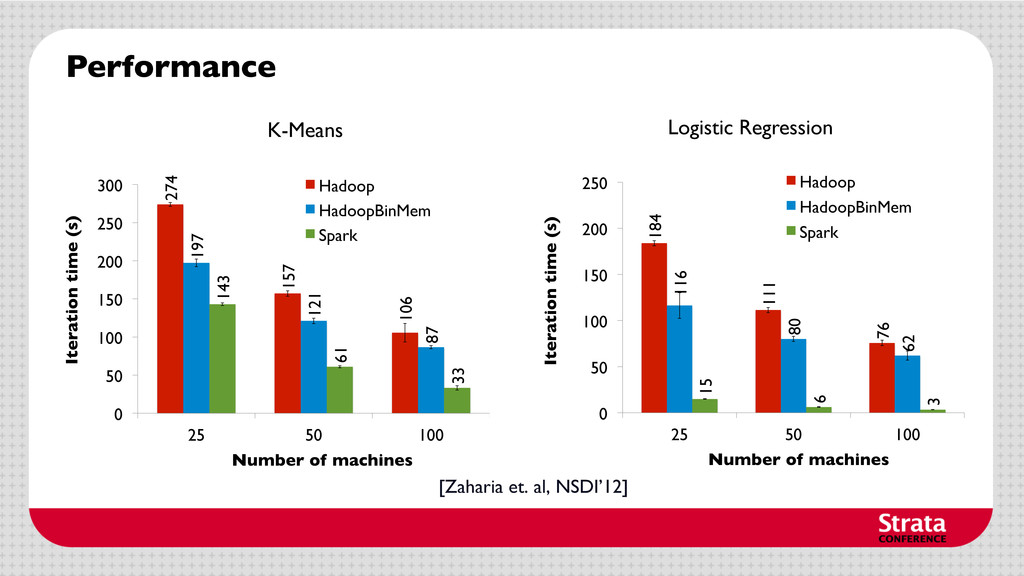
accelerates performance - Up to 20x faster than Hadoop § Easy to use high-level programming interface - Express complex algorithms ~100 lines. Machine Learning using Spark
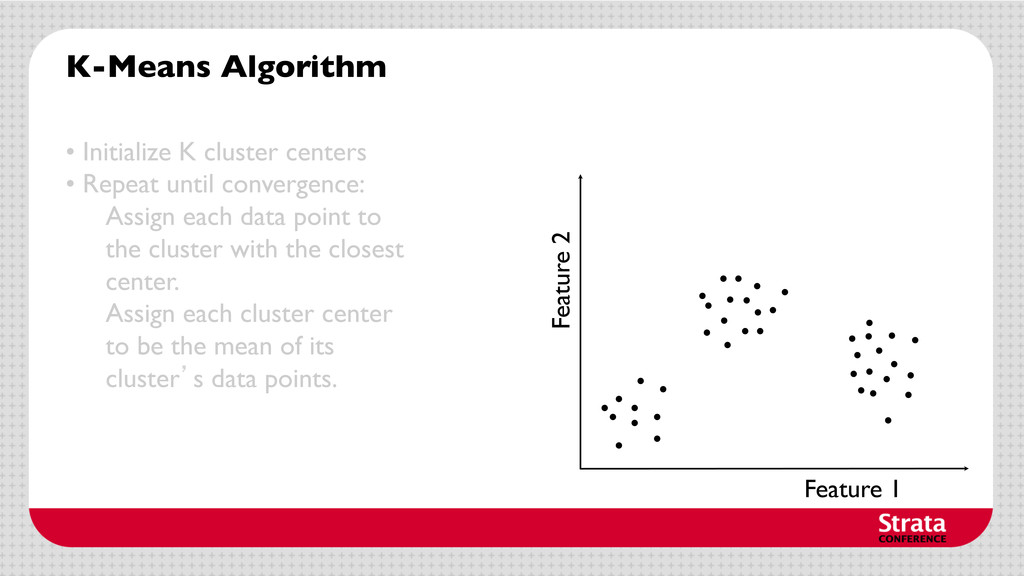
