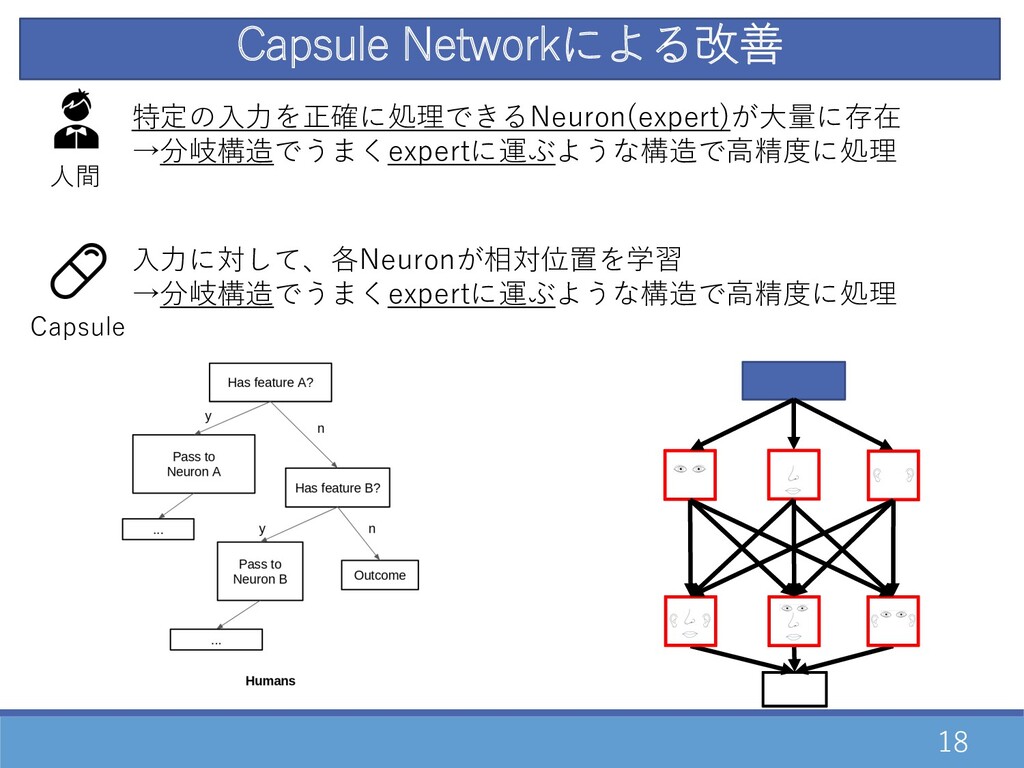
18 Capsule Networkによる改善 特定の⼊⼒を正確に処理できるNeuron(expert)が⼤量に存在 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 ⼈間 ⼊⼒に対して、各Neuronが相対位置を学習 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 Capsule
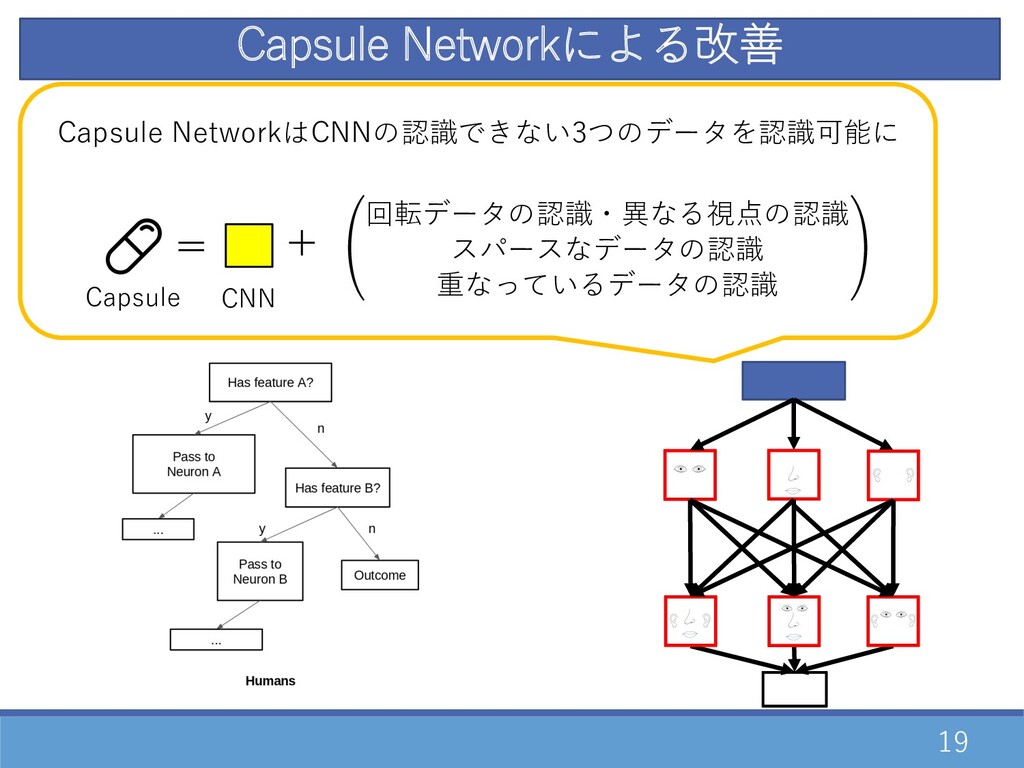
19 Capsule Networkによる改善 特定の⼊⼒を正確に処理できるNeuron(expert)が⼤量に存在 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 ⼈間 ⼊⼒に対して、各Neuronが相対位置を学習 →分岐構造でうまくexpertに運ぶような構造で⾼精度に処理 CNN 回転データの認識・異なる視点の認識
スパースなデータの認識 重なっているデータの認識 + Capsule = Capsule NetworkはCNNの認識できない3つのデータを認識可能に
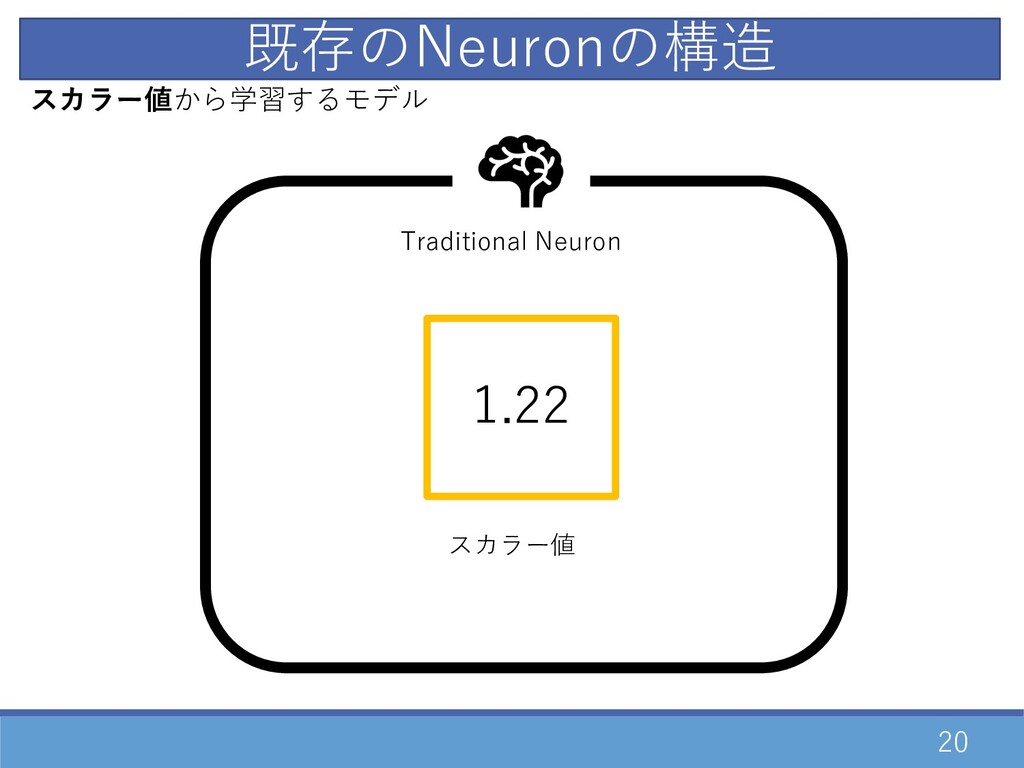
20 スカラー値から学習するモデル 既存のNeuronの構造 Traditional Neuron 1.22 スカラー値
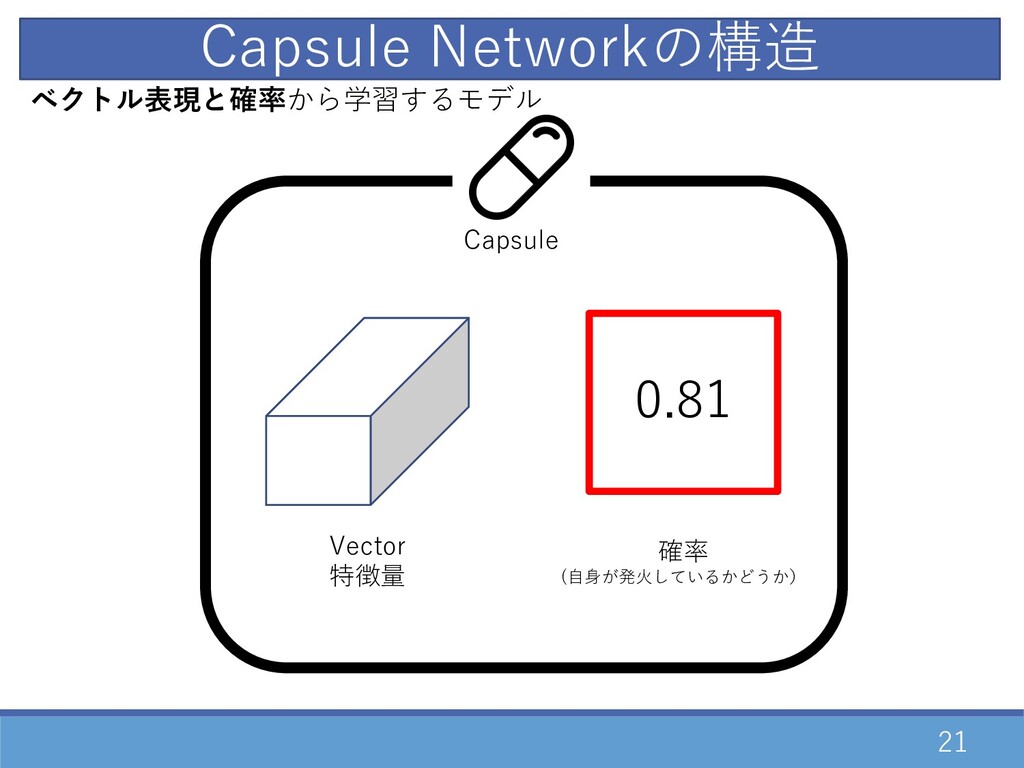
21 ベクトル表現と確率から学習するモデル Capsule Networkの構造 Capsule 0.81 Vector 特徴量 確率 (⾃⾝が発⽕しているかどうか)
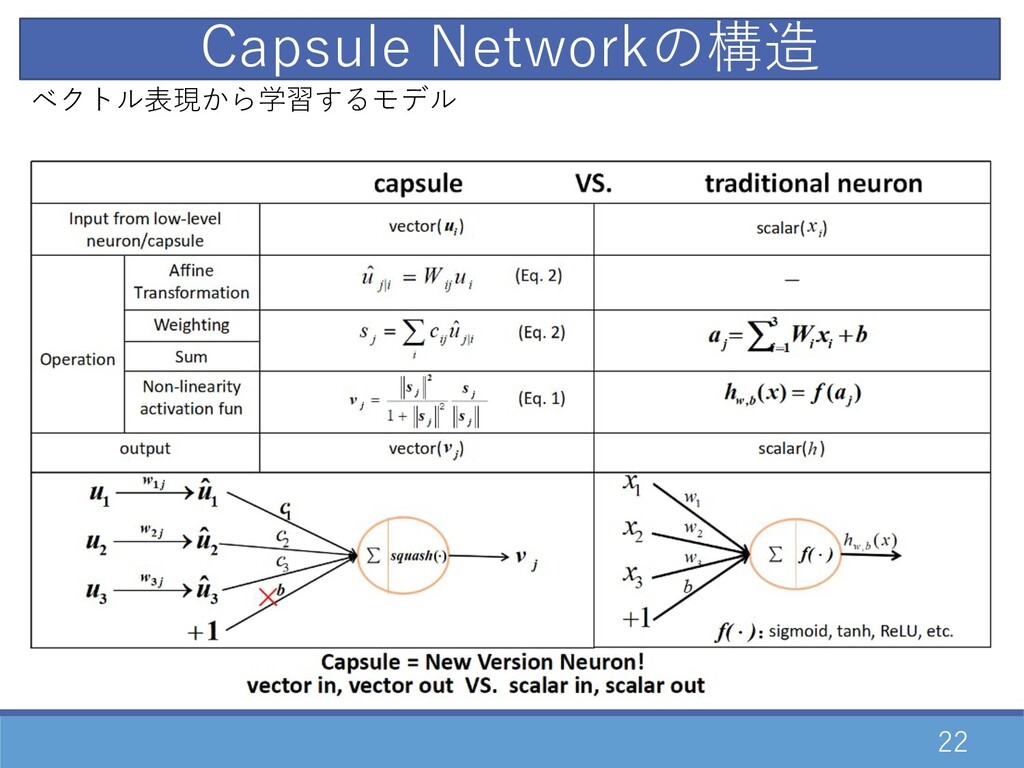
22 ベクトル表現から学習するモデル Capsule Networkの構造
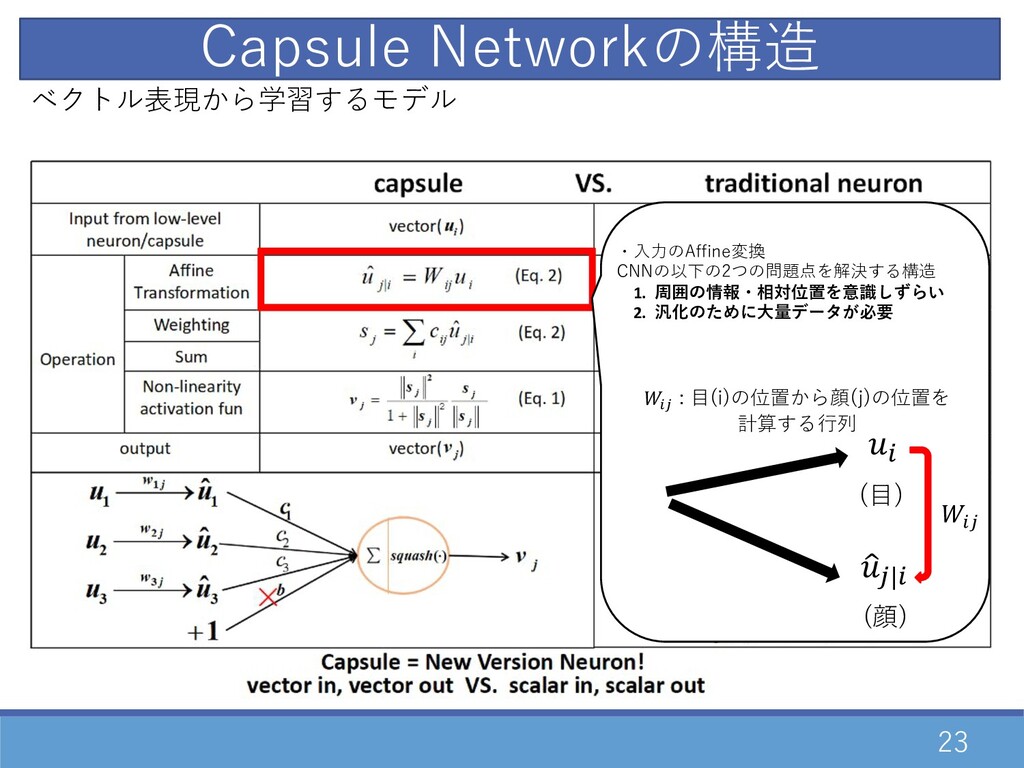
23 Capsule Networkの構造 0 1 2|0 02 (⽬) (顔) 02
: ⽬(i)の位置から顔(j)の位置を 計算する⾏列 ・⼊⼒のAffine変換 CNNの以下の2つの問題点を解決する構造 1. 周囲の情報・相対位置を意識しずらい 2. 汎化のために⼤量データが必要 ベクトル表現から学習するモデル
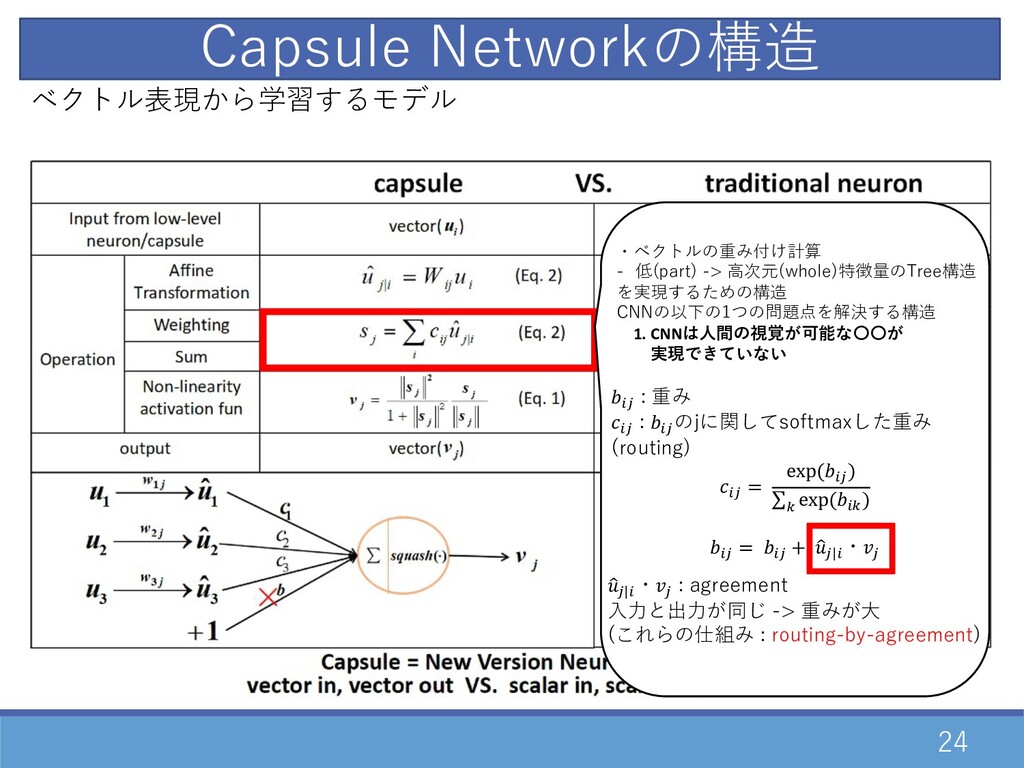
24 Capsule Networkの構造 02 : 重み 02 : 02 のjに関してsoftmaxした重み
(routing) 02 = exp(02 ) ∑= exp(0= ) 02 = 02 + 1 2|0 ・2 ・ベクトルの重み付け計算 - 低(part) -> ⾼次元(whole)特徴量のTree構造 を実現するための構造 CNNの以下の1つの問題点を解決する構造 1. CNNは⼈間の視覚が可能な〇〇が 実現できていない 1 2|0 ・2 : agreement ⼊⼒と出⼒が同じ -> 重みが⼤ (これらの仕組み : routing-by-agreement) ベクトル表現から学習するモデル
25 Capsule Networkの構造 02 : 重み 02 : 02 のjに関してsoftmaxした重み
