Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Beating State-of-the-art By -10000% @ CIDR Gong...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Reynold Xin
January 07, 2013
Research
160
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Beating State-of-the-art By -10000% @ CIDR Gong Show
I gave a 5-min Gong Show talk at CIDR on my experience with Spark, Shark, and GraphX.
Reynold Xin
January 07, 2013
More Decks by Reynold Xin
See All by Reynold Xin
(Berkeley CS186 guest lecture) Big Data Analytics Systems: What Goes Around Comes Around
rxin
12
2k
Interface Design for Spark Community
rxin
12
1.4k
Spark Committer Night meetup @ NYC
rxin
1
140
Apache Spark: Unified Platform for Big Data
rxin
1
250
Advanced Spark @ Spark Summit 2014
rxin
4
360
Apache Spark: Easier and Faster Big Data
rxin
2
310
GraphX at Spark User Meetup
rxin
0
170
Shark SIGMOD research deck
rxin
2
570
The Spark Ecosystem: Fast and Expressive Big Data Analytics in Scala @ Scala Days 2013
rxin
3
720
Other Decks in Research
See All in Research
NLP colloquium: AI Safety Survey
kanekomasahiro
0
850
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
670
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
Language and AI
ayaniwa
0
170
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
360
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
110
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
450
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
120
IA for theory
gpeyre
0
260
Cross-Media Human-Information Interaction
signer
PRO
0
120
Featured
See All Featured
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
The World Runs on Bad Software
bkeepers
PRO
72
12k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
How to Ace a Technical Interview
jacobian
281
24k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Transcript
Beating State-of-the-art By -10000% Reynold Xin, AMPLab, UC Berkeley with
help from Joseph Gonzalez, Josh Rosen, Matei Zaharia, Michael Franklin, Scott Shenker, Ion Stoica