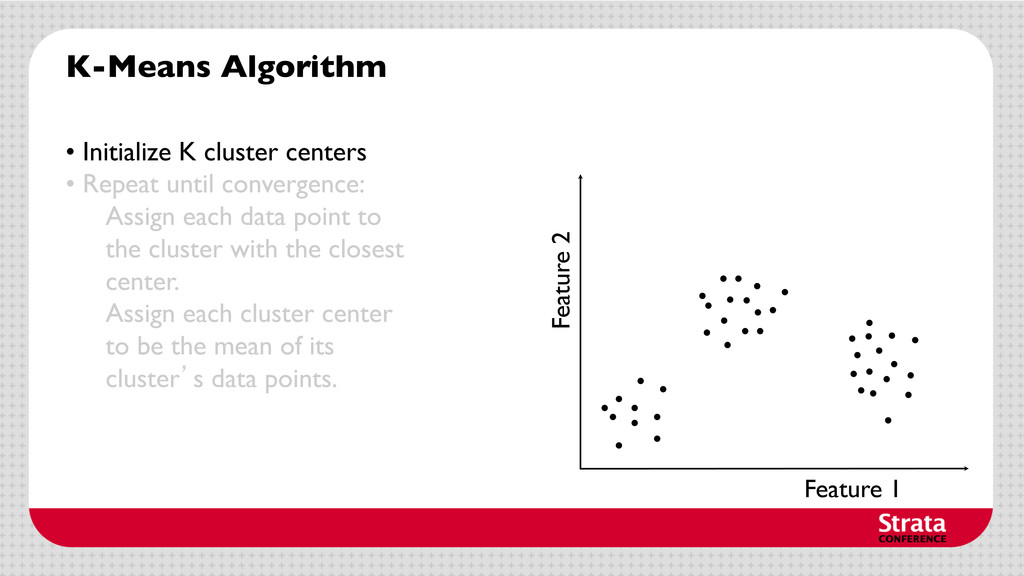
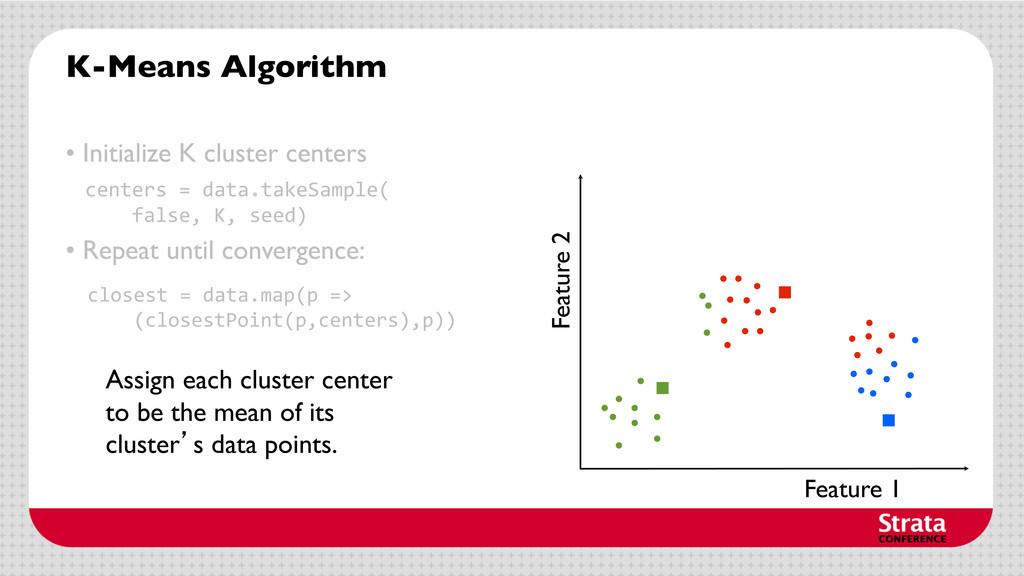
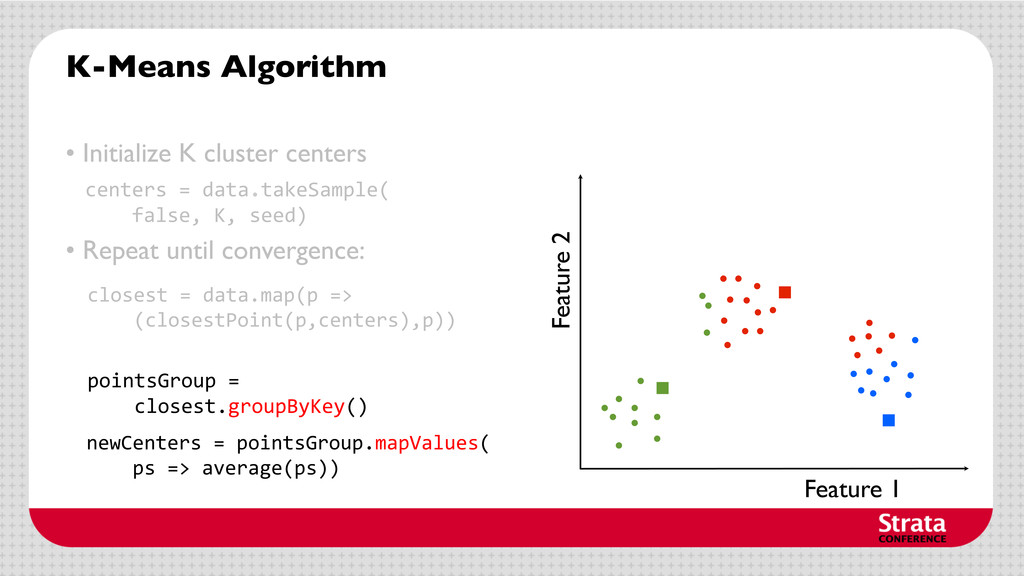
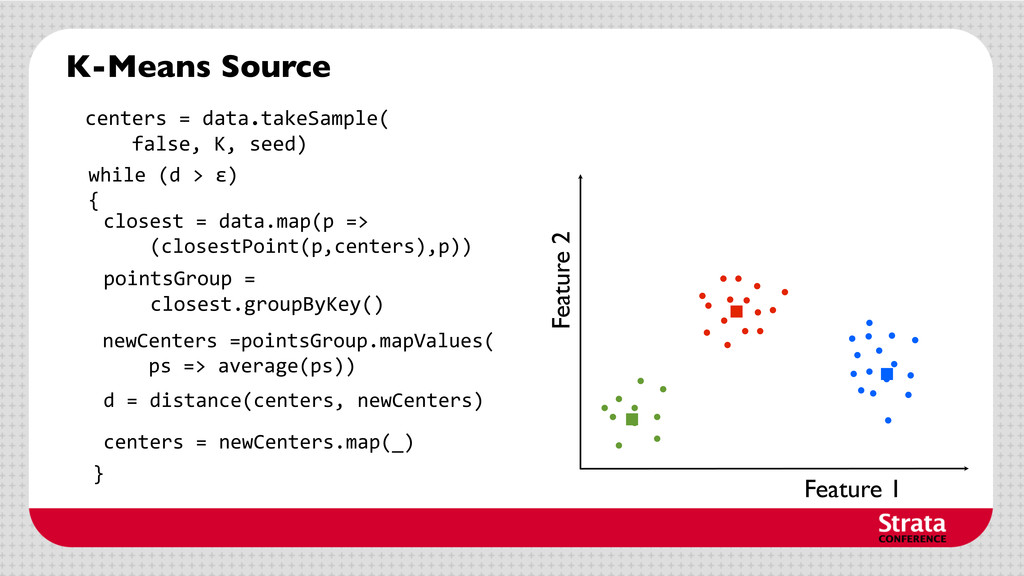
centers • Repeat until convergence: Assign each data point to the cluster with the closest center. Assign each cluster center to be the mean of its cluster’s data points.
centers • Repeat until convergence: Assign each data point to the cluster with the closest center. Assign each cluster center to be the mean of its cluster’s data points.