(routing) 02 = exp(02 ) ∑= exp(0= ) 02 = 02 + 1 2|0 ・2 ・ベクトルの重み付け計算 - 低(part) -> ⾼次元(whole)特徴量のTree構造 を実現するための構造 CNNの以下の1つの問題点を解決する構造 1. CNNは⼈間の視覚が可能な〇〇が 実現できていない 1 2|0 ・2 : agreement ⼊⼒と出⼒が同じ -> 重みが⼤ (これらの仕組み : routing-by-agreement) *Routingの種類 ・Dynamic Routing (2016)(今回(右)で紹介) (routing-by-agreement) ・EM Routing(2018) ・Group Equivariant Routing(2018) ・Attention Routing(2019) and etc. Routing⼿法 / Routingの分析 : 最近の研究注⽬箇所 ベクトル表現から学習するモデル
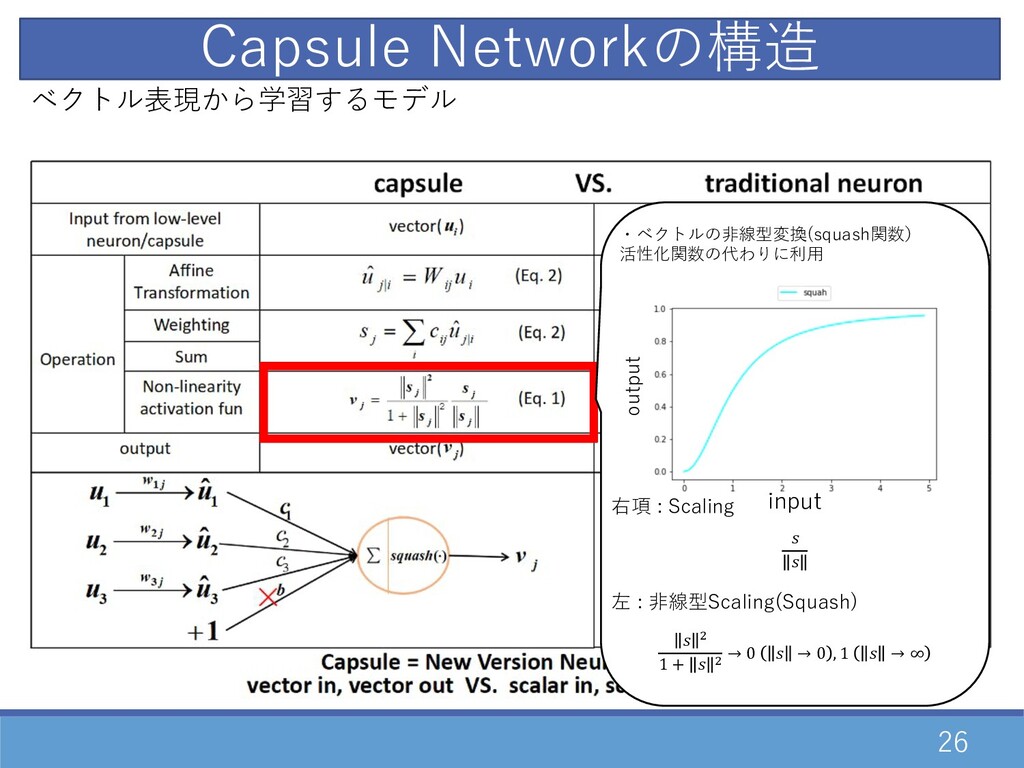
26 Capsule Networkの構造 ・ベクトルの⾮線型変換(squash関数) 活性化関数の代わりに利⽤ output input 右項 : Scaling
左 : ⾮線型Scaling(Squash) " 1 + " → 0 → 0 , 1 → ∞ ベクトル表現から学習するモデル
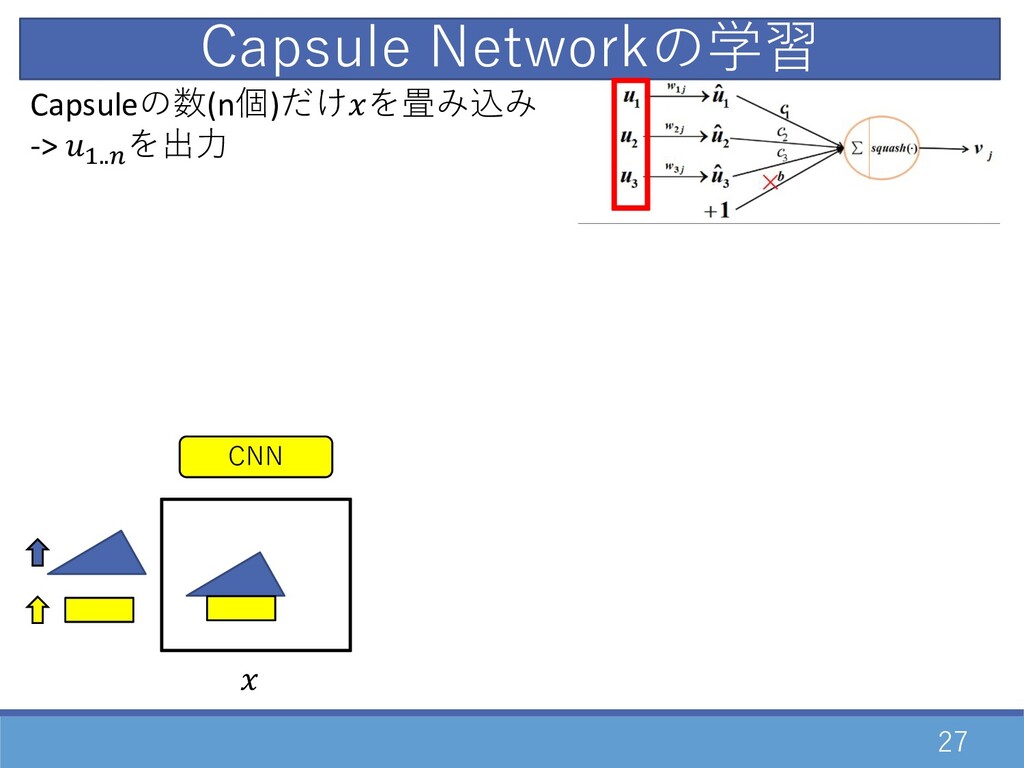
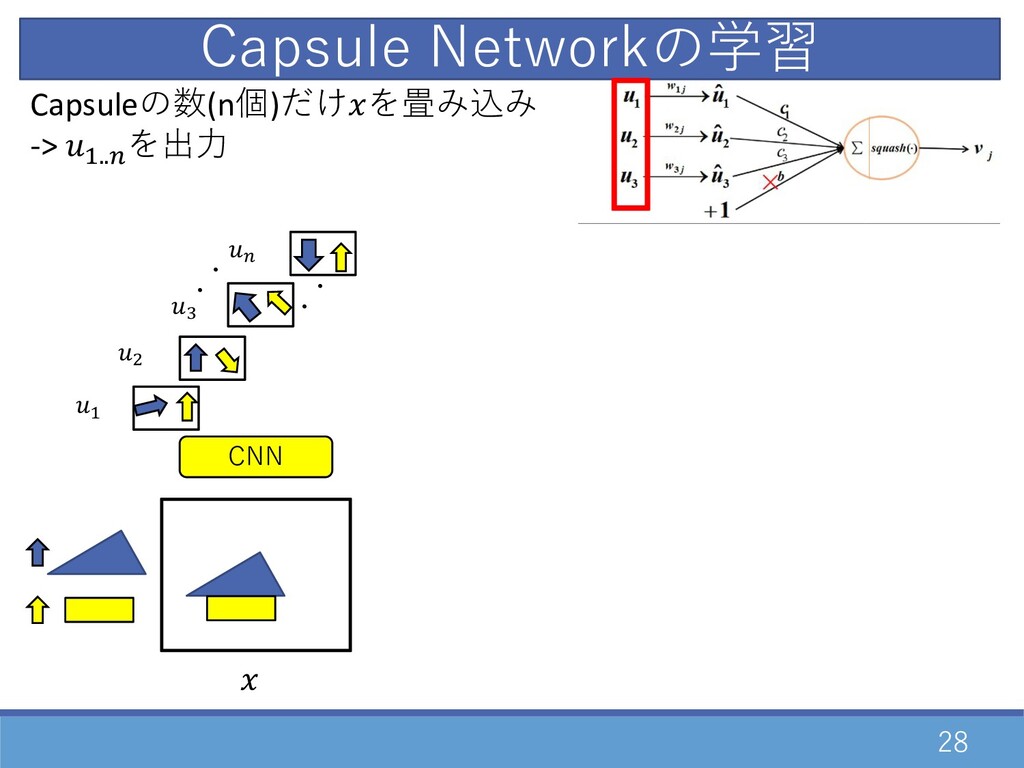
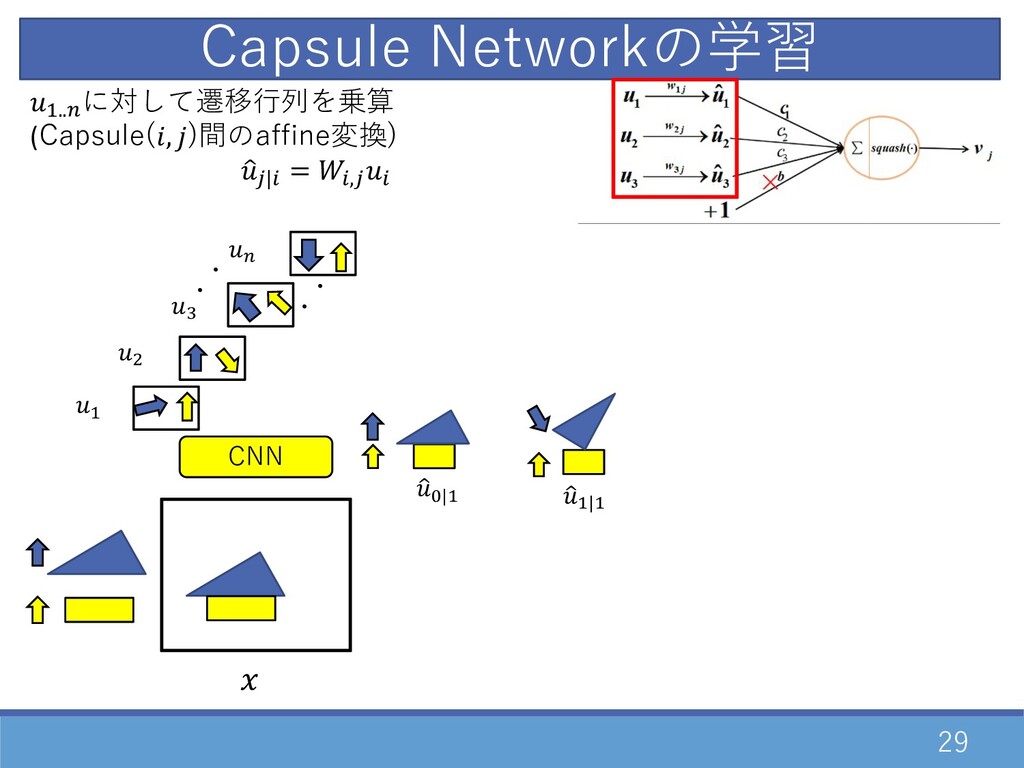
27 CNN Capsuleの数(n個)だけを畳み込み -> D..E を出⼒ Capsule Networkの学習
28 CNN Capsule Networkの学習 ・ ・ D " F E
・ ・ Capsuleの数(n個)だけを畳み込み -> D..E を出⼒
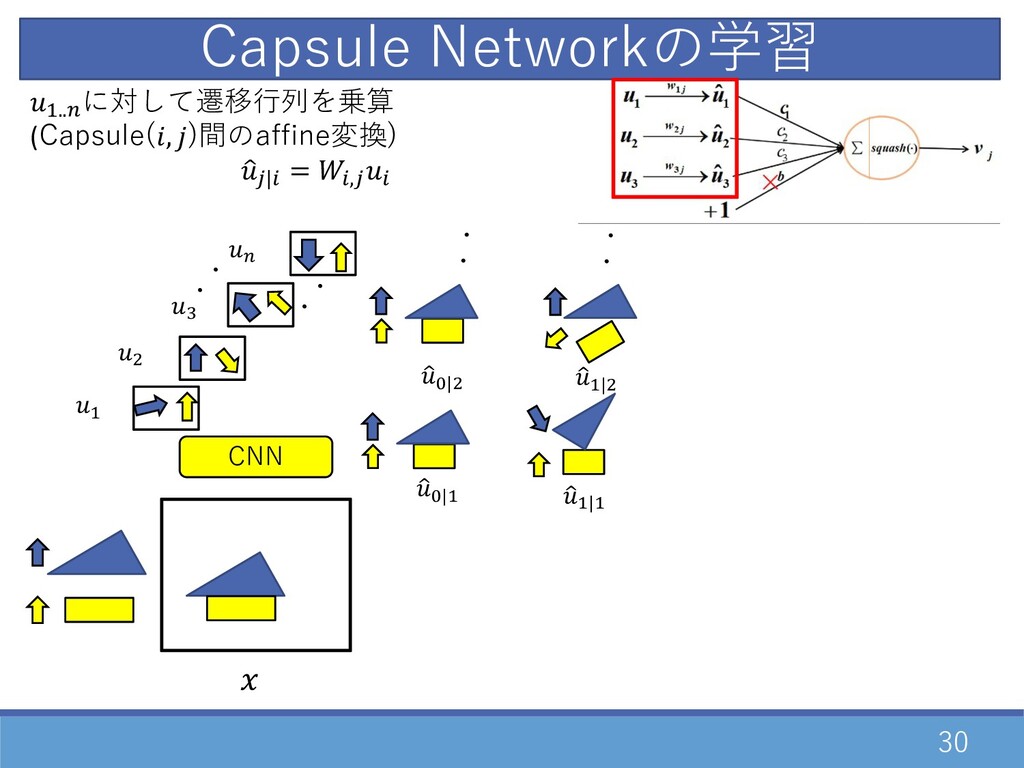
29 CNN Capsule Networkの学習 ・ ・ D " F E
・ ・ 1 G|D 1 D|D D..E に対して遷移⾏列を乗算 (Capsule(, )間のaffine変換) 1 2|0 = 0,20
30 CNN D..E に対して遷移⾏列を乗算 (Capsule(, )間のaffine変換) 1 2|0 = 0,20
Capsule Networkの学習 ・ ・ D " F E ・ ・ 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|"
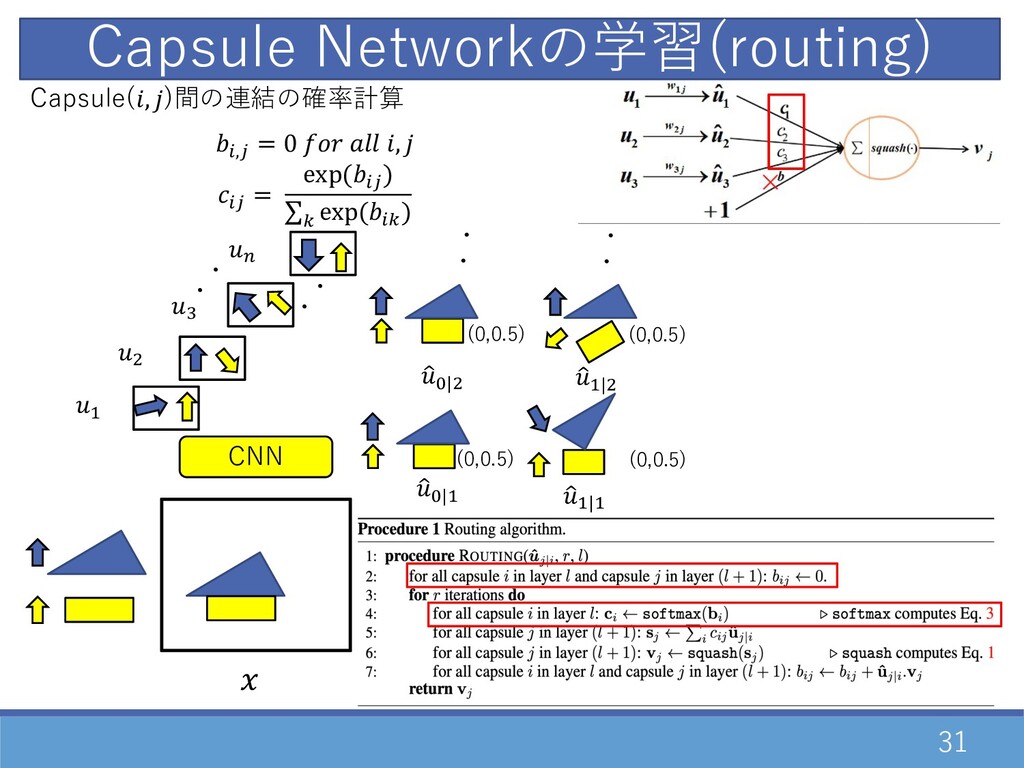
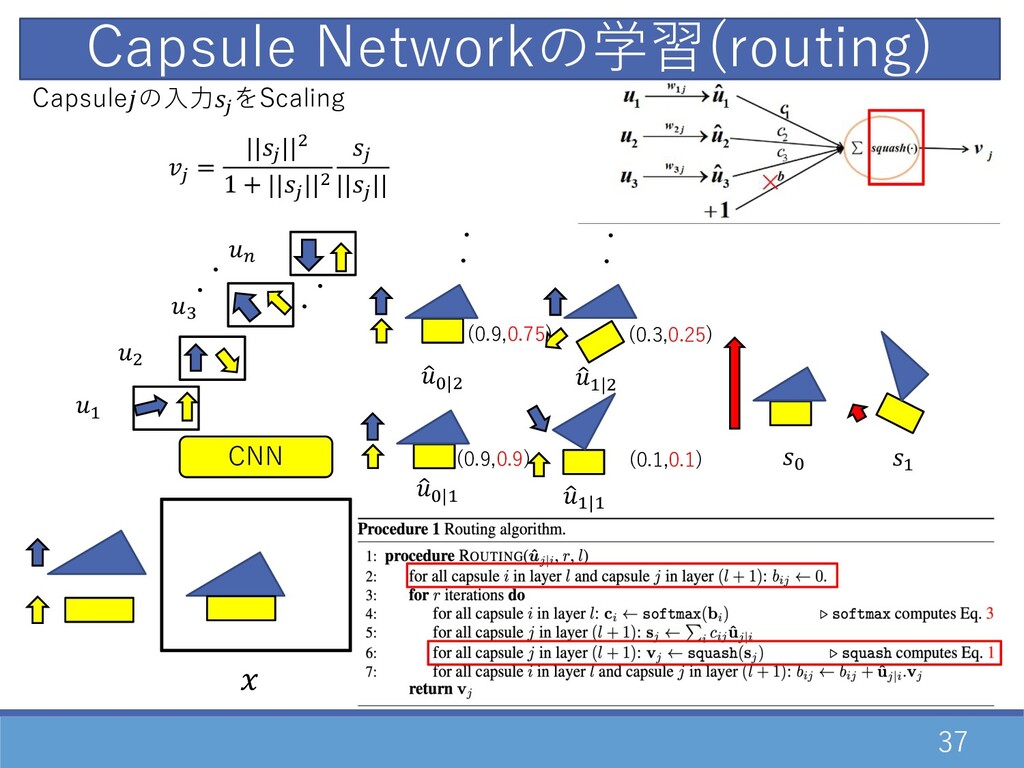
31 CNN Capsule Networkの学習(routing) ・ ・ D " F E
・ ・ Capsule(, )間の連結の確率計算 0,2 = 0 , 02 = exp(02 ) ∑= exp(0= ) 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" (0,0.5) (0,0.5) (0,0.5) (0,0.5)
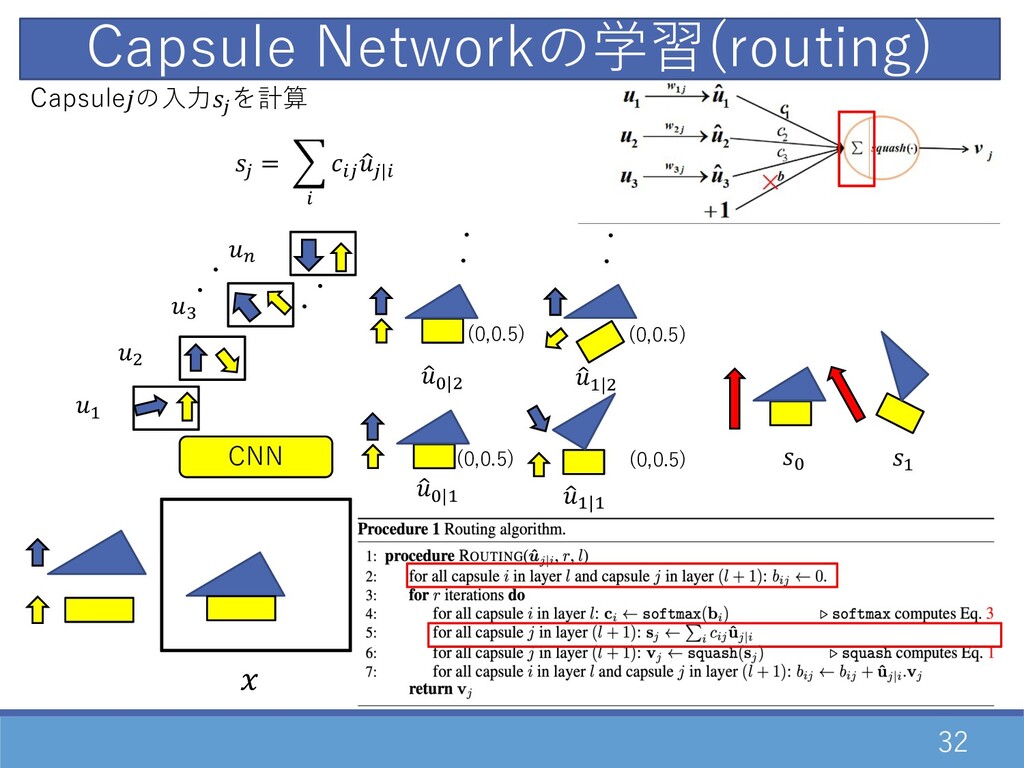
32 CNN Capsule Networkの学習(routing) ・ ・ D " F E
・ ・ Capsuleの⼊⼒2 を計算 2 = O 0 02 1 2|0 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" G D (0,0.5) (0,0.5) (0,0.5) (0,0.5)
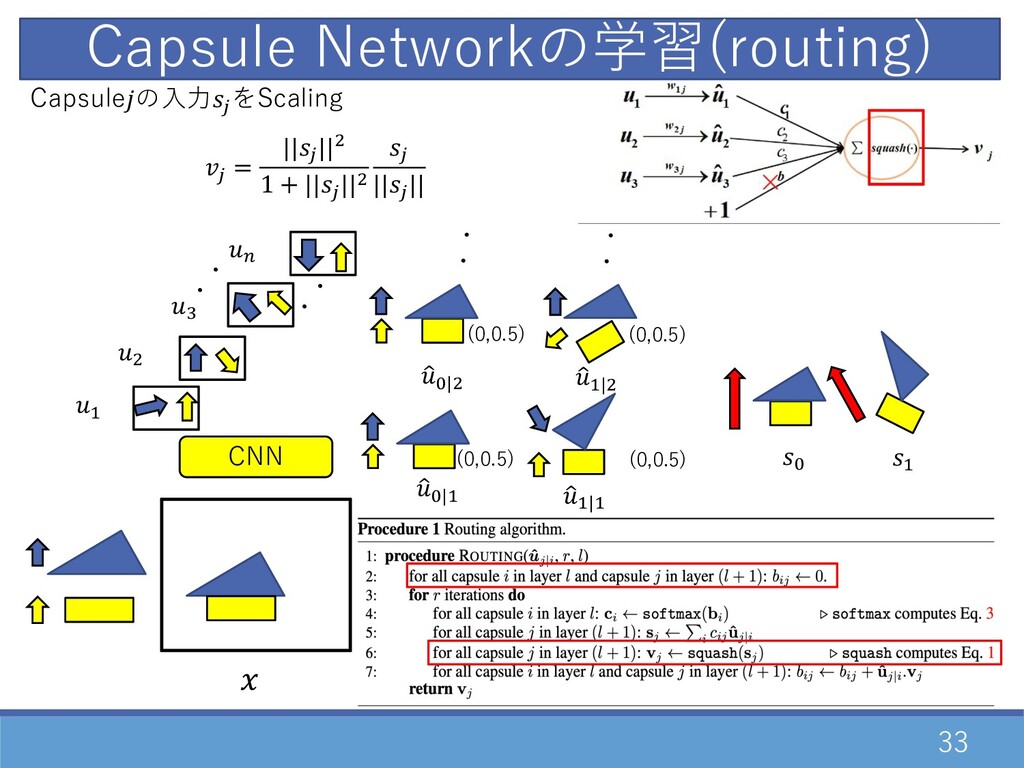
(0,0.5) 33 CNN Capsule Networkの学習(routing) ・ ・ D " F
E ・ ・ Capsuleの⼊⼒2 をScaling 2 = ||2 ||" 1 + ||2 ||" 2 ||2 || 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" G D (0,0.5) (0,0.5) (0,0.5)
