[RFC 1737] as a way of identifying resources for the Web; • URNs (“Universal Resource Names”) were introduced at the same time primarily (and then updated in [RFC 2141] as a way of mapping existing identifier systems to a URL-like syntax; • [RFC 1737] also introduced URCs (“Universal Resource Characteristics”) but these never caught on.
a joint W3C/IETF working group of the “Universal Resource Indicator”, a single syntax encompassing both URLs and URIs; • In 2005, [RFC 3986] reinforced this, deprecating the terms “URL” and “URN” altogether; • [RFC 3987], also in 2005, introduced a superset of URIs, IRIs (“Internationalized Resource Identifier”), which can contain non-ASCII characters.
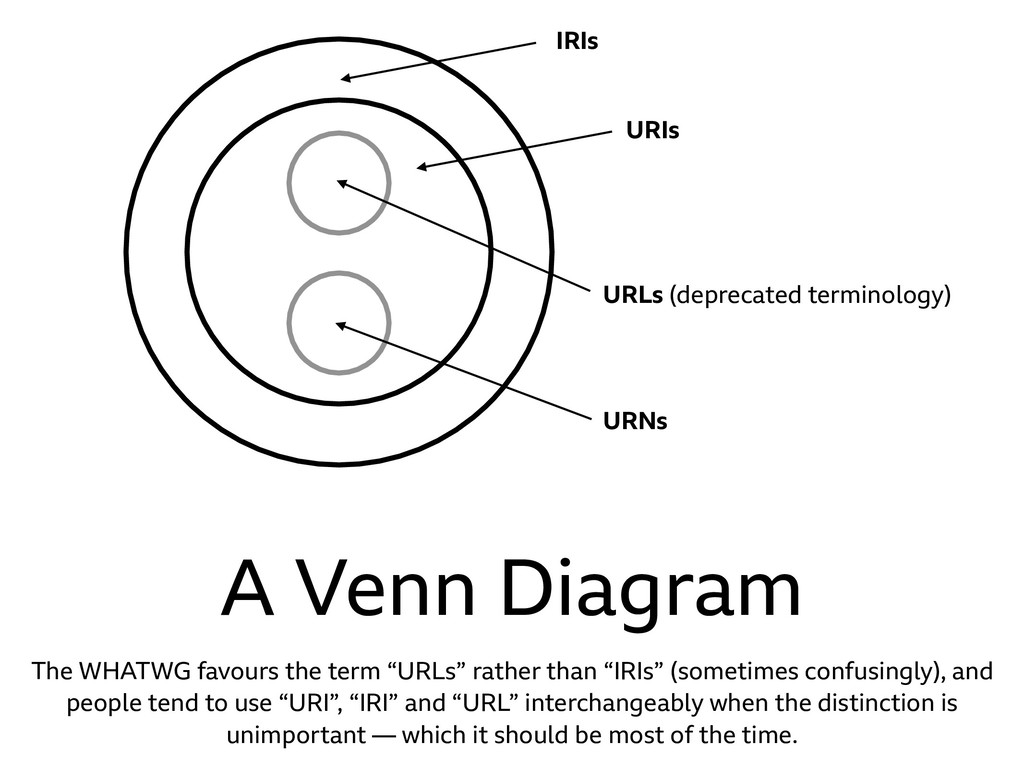
WHATWG favours the term “URLs” rather than “IRIs” (sometimes confusingly), and people tend to use “URI”, “IRI” and “URL” interchangeably when the distinction is unimportant — which it should be most of the time.
into the same syntactic space used by URLs so they can be stored/retrieved/queried without needing special handling (i.e., “how do you store an ISBN in a field wanting a URI-shaped identifier?”) — there are also some URI schemes for this (e.g., “tel:…” and “oid:…” URIs); • Pan-organisation identifiers for things which cannot possibly have a general- purpose resolution scheme (e.g., “urn:uuid:…”), • When you don’t trust your infrastructure enough to that you’ll be able to maintain your domain registration for the long term (i.e., decades) but still need identifier uniqueness as a service being provided to the wider Internet (again, some specialised URI schemes tend to be used for this instead nowadays); • Fundamentally, where the systems you retrieve data from will have no relation whatsoever to the issuer of the identifiers, or the identifier scheme has no concept of an issuer.
is more onerous than registering a domain name (IANA template vs buying a domain); • There’s no standardised resolution process; this isn’t a problem if—and only if—you know that users of the identifier will never need fetch data from the registration authority and its delegates (for example, because there is no registration authority, as in the case of UUIDs). • URNs were purposefully a backwards-compatibility hack: they are a fundamentally-limited kind of URI intended to bridge a gap between pre-Web systems and Web Architecture.
living in the last century, you shouldn’t If you think you probably need such a thing, register a URI scheme instead. If you don’t think your scheme qualifies as a legitimate URI scheme, then it doesn’t pass muster as a URN scheme either.
Carve out space within your public URL schema (which ensures identifiers can be exchanged seamlessly with other organisations — the public-facing domain name becomes the identifier authority); • Distinguish between retrievable things (e.g., HTML documents, XML files, JSON, etc.; also known as “information resources”) and conceptual things (e.g., a piece of music, a physical place, etc.; also known as “non-information resources”) by appending a fragment to the latter; • Follow good URI design principles: don’t include unnecessary/implementation detail, ensure self- uniqueness; generally boil it down to the bare minimum needed to ensure future-proofing; don’t bake in anything that will change over time; • In particular, don’t include the name of a system in the URIs (in contrast to categories of thing, which should be sufficiently future-proof and unchanging); • If you were happy with URNs, then it doesn’t matter that the URIs you mint don’t actually resolve: but this way they’re not prevented from ever doing so.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}