Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Relevance Filtering for Embedding-based Retrieval
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Hiroki_Iida
May 24, 2025
Research
140
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Relevance Filtering for Embedding-based Retrieval
IR-READING 2025春
Hiroki_Iida
May 24, 2025
More Decks by Hiroki_Iida
See All by Hiroki_Iida
SCOTT: Self-Consistent Chain-of-Thought Distillation
meshidenn
0
680
Match Your Words! A Study of LexicalMatching in Neural Information Retrieval
meshidenn
0
270
COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List
meshidenn
1
530
CEQE- Contextualized Embeddings for Query Expansion.
meshidenn
0
310
ACL2019網羅的サーベイ報告会-iida発表
meshidenn
0
120
What the vec
meshidenn
1
420
Other Decks in Research
See All in Research
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
470
事後確率分布の共分散について
koide3
0
170
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.6k
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
230
Claude Code × autoresearch 実践
mathbullet
0
200
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
100
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
正規分布と最適化について
koide3
1
300
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
430
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
620
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
840
Featured
See All Featured
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
Everyday Curiosity
cassininazir
0
250
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
290
Navigating Team Friction
lara
192
16k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
KATA
mclloyd
PRO
35
15k
The Language of Interfaces
destraynor
162
27k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
30 Presentation Tips
portentint
PRO
1
340
Building AI with AI
inesmontani
PRO
1
1.1k
WENDY [Excerpt]
tessaabrams
11
38k
Transcript
Relevance Filtering for Embedding-based Retrieval Authors: Nicholas Rossi, Juexin Lin,
Feng Liu, Zhen Yang, Tony Lee, Alessandro Magnani, Ciya Liao CIKM '24: Applied Research Papers IR READING 2025春 紹介者: (株) UZABASE 飯田 大貴 特に断りがない限り、図表は本論文からの引用です 1