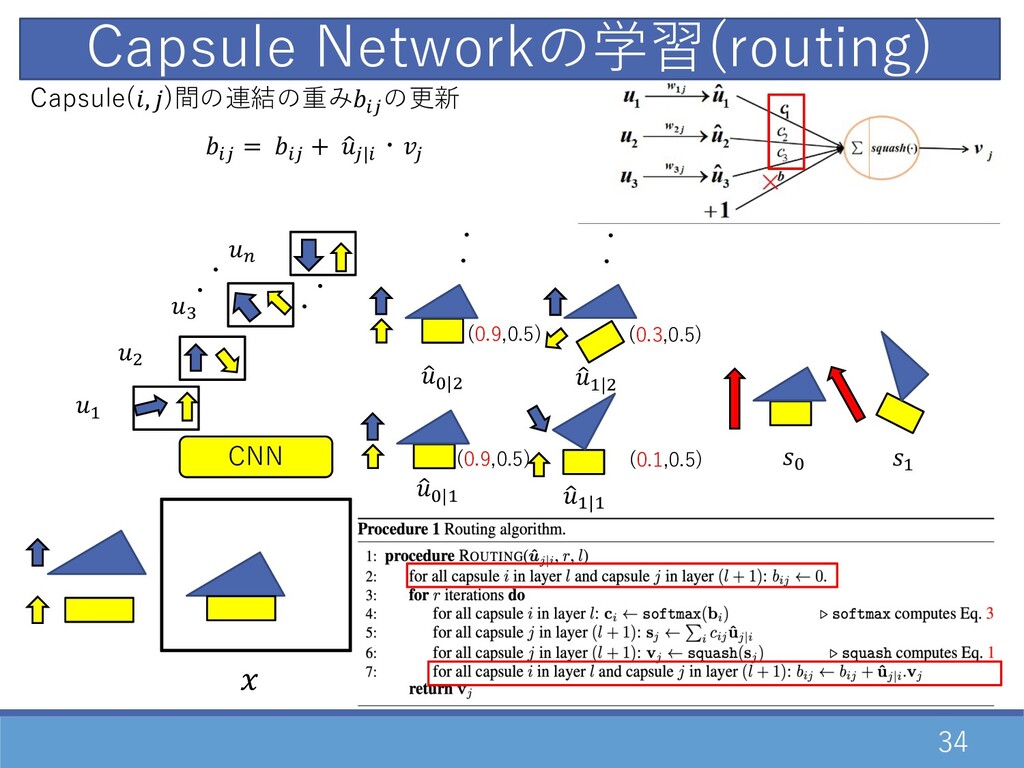
34 CNN Capsule Networkの学習(routing) ・ ・ D " F E
・ ・ Capsule(, )間の連結の重み02 の更新 02 = 02 + 1 2|0 ・2 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" G D (0.3,0.5) (0.1,0.5) (0.9,0.5) (0.9,0.5)
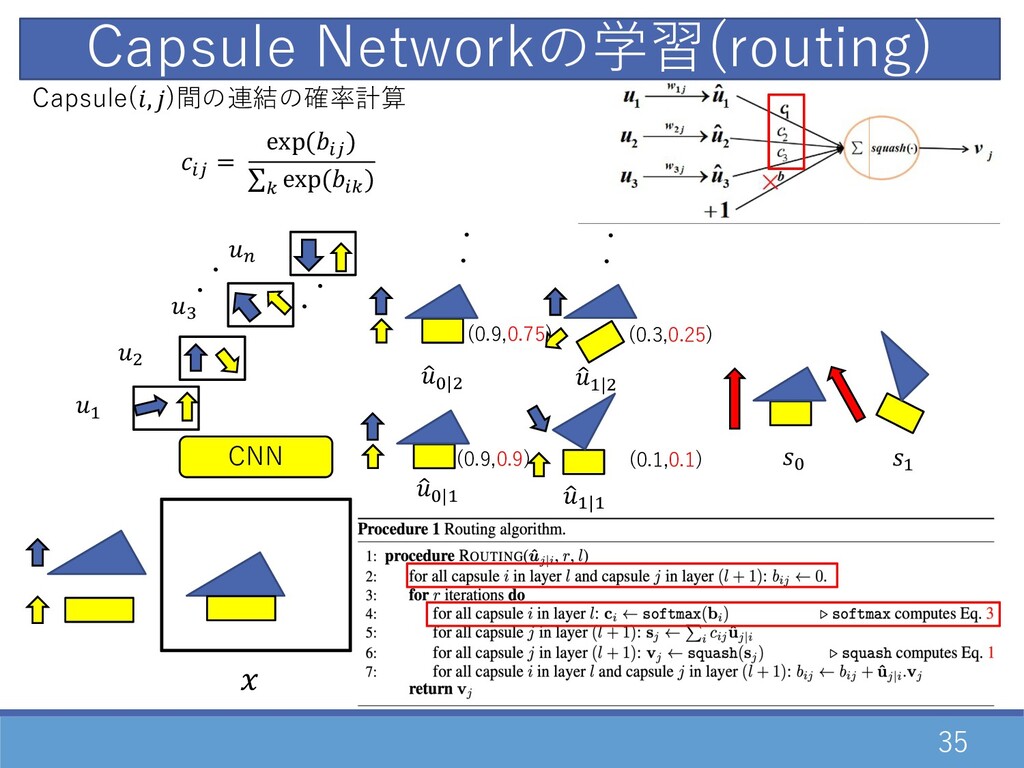
35 CNN Capsule Networkの学習(routing) ・ ・ D " F E
・ ・ 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" G D (0.3,0.25) (0.1,0.1) (0.9,0.75) (0.9,0.9) Capsule(, )間の連結の確率計算 02 = exp(02 ) ∑= exp(0= )
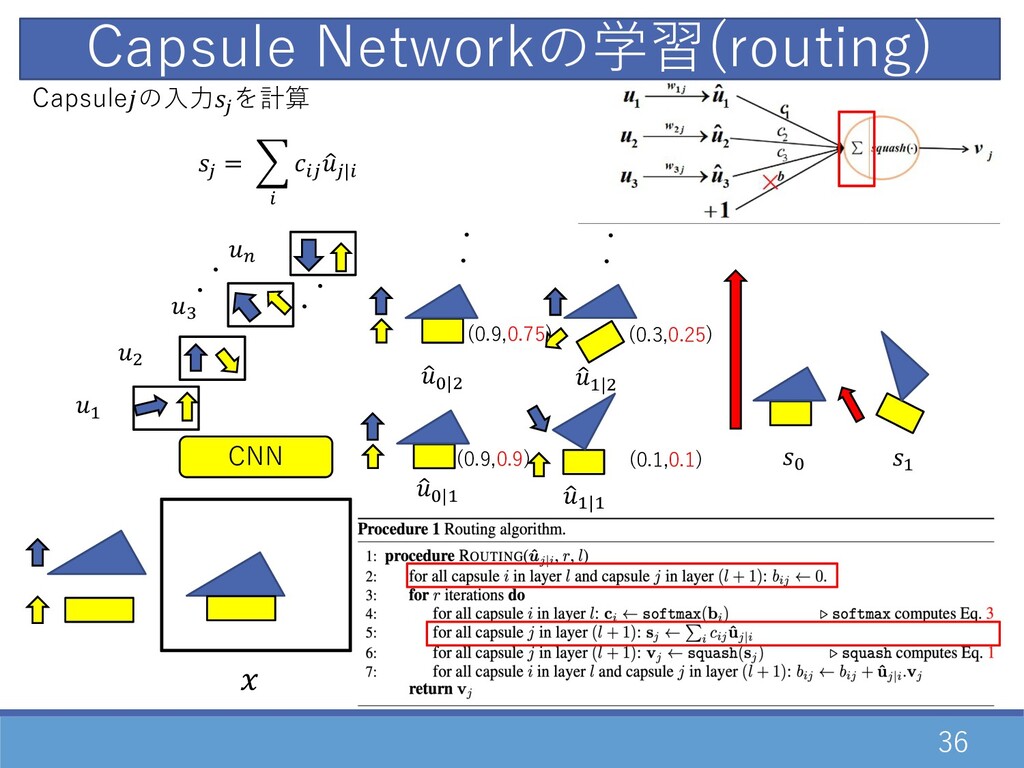
36 CNN Capsule Networkの学習(routing) ・ ・ D " F E
・ ・ 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" G D (0.3,0.25) (0.1,0.1) (0.9,0.75) (0.9,0.9) Capsuleの⼊⼒2 を計算 2 = O 0 02 1 2|0
37 CNN Capsule Networkの学習(routing) ・ ・ D " F E
・ ・ 1 G|D 1 D|D 1 G|" ・・ ・・ 1 D|" G D (0.3,0.25) (0.1,0.1) (0.9,0.75) (0.9,0.9) Capsuleの⼊⼒2 をScaling 2 = ||2 ||" 1 + ||2 ||" 2 ||2 ||
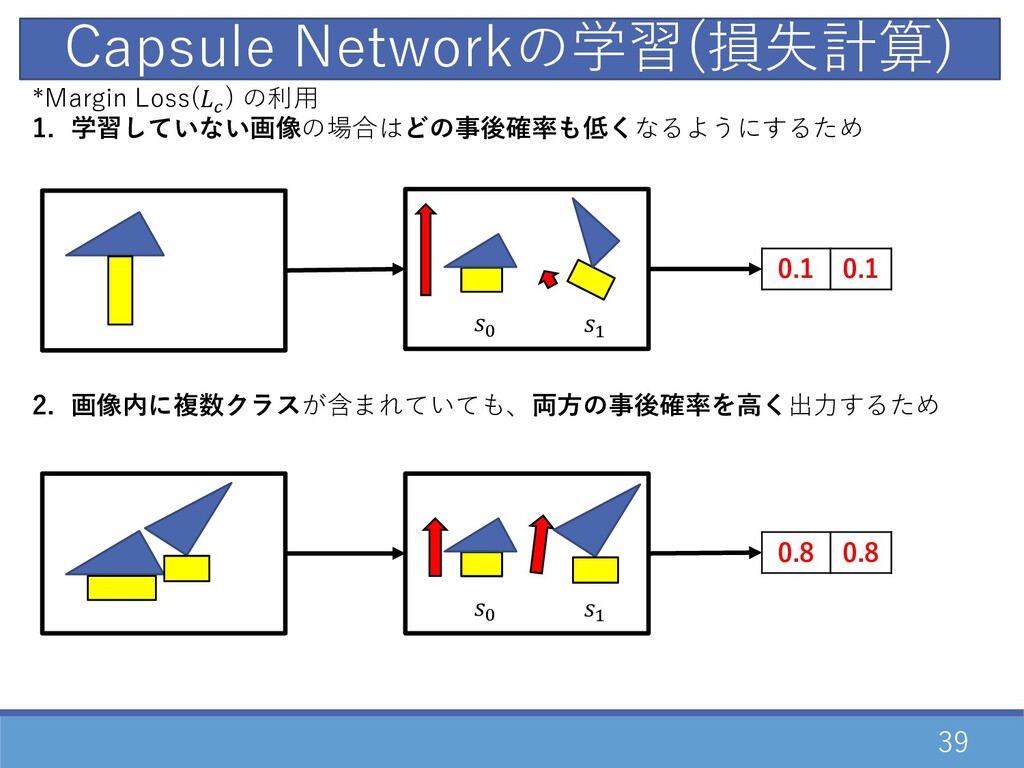
38 Capsule Networkの学習(損失計算) G D 0.9 0.1 ベクトル 最終出⼒ [1x16x2]
スカラ 最終出⼒ (P ) [1(x1)x10] " Feed Forward Neural Network ( ) Q P = P max(0, V − P )" + 1 − P max(0, P − Y)" Z = ( − Q)" 損失 : Margin Loss(P ) + 再構成誤差(Z ) (Margin Lossの学習に影響がないように、 α=0.0005 に設定) = P + αZ P % 1(正例) 0(負例) V=0.9, Y=0.1 = 0.5
39 Capsule Networkの学習(損失計算) G D 0.1 0.1 *Margin Loss(P )
の利⽤ 1. 学習していない画像の場合はどの事後確率も低くなるようにするため 2. 画像内に複数クラスが含まれていても、両⽅の事後確率を⾼く出⼒するため G D 0.8 0.8
Stacked Capsule Autoencoder Adam R. Kosiorek, Sara Sabour, Yee Whye
Teh, Geoffrey E. Hinton University of Oxford, Google Brain, DeepMind Neurips 2019
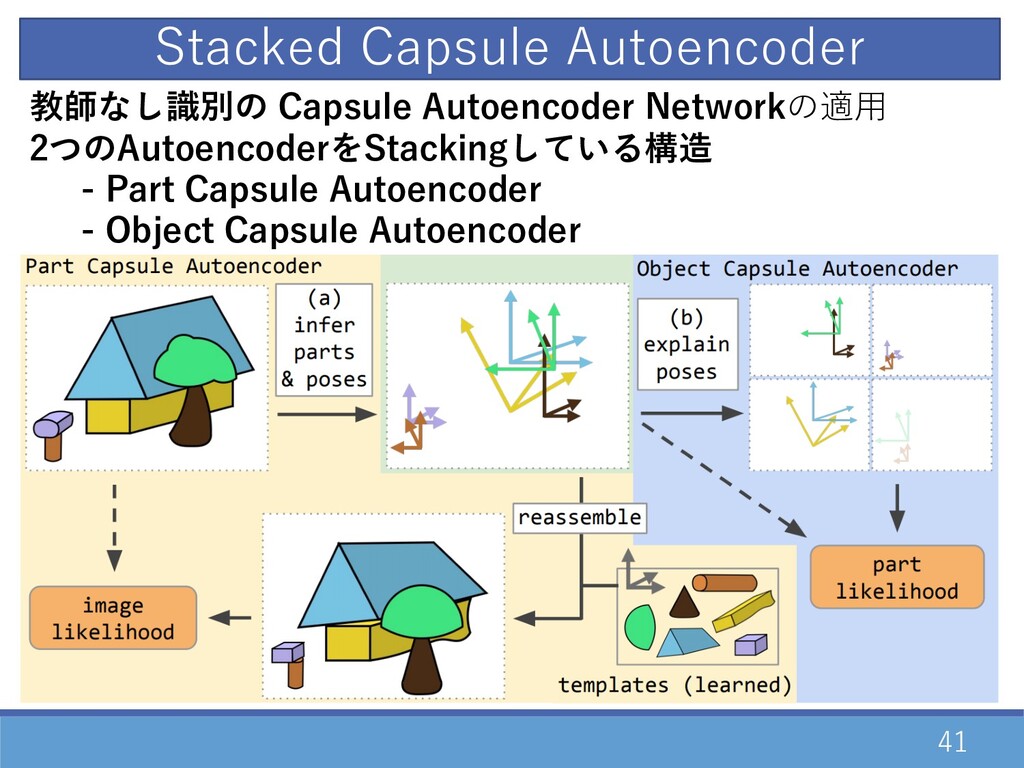