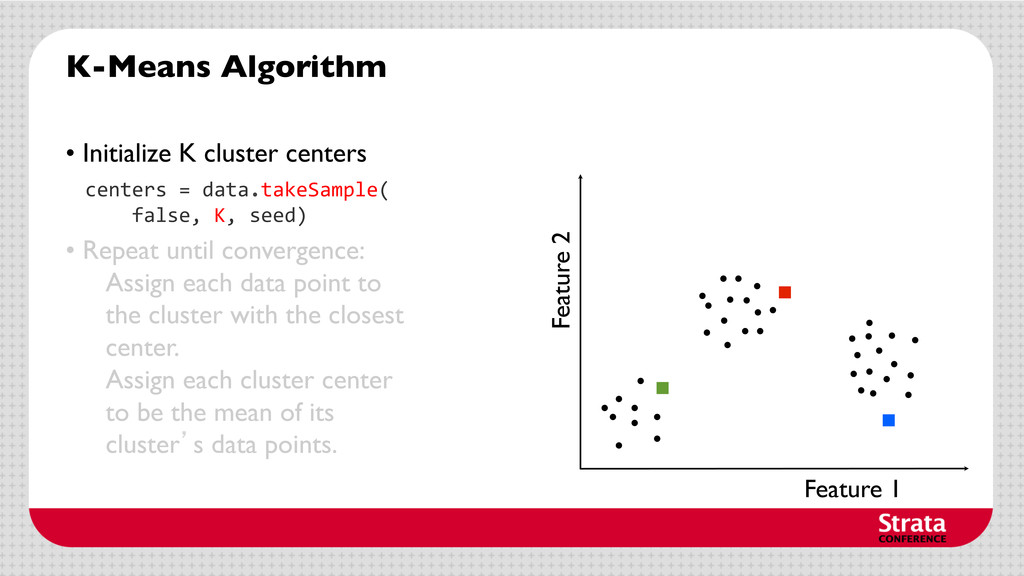
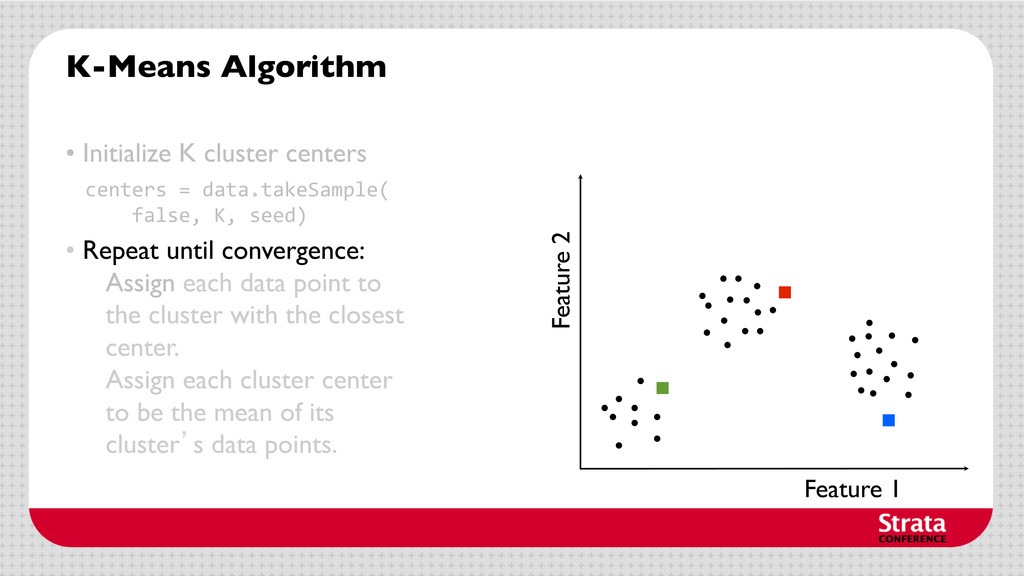
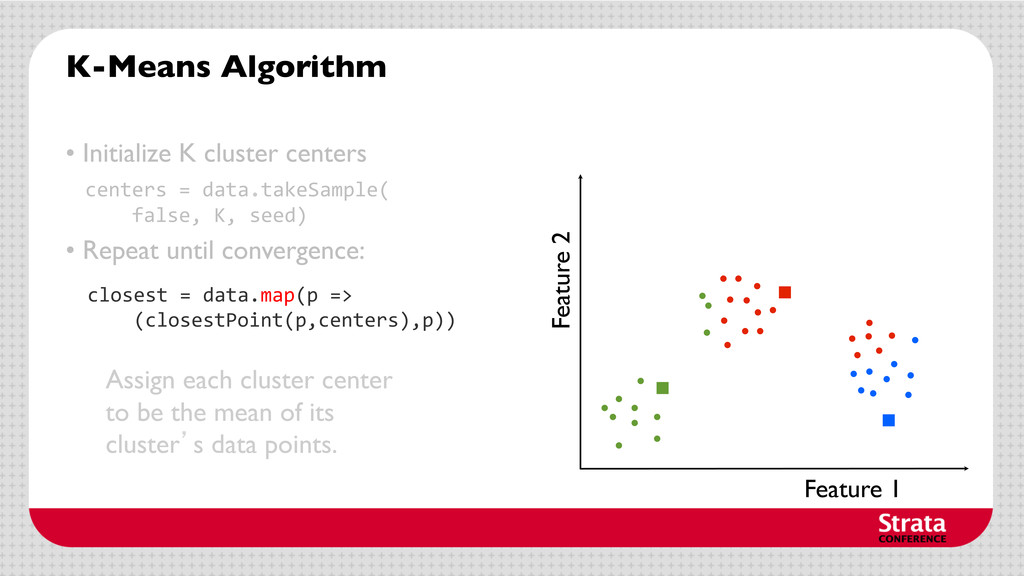
centers • Repeat until convergence: Assign each data point to the cluster with the closest center. Assign each cluster center to be the mean of its cluster’s data points. centers = data.takeSample( false, K, seed)
centers • Repeat until convergence: Assign each data point to the cluster with the closest center. Assign each cluster center to be the mean of its cluster’s data points. centers = data.takeSample( false, K, seed)