自己紹介 ▪ 名前:飯田 大貴(IR Readingには度々参加させてもらっています) ▪ 所属:(株) ユーザベース • 経済情報基盤を活用して、経営のスピードを上げる情報プラットフォーム
「スピーダ」を提供 ▪ 業務内容:プロダクト横断の検索 /分類モデルの構築とサービスの構築・運用 ▪ インターン等興味あるかたはお声がけください https://www.uzabase.com/jp/ https://www.uzabase.com/jp/info/20241220-corp_jp/ 2
概要と読んだ理由 ▪ 概要:検索結果をPrecision-Recall高く足切りするために、スコアリングの変換関数を提 案 ▪ 読んだ理由:簡易な足切り方法を知りたかった。 Applied系の論文読んでみたかった。 3
論文が対象とする課題と解決方針 ▪ 無関係な検索結果を表示しないようにして、検索体験を向上させたい ▪ そのため、いい感じに無関係な検索結果をフィルタしたい ▪ しかし、ベクトル検索で用いられる類似度(特に cos類似度)は、しきい値 として用いることが難しい ▪
なぜなら、対照学習を用いて学習されているため、クエリに対して相対的なスコアにな る ▪ そのため、cos類似度を絶対的なスコアに変換したい 4
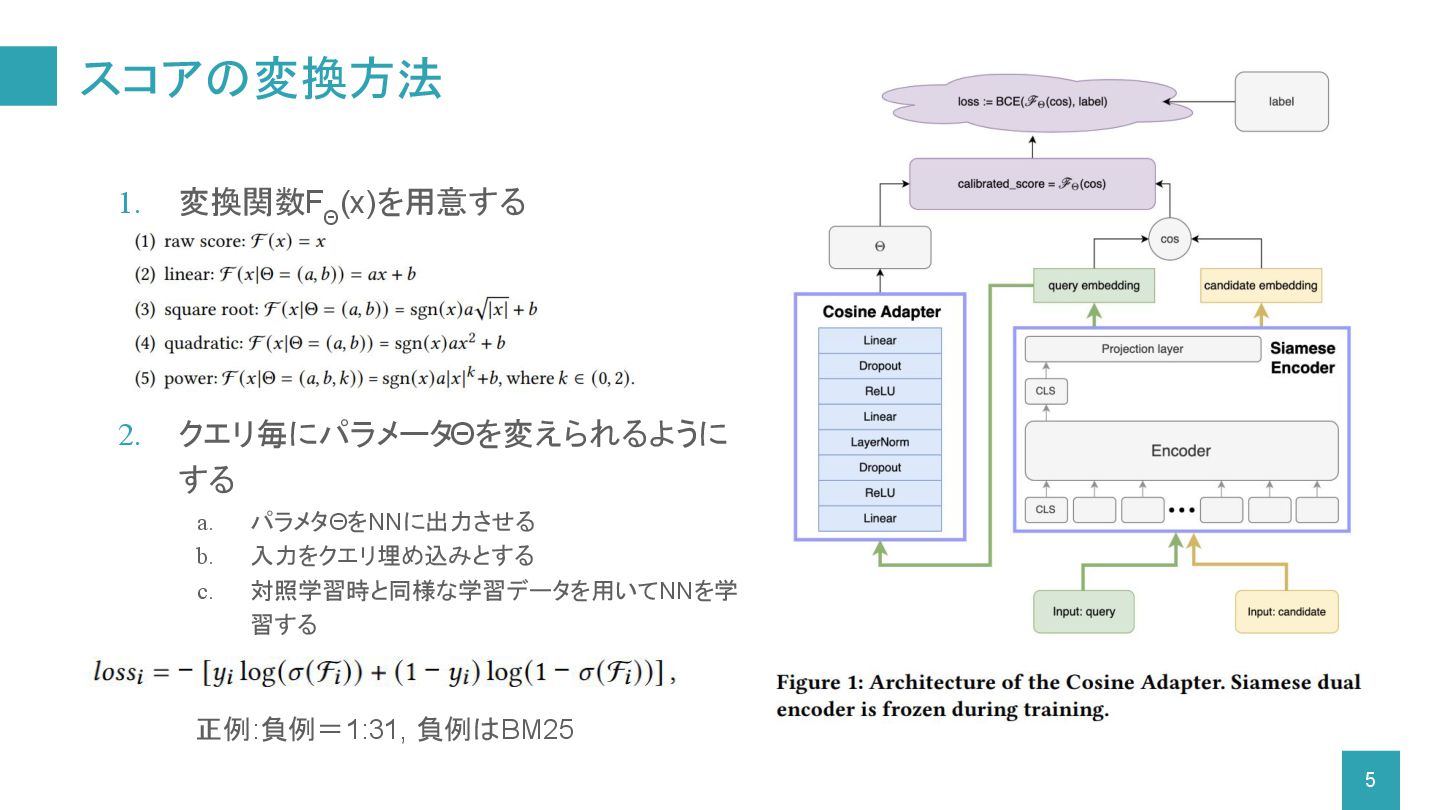
スコアの変換方法 1. 変換関数F Θ (x)を用意する 2. クエリ毎にパラメータΘを変えられるように する a. パラメタΘをNNに出力させる
b. 入力をクエリ埋め込みとする c. 対照学習時と同様な学習データを用いてNNを学 習する 正例:負例=1:31, 負例はBM25 5
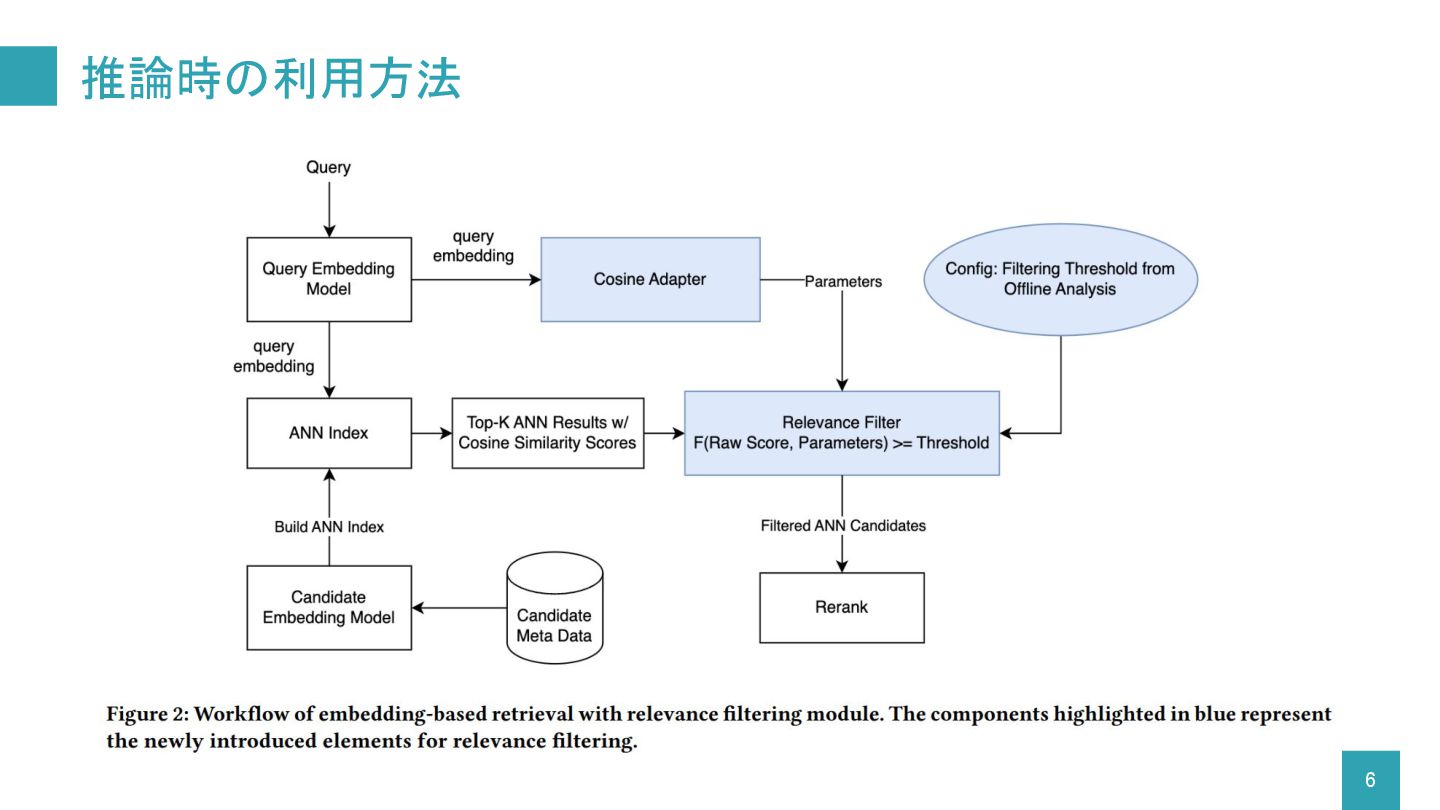
推論時の利用方法 6
実験:MSMARCO ▪ PR AUCとMRRが改善 ▪ K=1000でP@R95とFilter%改善 ▪ Null%*について • K=1000で改善し、K=10では改悪。一