41 教師なし識別の Capsule Autoencoder Networkの適⽤ 2つのAutoencoderをStackingしている構造 - Part Capsule Autoencoder
- Object Capsule Autoencoder Stacked Capsule Autoencoder
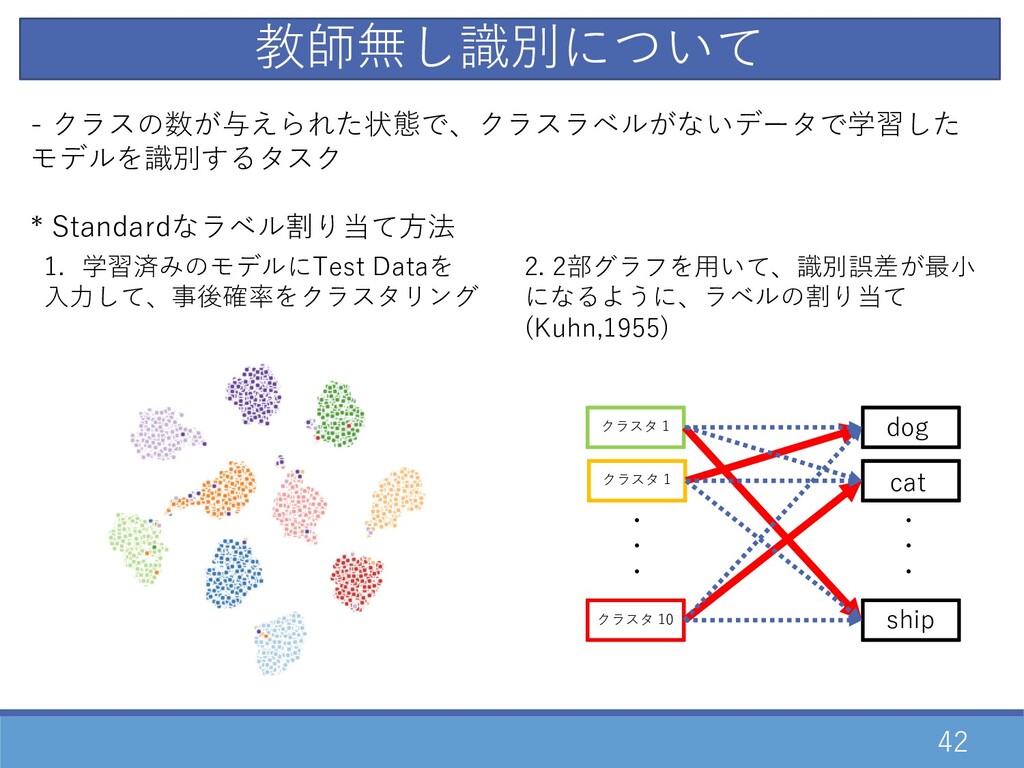
42 - クラスの数が与えられた状態で、クラスラベルがないデータで学習した モデルを識別するタスク * Standardなラベル割り当て⽅法 1. 学習済みのモデルにTest Dataを ⼊⼒して、事後確率をクラスタリング
2. 2部グラフを⽤いて、識別誤差が最⼩ になるように、ラベルの割り当て (Kuhn,1955) クラスタ 1 クラスタ 10 ・・・ ・・・ dog ship クラスタ 1 cat 教師無し識別について
43 教師なし識別は⼤きく⼆つのカテゴリに分類可能 1. Representation learning 精度がそこそこ、物体のパーツを意識しない学習法 - AIR (Eslami et
al., 2016) - SAIR (Kosiorek et al., 2018) - Iterative Variational Inference (Greff et al., 2019) - MONet (Burgess et al., 2019) - K-means (Haeusser et al., 2018) - ADC (Haeusser et al., 2018)? - IMSAT (Hu et al., 2017) 2. Target Classification (Mutual Information based) 精度がいいが、⼤量のデータが必要 - IIC(Ji et al., 2018) - DeepInfoMax(Hjelm et al., 2019) - noise-contrastive estimation(Gutmann and Hyvärinen, 2010) 関連研究
44 幾何的構造を操作するような研究 1. 精度はいいが、Affine変換(⾓度変化)に弱い - Group Equivariant Convolutional Networks (Cohen
and Welling, ICML, 2016) - Deep Roto-Translation Scattering for Object Classification (Oyallon and Mallat, CVPR, 2015) - Exploiting Cyclic Symmetry in Convolutional Neural Networks (Dieleman et al., arxiv, 2016) 2. localな変化に強いが、globalな構造変化に弱い - Spatial Transformers (Jaderberg et al., NIPS, 2015) - steerable networks (Cohen and Welling, ICRL, 2017) - Dynamic steerable blocks in deep residual networks (Jacobsen et al., arXiv, 2017) 関連研究
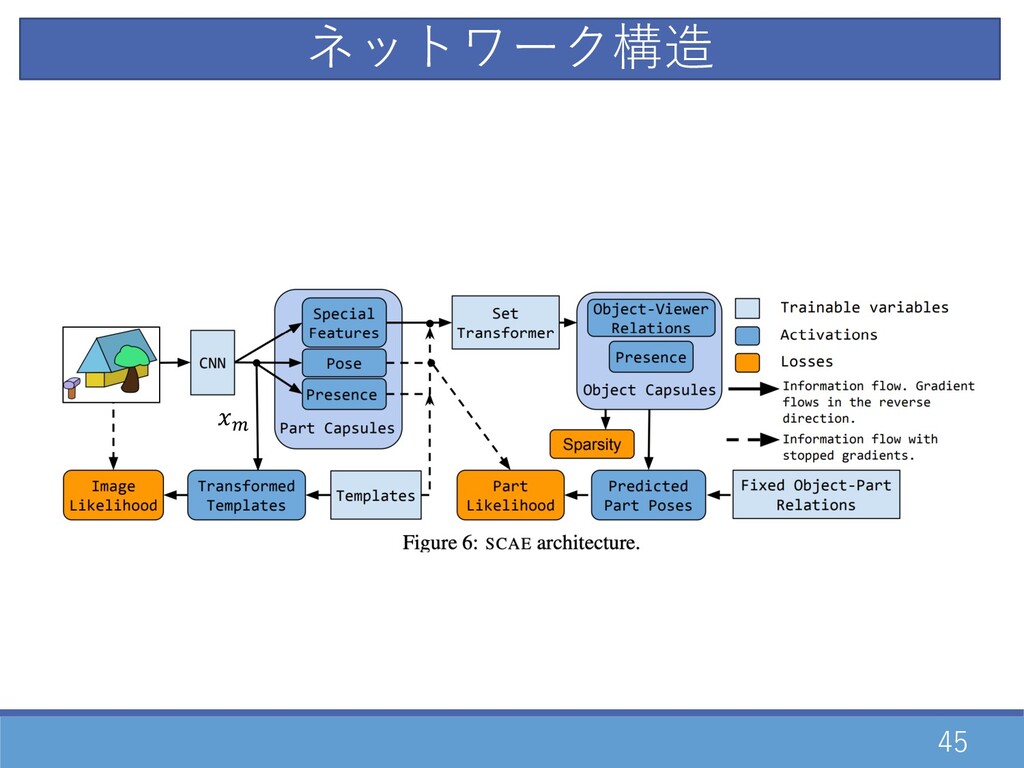
45 \ ネットワーク構造
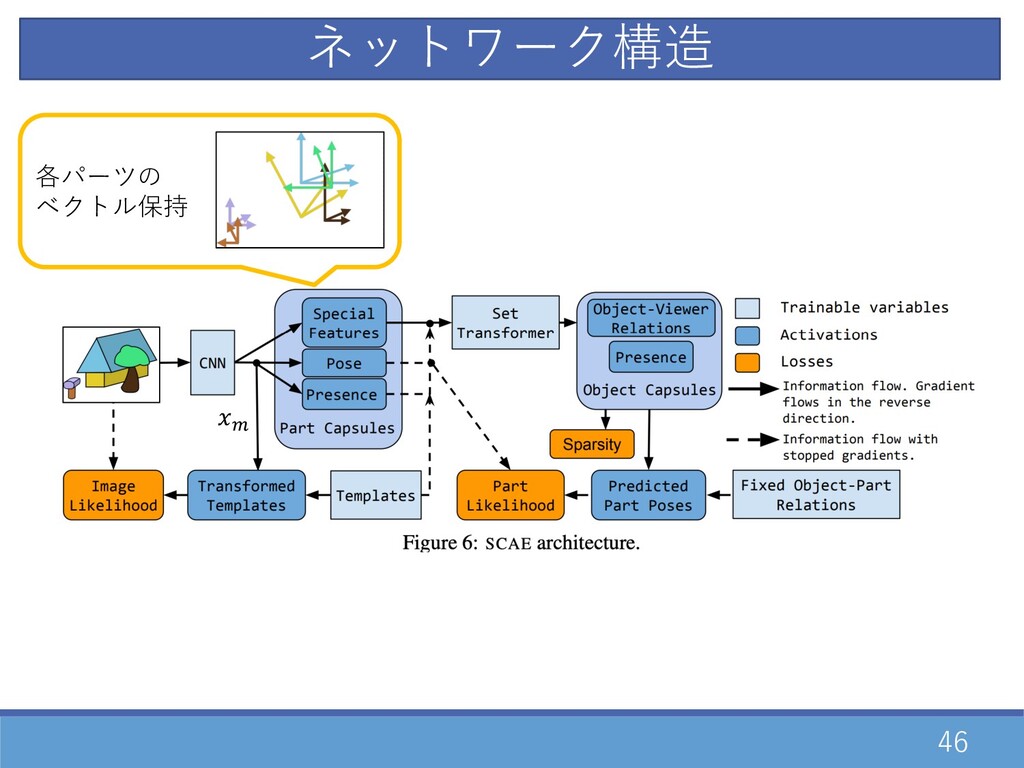
46 各パーツの ベクトル保持 \ ネットワーク構造
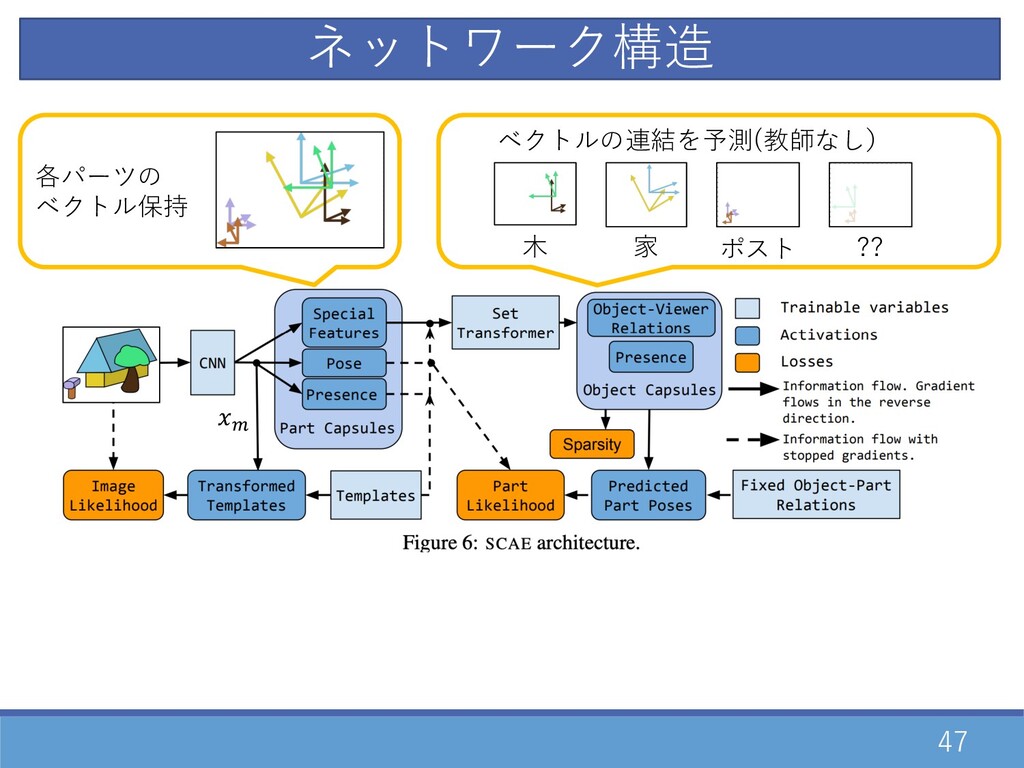
47 各パーツの ベクトル保持 ⽊ 家 ポスト ?? ベクトルの連結を予測(教師なし) \ ネットワーク構造