centers • Repeat until convergence: Assign each data point to the cluster with the closest center. Assign each cluster center to be the mean of its cluster’s data points. centers = data.takeSample( false, K, seed)
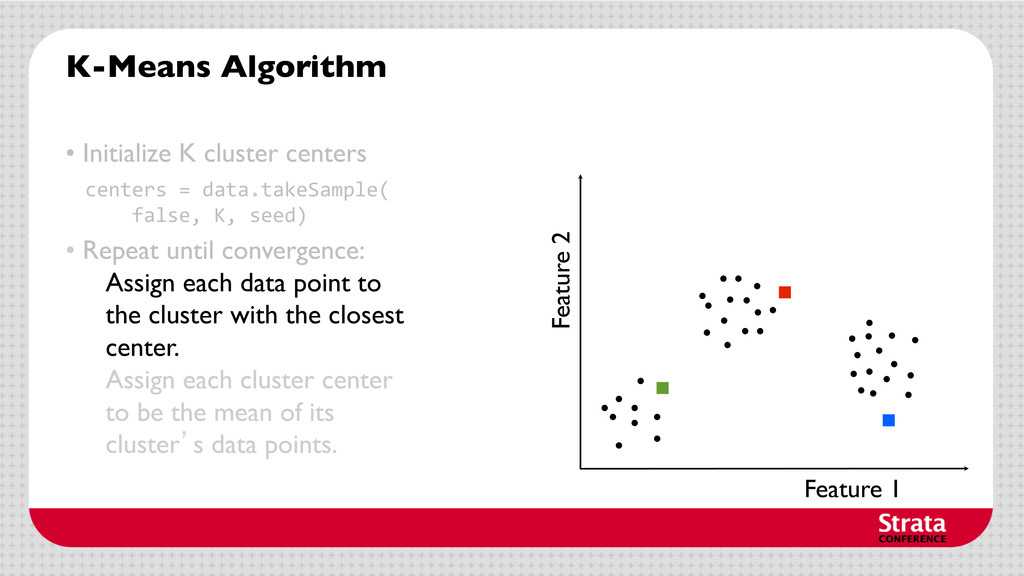
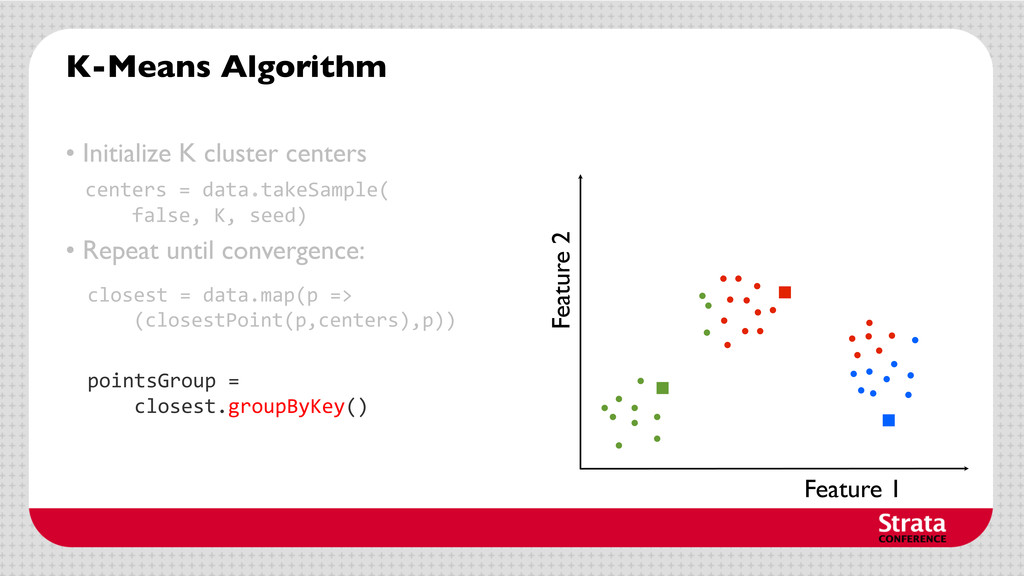
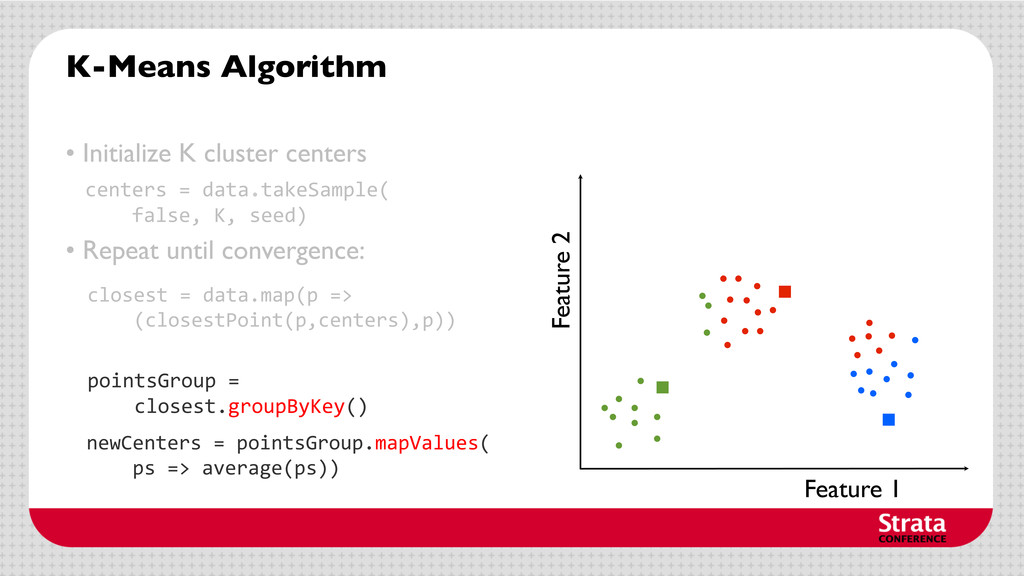
centers • Repeat until convergence: Assign each cluster center to be the mean of its cluster’s data points. centers = data.takeSample( false, K, seed) closest = data.map(p => (closestPoint(p,centers),p))
centers • Repeat until convergence: Assign each cluster center to be the mean of its cluster’s data points. centers = data.takeSample( false, K, seed) closest = data.map(p => (closestPoint(p,centers),p))
centers • Repeat until convergence: Assign each cluster center to be the mean of its cluster’s data points. centers = data.takeSample( false, K, seed) closest = data.map(p => (closestPoint(p,centers),p))
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}