つも正例が登場しないクエリが、K=10 では30%だが、K=1000で1%であるた め • powerでnull、かつraw scoreがnullで はない場合において、70%は正例が top10にない ▪ 先行手法のChoppy#より良い。正 例が一つしかない場合が多いデー タであるため、削り過ぎている 提案手法 提案手法 *あるしきい値*で検索結果が返ってこなくなる度合い。しきい値は 5.2.3よりP@R95で決めたと推察 # Transformeベースの学習でしきい値を決める手法 7
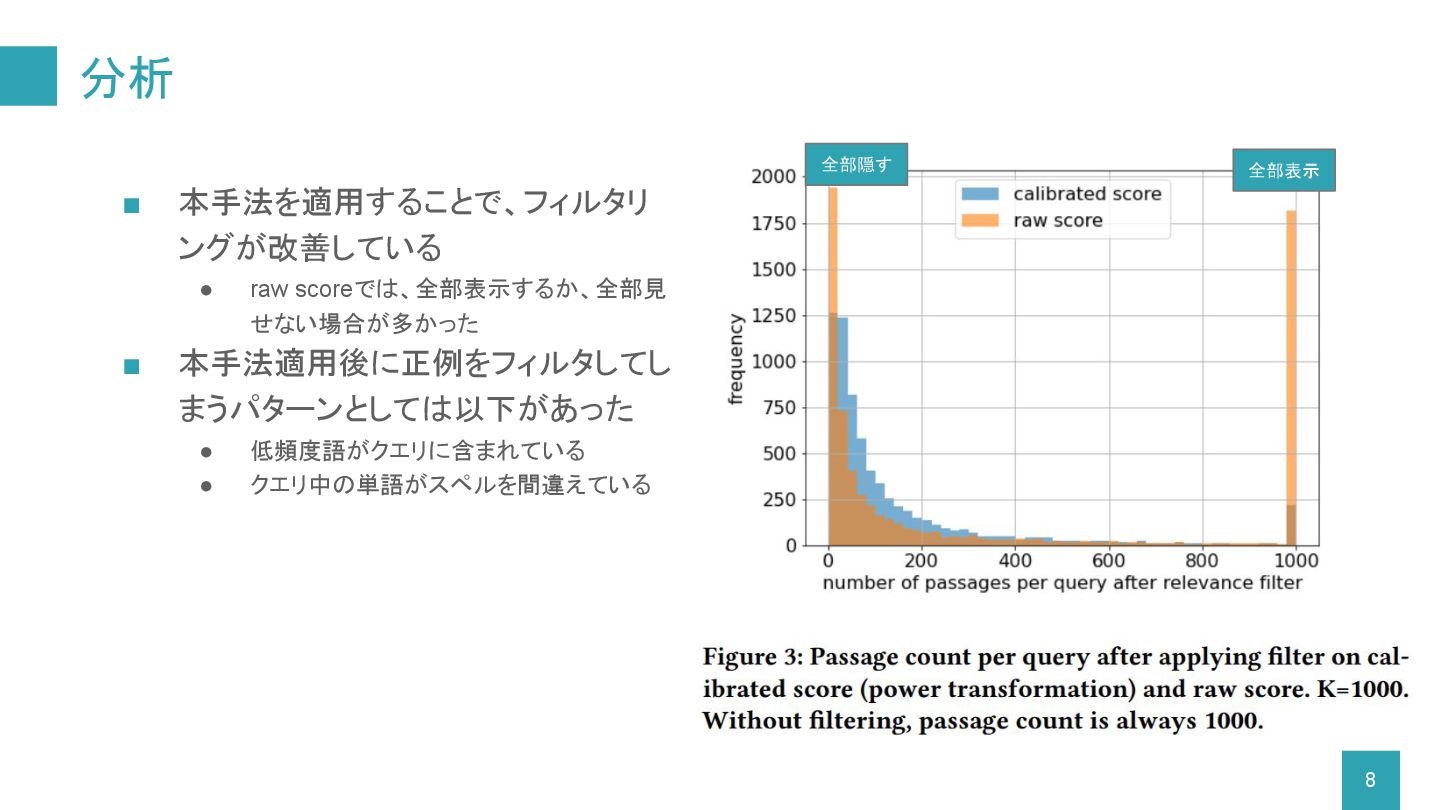
分析 ▪ 本手法を適用することで、フィルタリ ングが改善している • raw scoreでは、全部表示するか、全部見 せない場合が多かった ▪ 本手法適用後に正例をフィルタしてし
まうパターンとしては以下があった • 低頻度語がクエリに含まれている • クエリ中の単語がスペルを間違えている 全部表示 全部隠す 8
実験:WallMartデータ ▪ 提案手法により改善 ▪ Contrastive Lossの方が、Listwise Loss*よりも良い結果 • ListwiseLossの方が、検索結果内で相対 的なスコアを学習するため
• 提案手法を適用することで差が縮まる ▪ Recallが低くなるクエリには以下の傾 向があった • レアブランド名 • 数字 • スペルミス *先行研究では、単純な精度は ListwiseLossのほうが良かった 9
実験: Walmart システム ▪ Walmartのシステムでオンラインテスト。Rerankerを用いた後の結果。 ▪ Top10 Precisionを人手で確認。Precisionがやや改善 ▪ ビジネス指標(OrderとGross
Merchandise Value)をA/Bテスト。特に改善はなかった 10
事例: Walmart システム ▪ 無関係だったものが、フィルタされている ▪ FilterしてからRerankしているので、10位のやや関係ある商品は出現していると思われ る 11
まとめと感想 まとめ ▪ 検索結果をPrecision-Recall高く足切りするために、スコアリングの変換関数を提案 ▪ 2つのドメインの異なるデータセットで効果的であることを示した。 また、実システムで検証した 感想 ▪ Rerankerより簡易にフィルタできるのは良いが、
Rerankerでもよいのでは? ▪ ドメイン外でも使用可能なのか気になる。難しそう。 Rerankerでもよいのでは? 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}