48 各パーツの ベクトル保持 ⽊ 家 ポスト ?? ベクトルの連結を予測(教師なし) \ ]
\ = (\ , \ ) Template(learnable)から元画像の再構成 ネットワーク構造
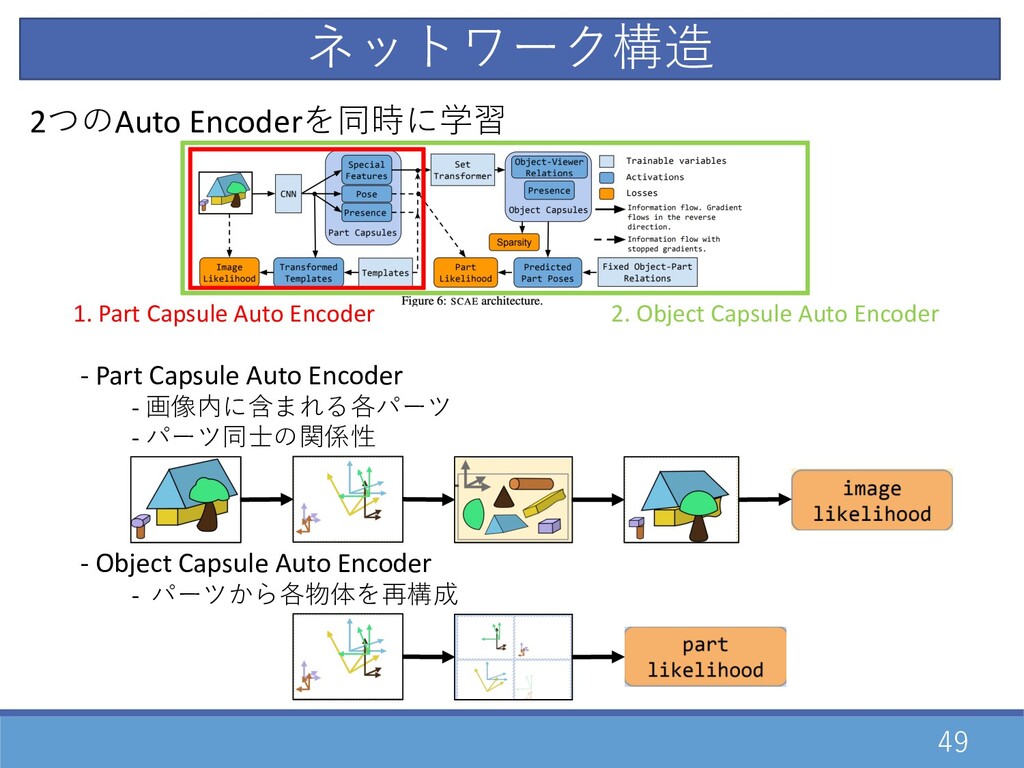
2つのAuto Encoderを同時に学習 - Part Capsule Auto Encoder - 画像内に含まれる各パーツ -
パーツ同⼠の関係性 - Object Capsule Auto Encoder - パーツから各物体を再構成 49 1. Part Capsule Auto Encoder 2. Object Capsule Auto Encoder ネットワーク構造
50 ∈ [, ]×× ⼊⼒ ∈ [0,1]n×o×Pを分解 - ポーズ集合 \
- 存在確率 \ -特徴 \ ∈ ℝPw, Part Capsule Autoencoder
51 特徴 \ ∈ ℝPw からTemplate\ ∈ [0,1]n{×o|×(PVD)の⾊を 予測 \
= (\) *実際には複雑なMappingも適⽤可能(今回は⾊予測のみに使⽤) それぞれのパーツの⾊ を予測 Part Capsule Autoencoder ∈ [, ]××
52 TemplateとPoseで 再構成 ( ) ポーズ集合 \ をTemplate(\ ∈ [0,1]n{×o{×(PVD))でアフィン変換
(画像の視点調整) * C+1 channel : color + alpha channelの⾜し合わせ (精度向上のために両⽅のchannelを使⽤) ] \ = \ ・\ Part Capsule Autoencoder ∈ [, ]××
53 TemplateとPoseで 再構成 各パーツ] E の透過率(alpha channel)に存在確率 \ を乗算 (画像の(,
)におけるパーツの存在確率) \,0,2 • ∝ \ ] \,0,2 • \,0,2 • Part Capsule Autoencoder ∈ [, ]××
54 TemplateとPoseで 再構成 画像の尤度のGMMで計算 - \ ‚ ] \,0,2 P
: 推定した⾊・Templateのcolor channel - • " : ⼊⼒画像の分散 = „ 0,2 O \…D † \,0,2 • 0,2 \ ‚ ] \,0,2 P ; • ") ] \,0,2 P \,0,2 • Part Capsule Autoencoder ∈ [, ]××
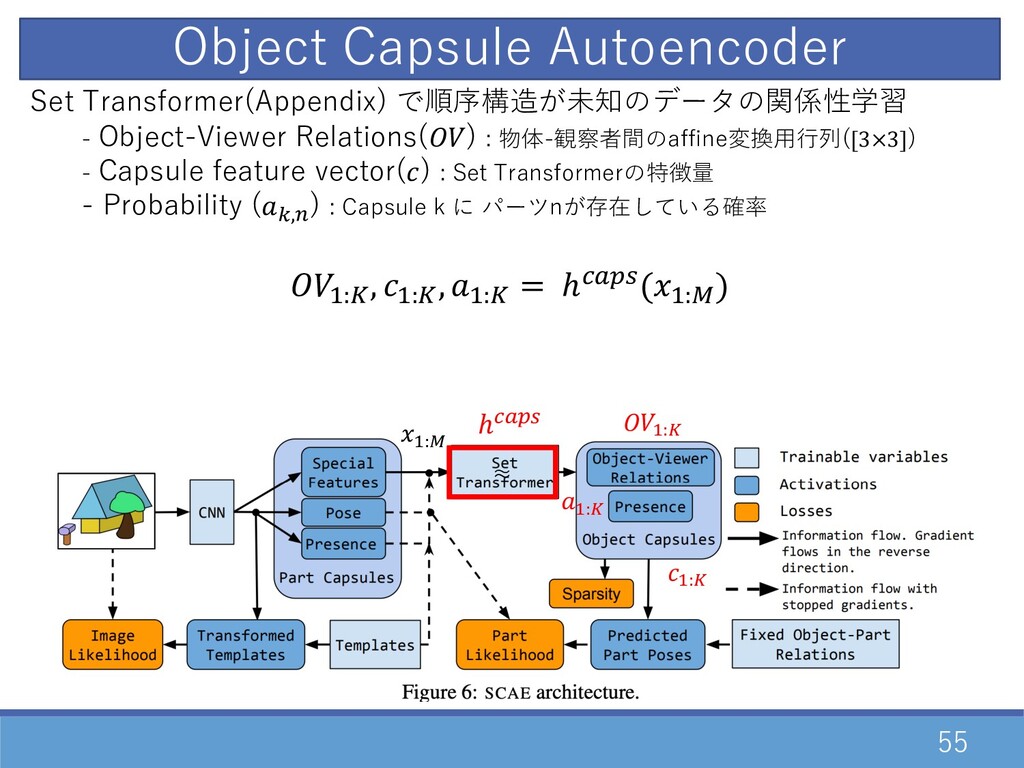
55 D:† ℎP•Š‹ Set Transformer(Appendix) で順序構造が未知のデータの関係性学習 - Object-Viewer Relations() :
物体-観察者間のaffine変換⽤⾏列([3×3]) - Capsule feature vector() : Set Transformerの特徴量 - Probability (=,E ) : Capsule k に パーツnが存在している確率 D:•, D:•, D:• = ℎP•Š‹(D:†) D:• D:• ≈ D:• Object Capsule Autoencoder
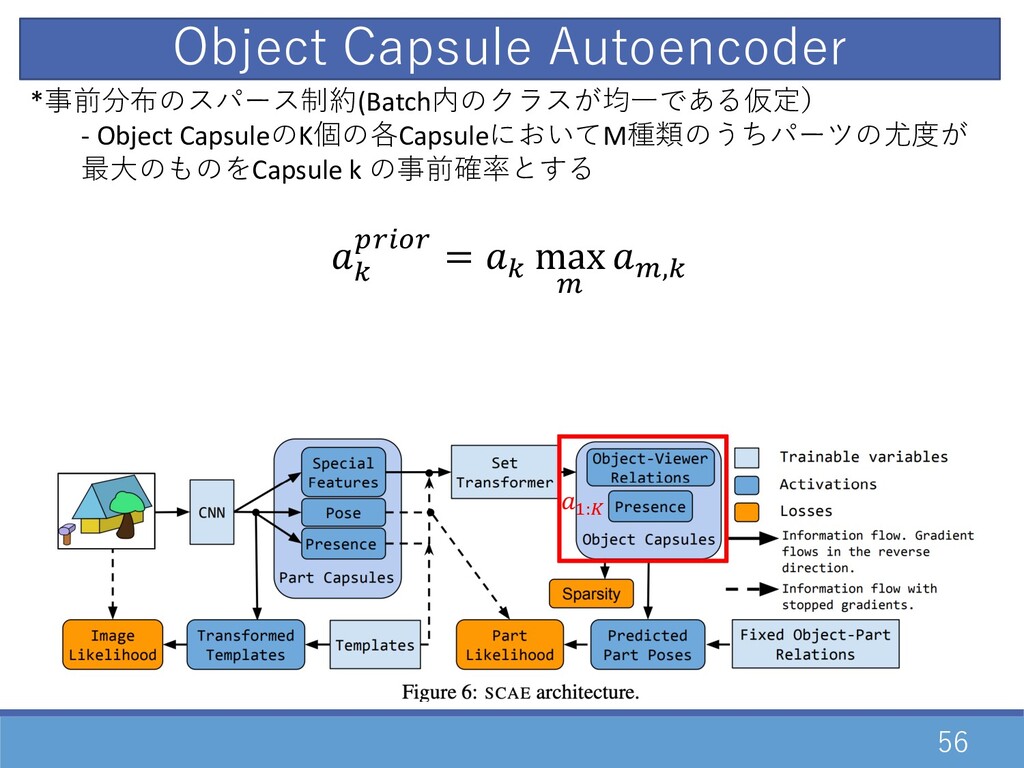
56 *事前分布のスパース制約(Batch内のクラスが均⼀である仮定) - Object CapsuleのK個の各CapsuleにおいてM種類のうちパーツの尤度が 最⼤のものをCapsule k の事前確率とする = ŠZ0•Z
= = max \ \,= D:• Object Capsule Autoencoder
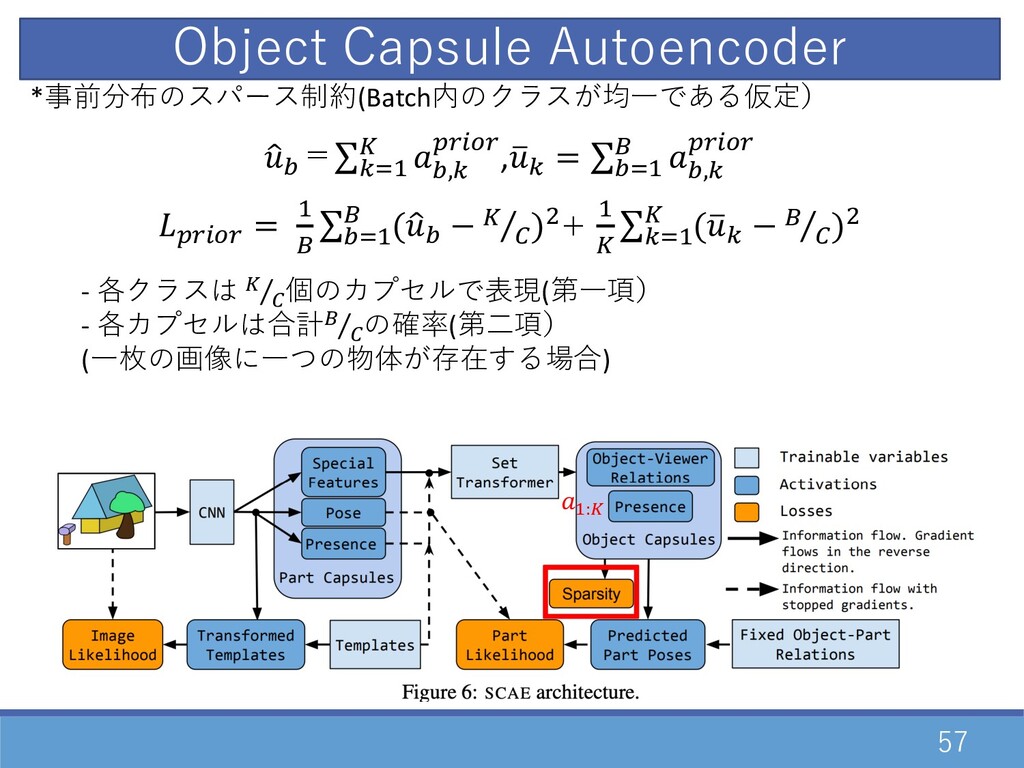