Beating State-of-the-art By -10000% NOT A TYPO Reynold Xin, AMPLab,
UC Berkeley with help from Joseph Gonzalez, Josh Rosen, Matei Zaharia, Michael Franklin, Scott Shenker, Ion Stoica
MapReduce deterministic, idempotent tasks fault-tolerance elasticity resource sharing
“The bar for open source software is at historical low.”
“The bar for open source software is at historical low.”
i.e. “This is the right time to do grad school.”
iterative machine learning OLAP strong temporal locality
Does in-memory computation help in petabyte-scale warehouses?
Does in-memory computation help in petabyte-scale warehouses? YES
Spark How to do in-memory computation efficiently in a fault-tolerant
way?
Shark How to do SQL query processing efficiently in “MapReduce”
style SQL on top of Spark Hive compatible (UDF, Type, InputFormat, Metadata)
“You need to beat Hadoop by at least 100X to
publish a paper in 2013.”
“You need to beat Hadoop by at least 100X to
publish a paper in 2013.” i.e. “You should’ve come to grad school 2 years earlier.”
Shark in-memory columnar store dynamic query re-optimization and a lot
of engineering...
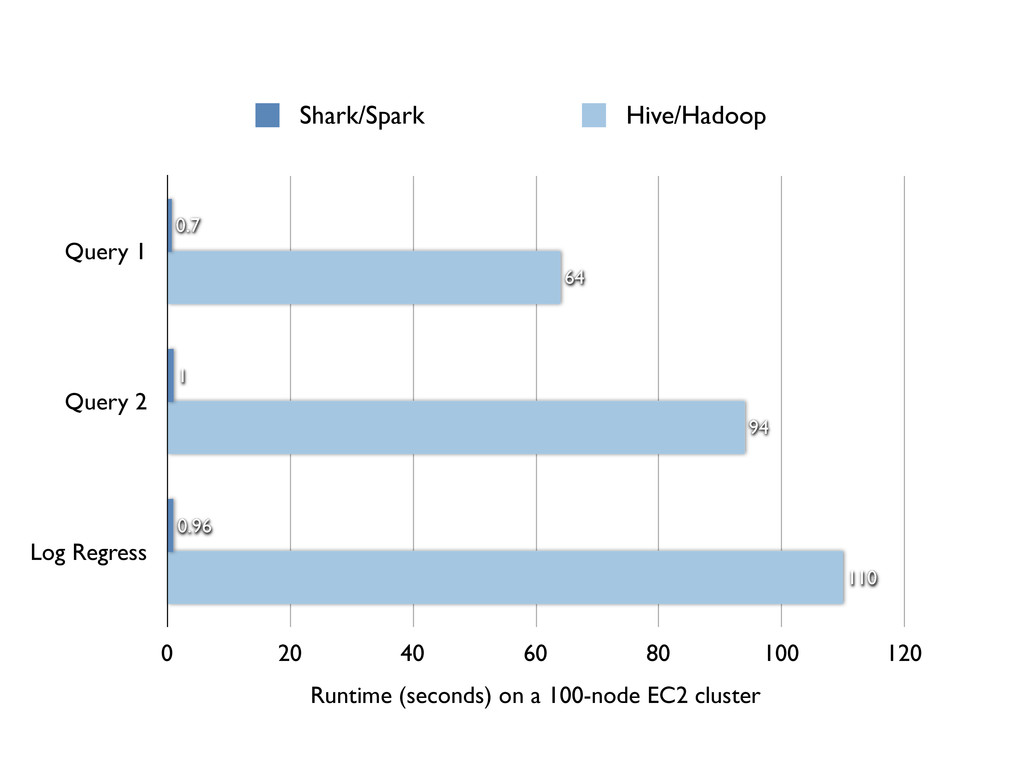
Query 1 Query 2 Log Regress 0 20 40 60
80 100 120 110 94 64 0.96 1 0.7 Runtime (seconds) on a 100-node EC2 cluster Shark/Spark Hive/Hadoop
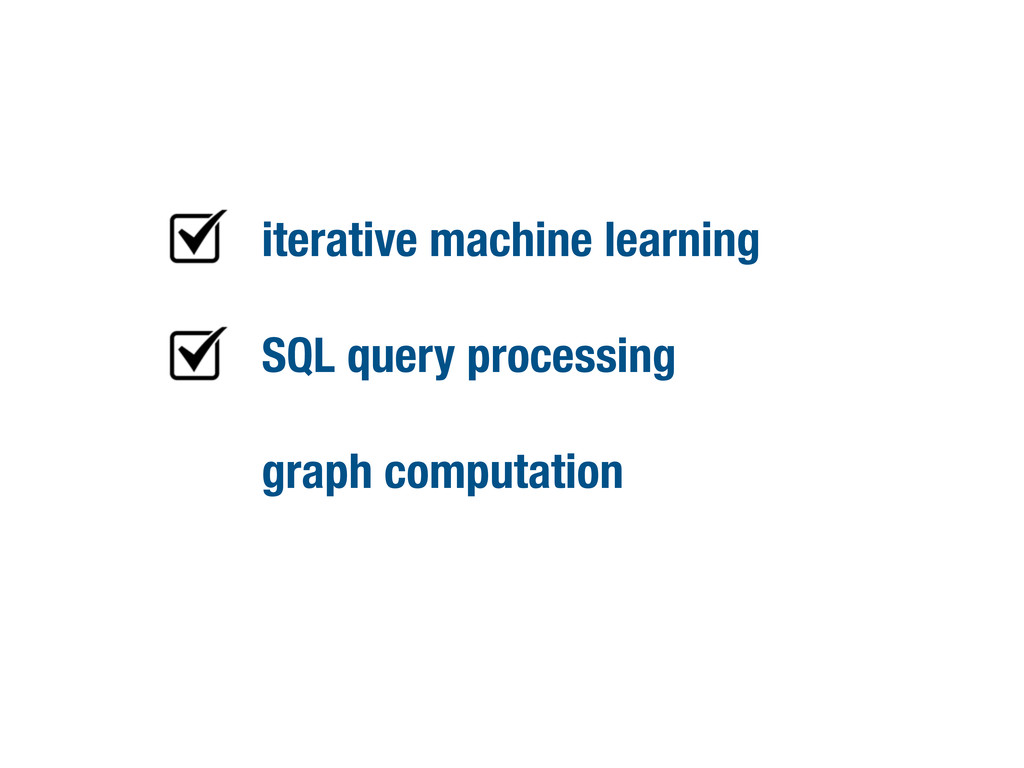
iterative machine learning SQL query processing
iterative machine learning SQL query processing graph computation
GraphLab on Spark
I spent a day pair-programming with Joey Gonzalez and improved
performance by 10X. Not bad for a day of work!
I spent a day pair-programming with Joey Gonzalez and improved
performance by 10X. but I later found out that it is still 10X slower than the latest version of GraphLab :(
A lot of open questions for fault- tolerant, distributed graph
computation. “MapReduce”? Data partitioning? Fault-tolerance? Asynchrony?
iterative machine learning www.spark-project.org SQL query processing shark.cs.berkeley.edu graph computation
www.wait-another-year.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}