57 *事前分布のスパース制約(Batch内のクラスが均⼀である仮定) 1 ‘ =∑=…D • ‘,= ŠZ0•Z ,’ =
= ∑‘…D “ ‘,= ŠZ0•Z ŠZ0•Z = D “ ∑‘…D “ (1 ‘ − ⁄ • • )"+ D • ∑=…D • (’ = − ⁄ “ • )" - 各クラスは ⁄ • • 個のカプセルで表現(第⼀項) - 各カプセルは合計 ⁄ “ • の確率(第⼆項) (⼀枚の画像に⼀つの物体が存在する場合) D:• Object Capsule Autoencoder
58 *事前分布のスパース制約(Batch内のクラスが均⼀である仮定) 1 ‘ =∑=…D • ‘,= ŠZ0•Z ,’ =
= ∑‘…D “ ‘,= ŠZ0•Z ŠZ0•Z = D “ ∑‘…D “ (1 ‘ − ⁄ • • )"+ D • ∑=…D • (’ = − ⁄ “ • )" - 各クラスは ⁄ • • 個のカプセルで表現(第⼀項) - 各カプセルは合計 ⁄ “ • の確率(第⼆項) (⼀枚の画像に⼀つの物体が存在する場合) Object Capsule Autoencoder 全てのCapsuleが活性化するような正則化 → 正則化がない場合に⽐べて精度は改善している (下記は教師なし識別の場合の精度)
59 K個の各Capsuleから3つのパラメータ推定 - Object-part Relations() : 物体-パーツ間のaffine変換⽤⾏列([3×3]) - Probability (=,E
) : Capsule k に パーツnが存在している確率 - = Q standard deviation () : 特徴ベクトル= から計算 =,D:– , =,D:E , =,D:E = ℎ= Š•Z—(= ) M個の⼊⼒からN個のパーツ候補(N ≤ ) D:• D:• =,D:• , =,D:E Object Capsule Autoencoder D:†
60 viewer-partsの関係(=,E )を⾏列で表現 - ⾏列を[平均・分散]に分解(パーツ毎の事後確率計算のため) - 推定した[平均・分散]から尤度推定 =,E = ==,E
=,E → =,E , =,E \ , ) = \ =,E , =,E D:• =,E , =,E ← =,E D:• Object Capsule Autoencoder D:†
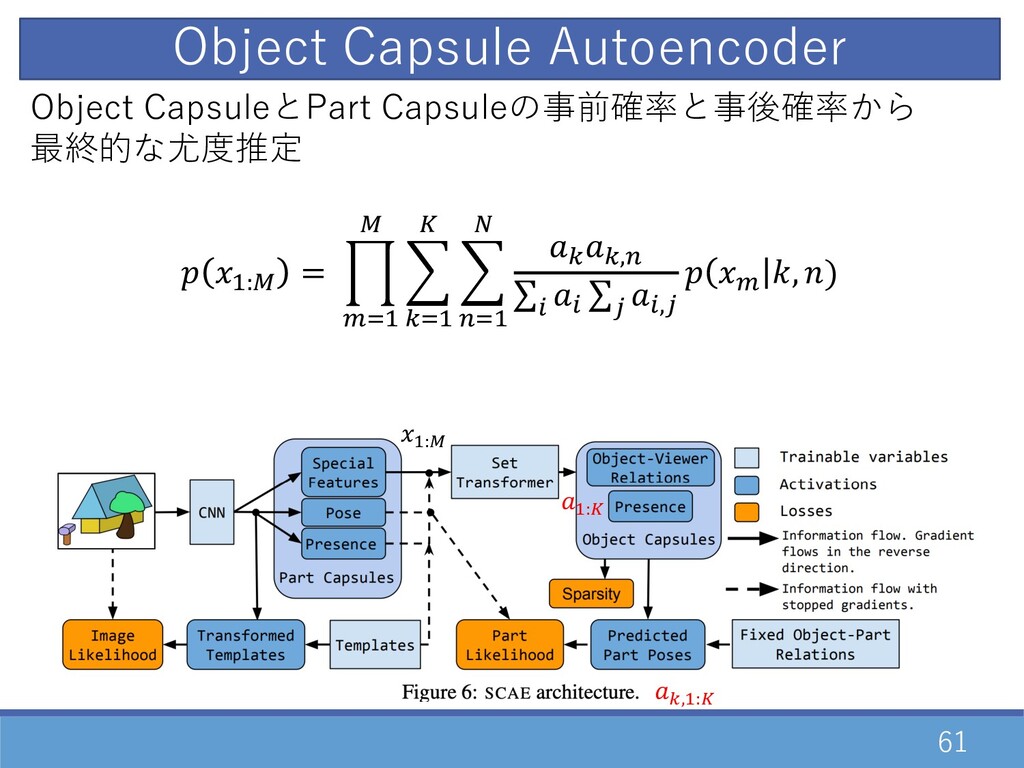
61 D:† Object CapsuleとPart Capsuleの事前確率と事後確率から 最終的な尤度推定 D:† = „ \…D
† O =…D • O E…D – = =,E ∑0 0 ∑2 0,2 \ , ) D:• =,D:• Object Capsule Autoencoder
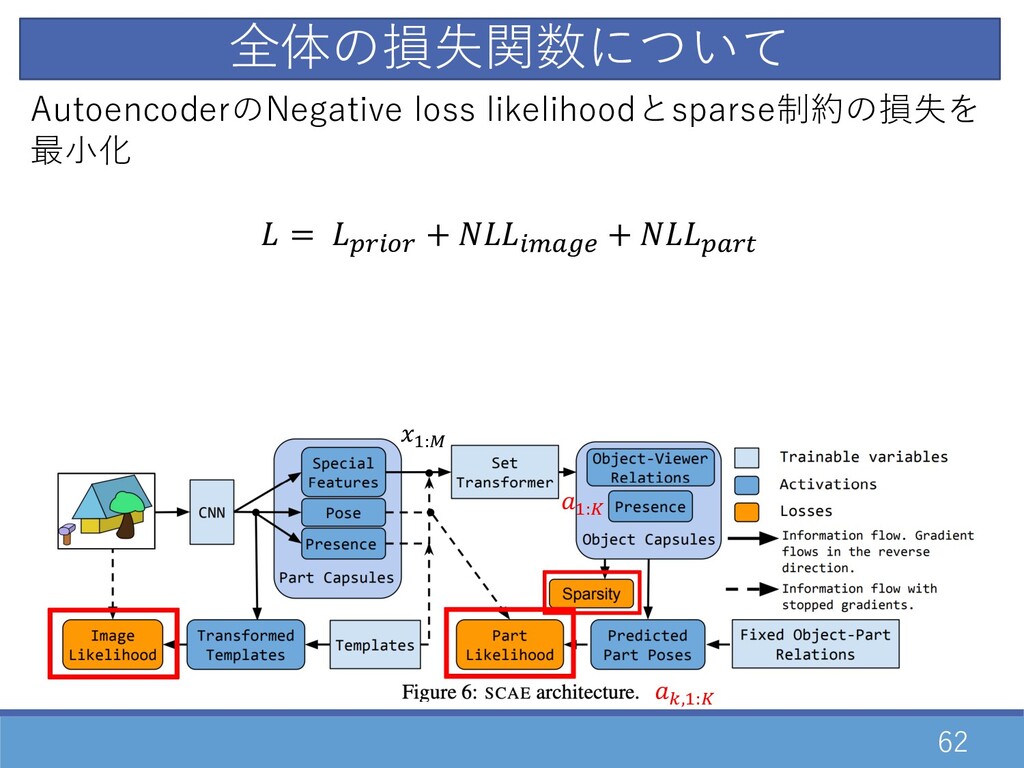
62 D:† AutoencoderのNegative loss likelihoodとsparse制約の損失を 最⼩化 = ŠZ0•Z + 0\•žŸ
+ Š•Z— D:• =,D:• 全体の損失関数について
63 ⽤いたデータセット - MNIST, CIFAR10, SVHN 確認した評価 - 教師なしでの識別精度 評価に⽤いたデータセット
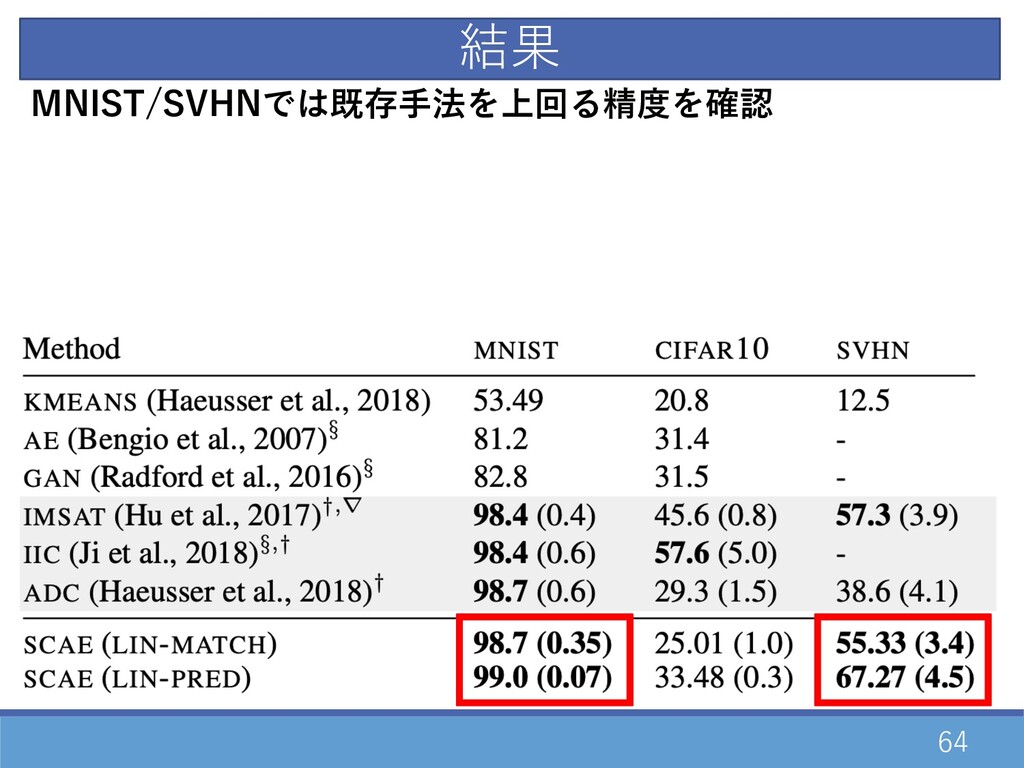
64 MNIST/SVHNでは既存⼿法を上回る精度を確認 結果
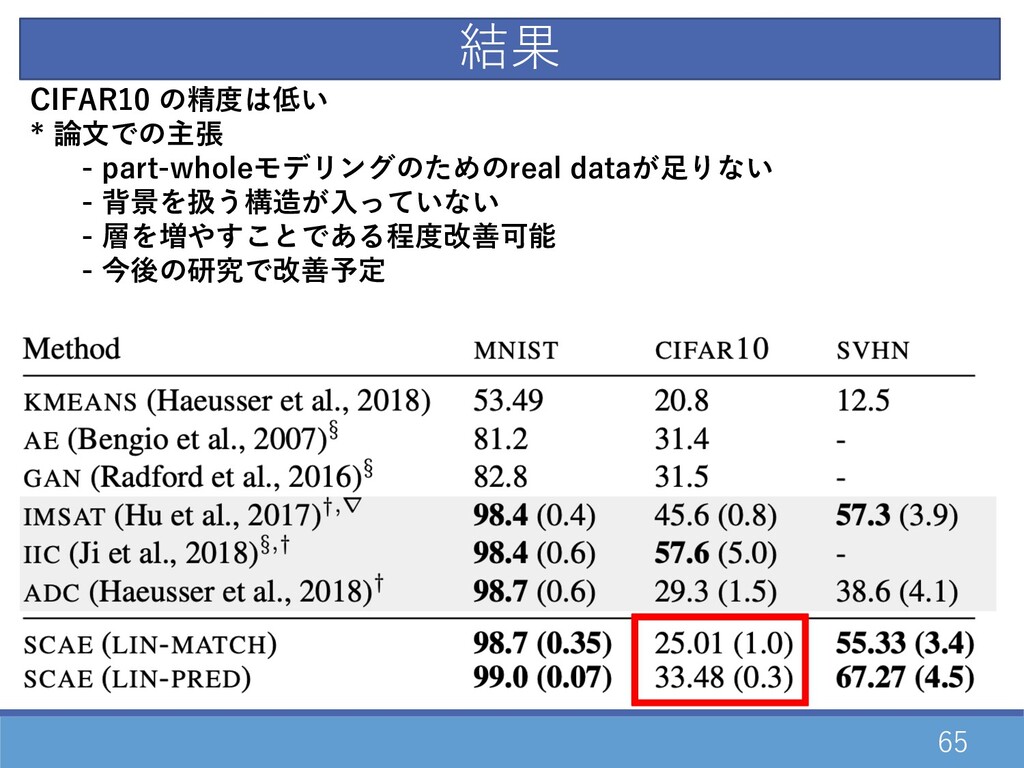
65 CIFAR10 の精度は低い * 論⽂での主張 - part-wholeモデリングのためのreal dataが⾜りない - 背景を扱う構造が⼊っていない
- 層を増やすことである程度改善可能 - 今後の研究で改善予定 結果
参考⽂献
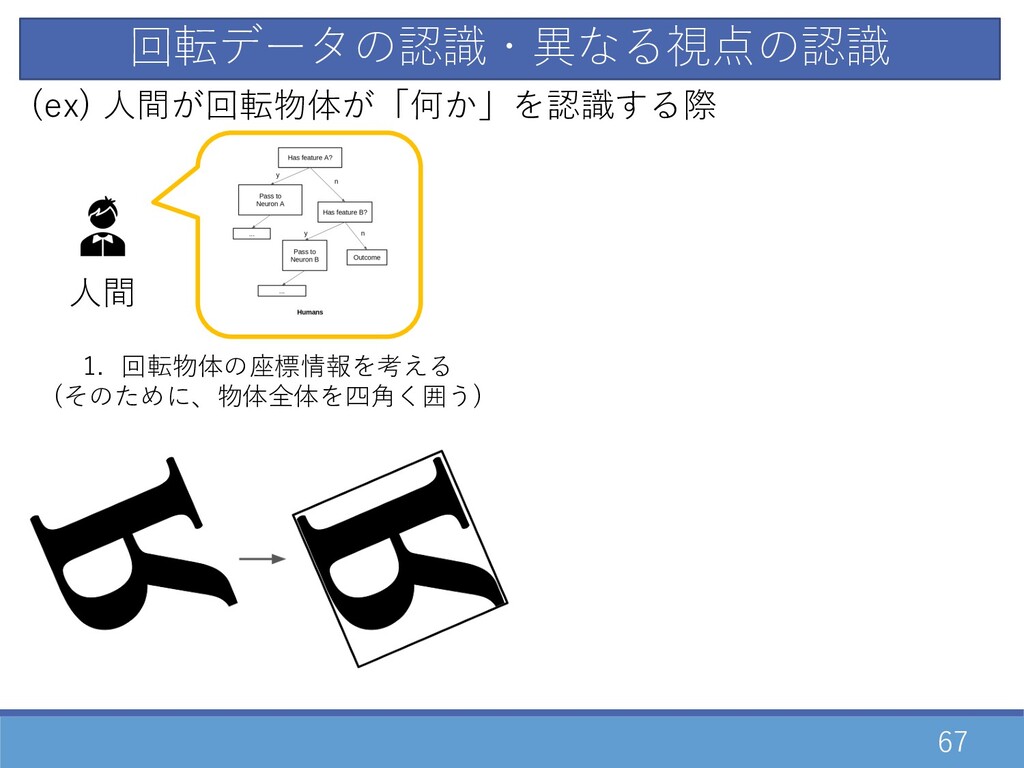
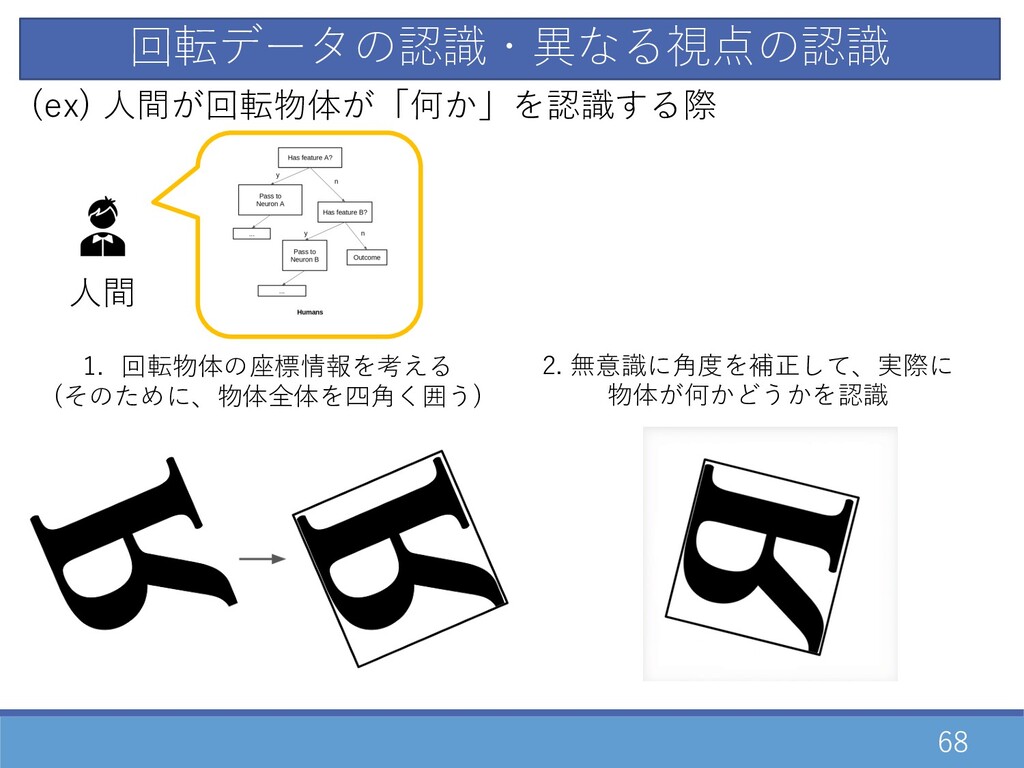
67 回転データの認識・異なる視点の認識 ⼈間 (ex) ⼈間が回転物体が「何か」を認識する際 1. 回転物体の座標情報を考える (そのために、物体全体を四⾓く囲う)
68 回転データの認識・異なる視点の認識 ⼈間 (ex) ⼈間が回転物体が「何か」を認識する際 1. 回転物体の座標情報を考える (そのために、物体全体を四⾓く囲う) 2. 無意識に⾓度を補正して、実際に
物体が何かどうかを認識
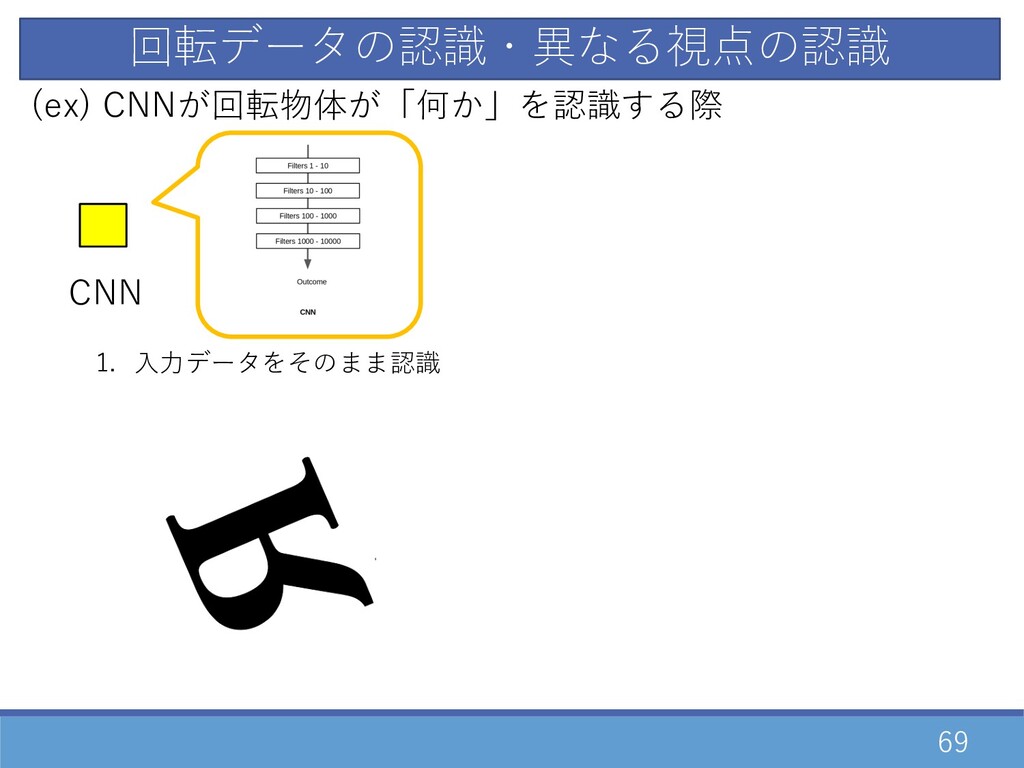
69 回転データの認識・異なる視点の認識 CNN (ex) CNNが回転物体が「何か」を認識する際 1. ⼊⼒データをそのまま認識
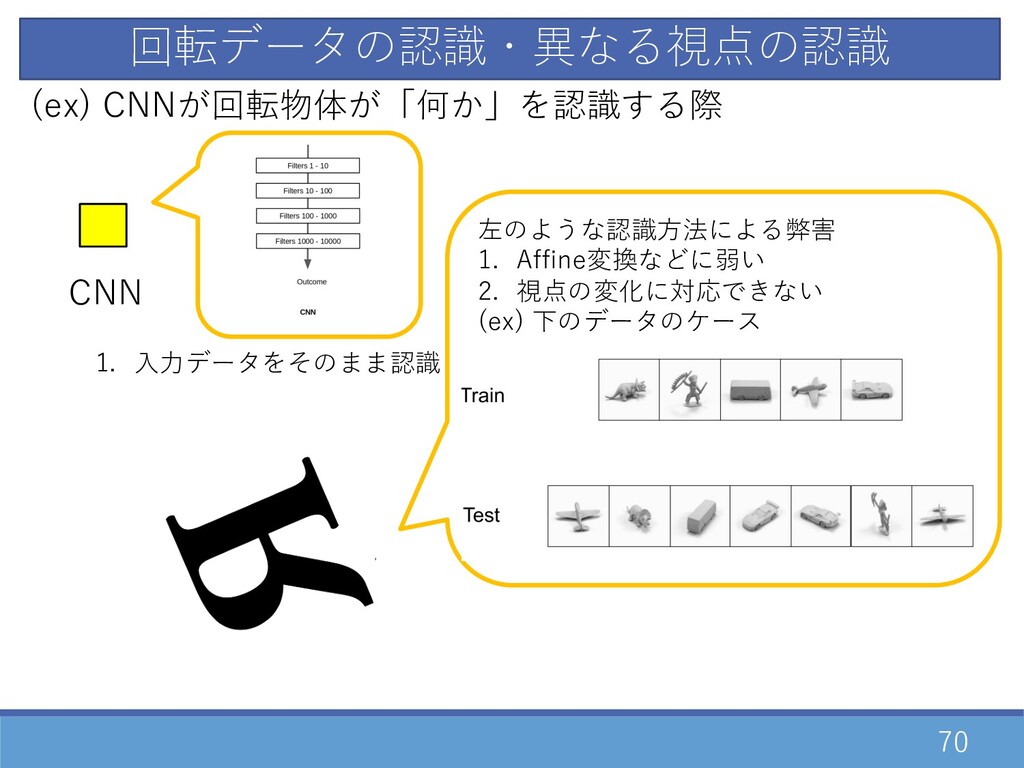
70 回転データの認識・異なる視点の認識 CNN (ex) CNNが回転物体が「何か」を認識する際 1. ⼊⼒データをそのまま認識 左のような認識⽅法による弊害 1. Affine変換などに弱い
2. 視点の変化に対応できない (ex) 下のデータのケース
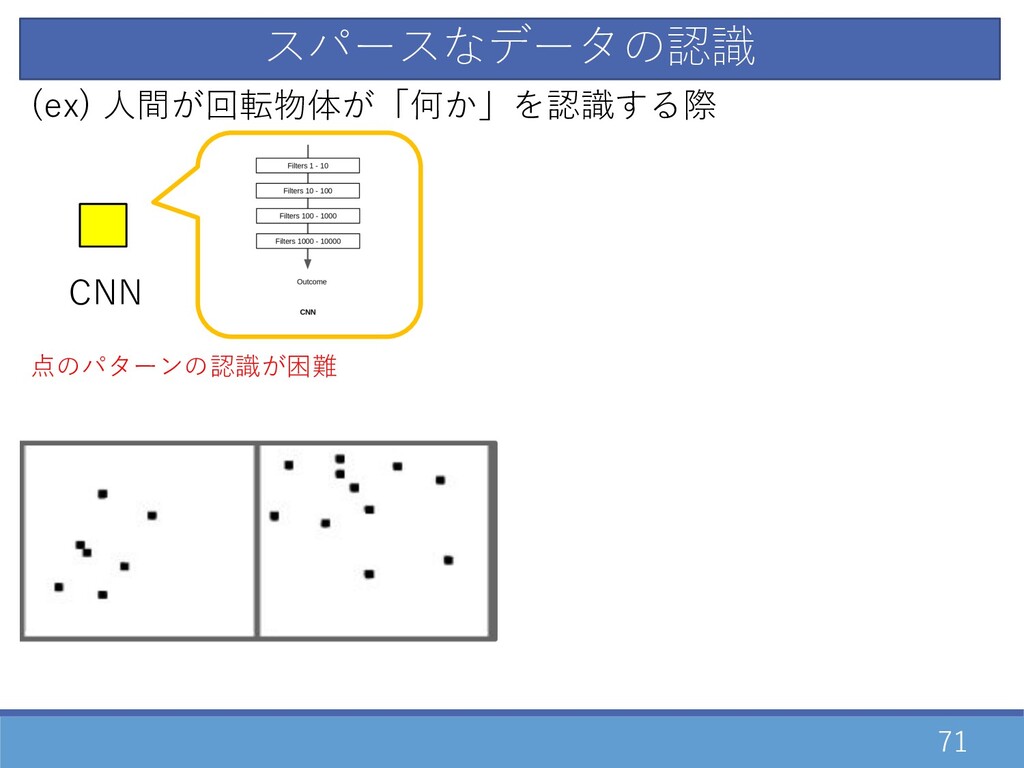
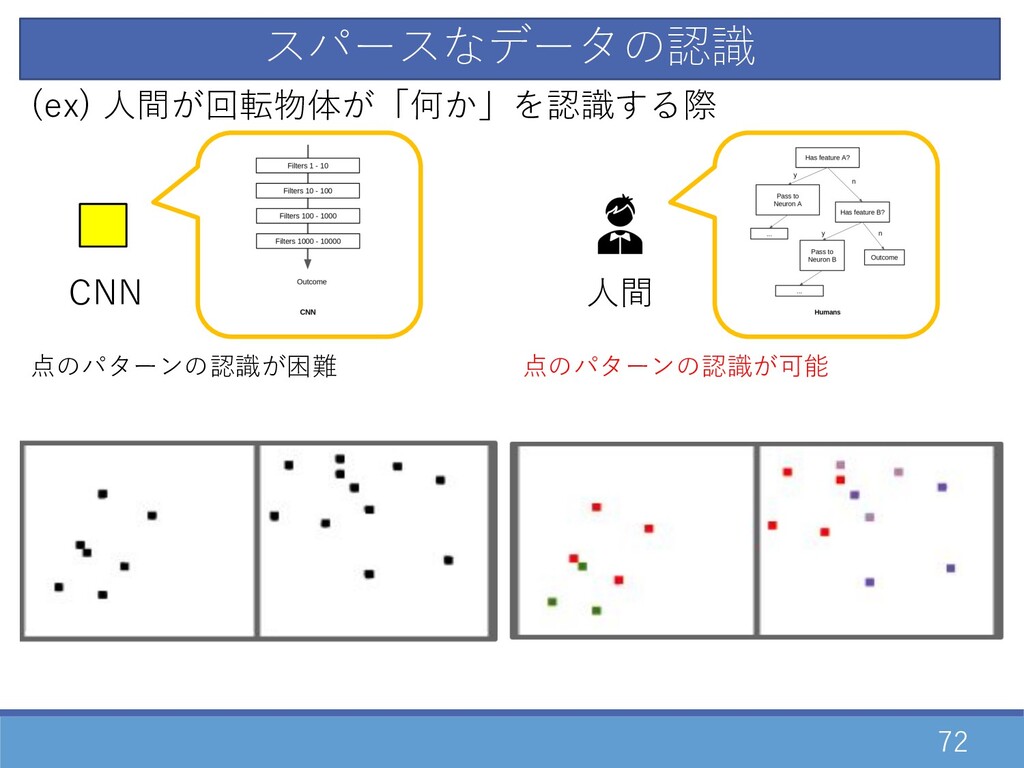
71 スパースなデータの認識 CNN (ex) ⼈間が回転物体が「何か」を認識する際 点のパターンの認識が困難
72 スパースなデータの認識 CNN (ex) ⼈間が回転物体が「何か」を認識する際 ⼈間 点のパターンの認識が困難 点のパターンの認識が可能
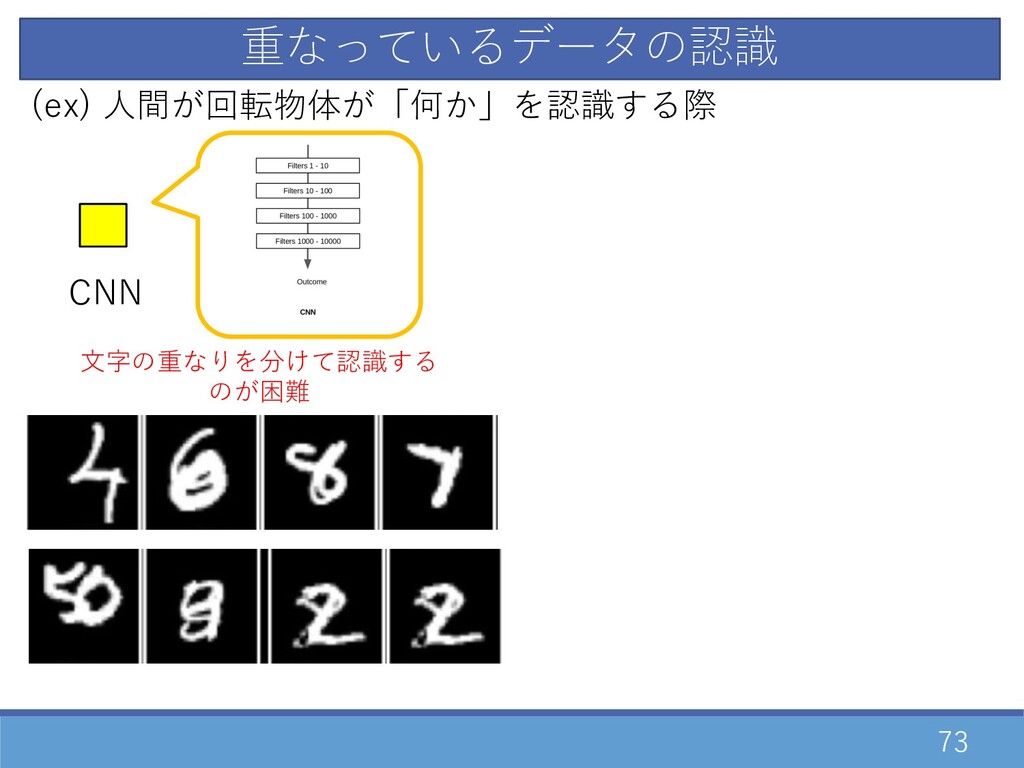
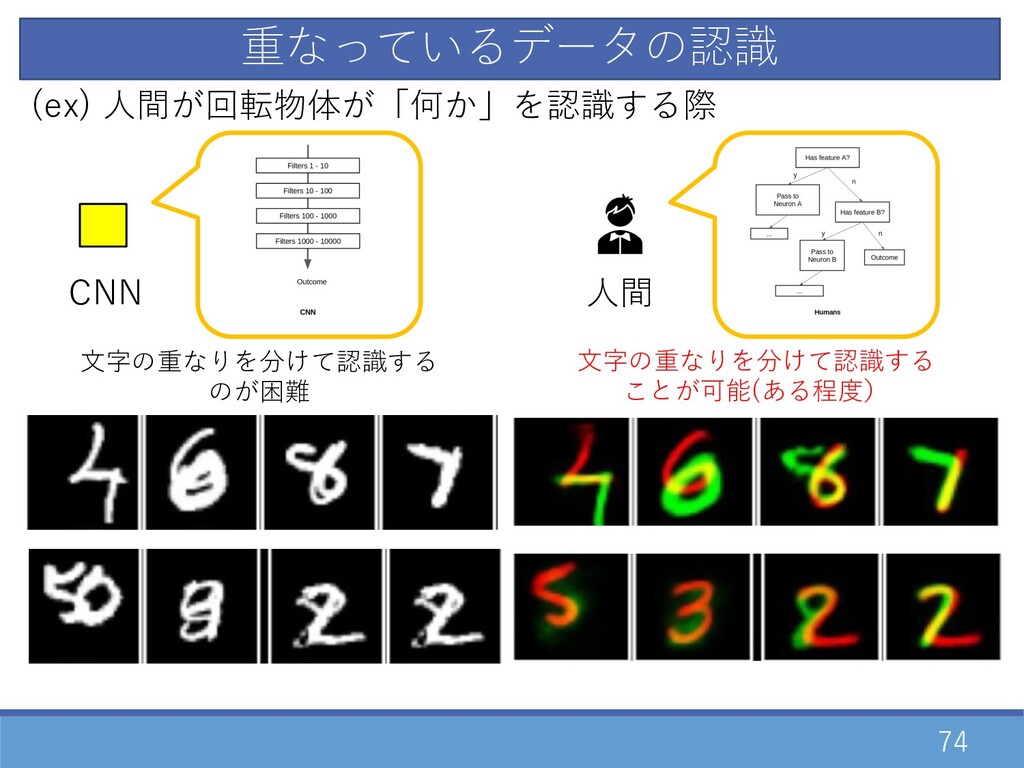
73 重なっているデータの認識 CNN (ex) ⼈間が回転物体が「何か」を認識する際 ⽂字の重なりを分けて認識する のが困難
74 重なっているデータの認識 CNN (ex) ⼈間が回転物体が「何か」を認識する際 ⼈間 ⽂字の重なりを分けて認識する のが困難 ⽂字の重なりを分けて認識する ことが可能(ある程度)
75 Capsule Network Tutorial Dynamic Routing Between Capsule(NIPS 2017) Capsule
Networkのrouting/基礎的な数式に関する説明 YouTube : https://www.youtube.com/watch?v=pPN8d0E3900 Slide : https://www.slideshare.net/aureliengeron/introduction-to-capsule-networks-capsnets
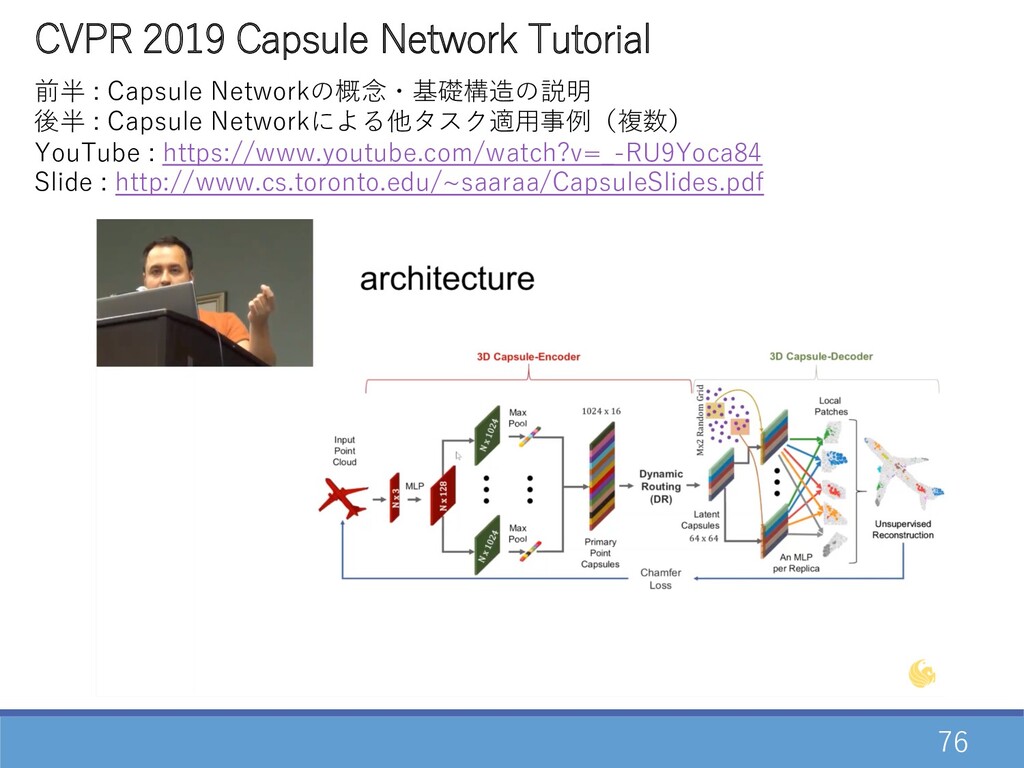
76 CVPR 2019 Capsule Network Tutorial 前半 : Capsule Networkの概念・基礎構造の説明
後半 : Capsule Networkによる他タスク適⽤事例(複数) YouTube : https://www.youtube.com/watch?v=_-RU9Yoca84 Slide : http://www.cs.toronto.edu/~saaraa/CapsuleSlides.pdf
77 Web References ・Understanding Dynamic Routing between capsules : https://jhui.github.io/2017/11/03/Dynamic-Routing-Between-Capsules/
・Understanding Matrix capsules with EM routing : https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/ ・カプセルニューラルネットワークはニューラルネットワークを超えるか https://qiita.com/hiyoko9t/items/f426cba38b6ca1a7aa2b ・Dynamic Routing between Capsules 再現実装 https://github.com/motokimura/capsnet_pytorch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![38 Capsule Networkの学習(損失計算) G D 0.9 0.1 ベクトル 最終出⼒ [1x16x2]](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![48 各パーツの ベクトル保持 ⽊ 家 ポスト ?? ベクトルの連結を予測(教師なし) \ ]](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_47.jpg){kind=link}
{kind=link}
![50 ∈ [, ]×× ⼊⼒ ∈ [0,1]n×o×Pを分解 - ポーズ集合 \](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_49.jpg){kind=link}
![51 特徴 \ ∈ ℝPw からTemplate\ ∈ [0,1]n{×o|×(PVD)の⾊を 予測 \](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_50.jpg){kind=link}
![52 TemplateとPoseで 再構成 ( ) ポーズ集合 \ をTemplate(\ ∈ [0,1]n{×o{×(PVD))でアフィン変換](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_51.jpg){kind=link}
![53 TemplateとPoseで 再構成 各パーツ] E の透過率(alpha channel)に存在確率 \ を乗算 (画像の(,](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_52.jpg){kind=link}
![54 TemplateとPoseで 再構成 画像の尤度のGMMで計算 - \ ‚ ] \,0,2 P](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![59 K個の各Capsuleから3つのパラメータ推定 - Object-part Relations() : 物体-パーツ間のaffine変換⽤⾏列([3×3]) - Probability (=,E](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_58.jpg){kind=link}
![60 viewer-partsの関係(=,E )を⾏列で表現 - ⾏列を[平均・分散]に分解(パーツ毎の事後確率計算のため) - 推定した[平均・分散]から尤度推定 =,E = ==,E](https://files.speakerdeck.com/presentations/9e3d4ff408aa44c2a76da335bc086f02/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}