def train(model: nn.Module, epochs: int, trainloader: DataLoader) -> List[float]: losses = [] for epoch in range(epochs): average_loss = train_once(model, trainloader) losses.append(average_loss) model.save() return losses def evaluate(model_path: str, testloader: DataLoader) -> List[float]: predictor = Model(model_path) evaluations = predictor.evaluate(testloader) return evaluations • 少量データで普通のテストを動かす。 @pytest.mark.parametrize( (“model”, “train_path”, “test_path” “epochs”), [(model, “/tmp/small_train/”, “/tmp/small_test/”, 10)], ) def test_train( model: nn.Module, train_path: str, test_path: str, epochs: int, ): trainloader = make_dataloader(train_path) testloader = make_dataloader(test_path) init_accuracy = evaluate(model, testloader) losses = train(model, epochs, trainloader) assert losses[0] > losses[-1] trained_accuracy = evaluate(model, testdata) assert init_accuracy < trained_accuracy 23
{kind=link}
{kind=link}
{kind=link}
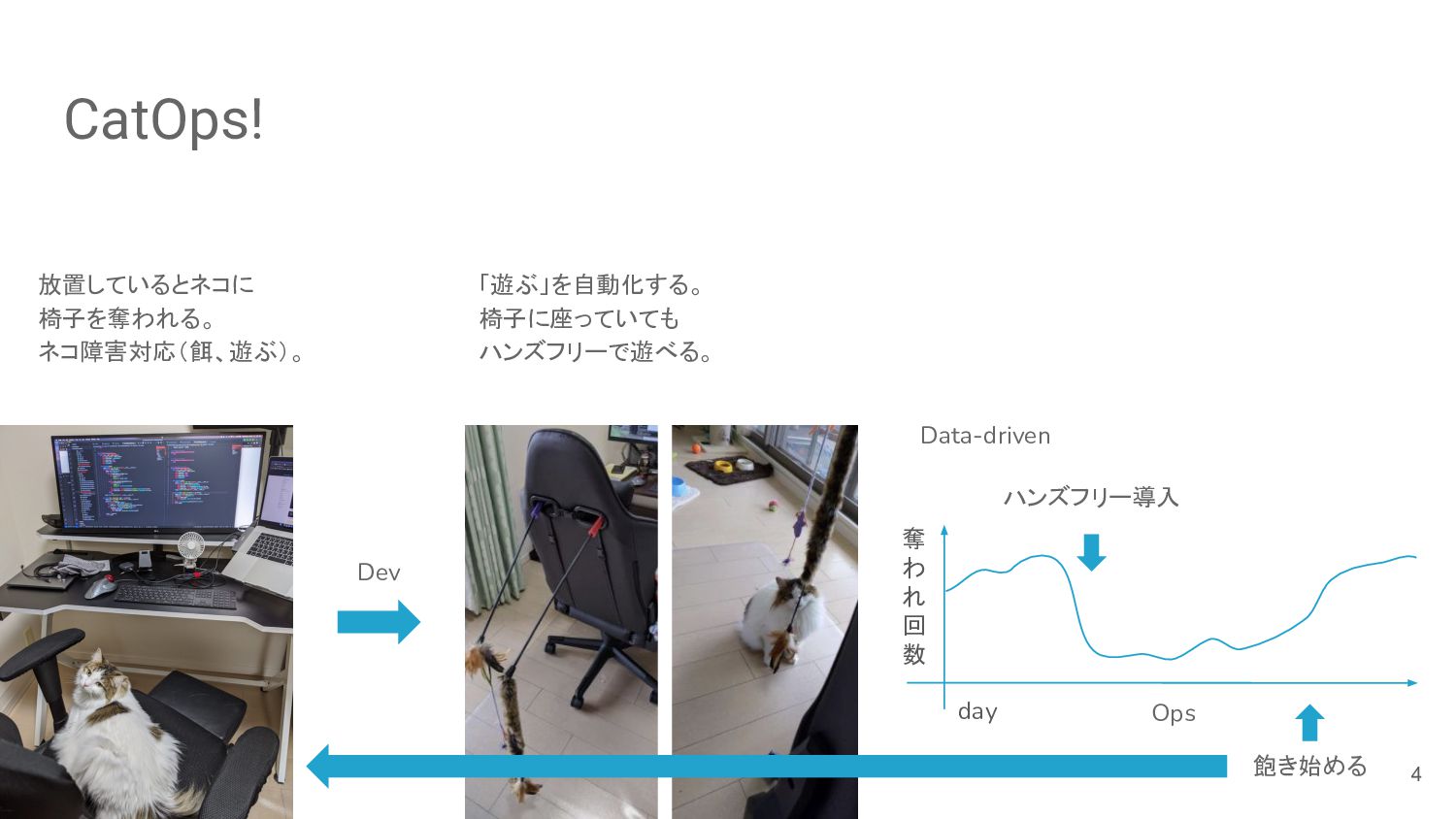{kind=link}
{kind=link}
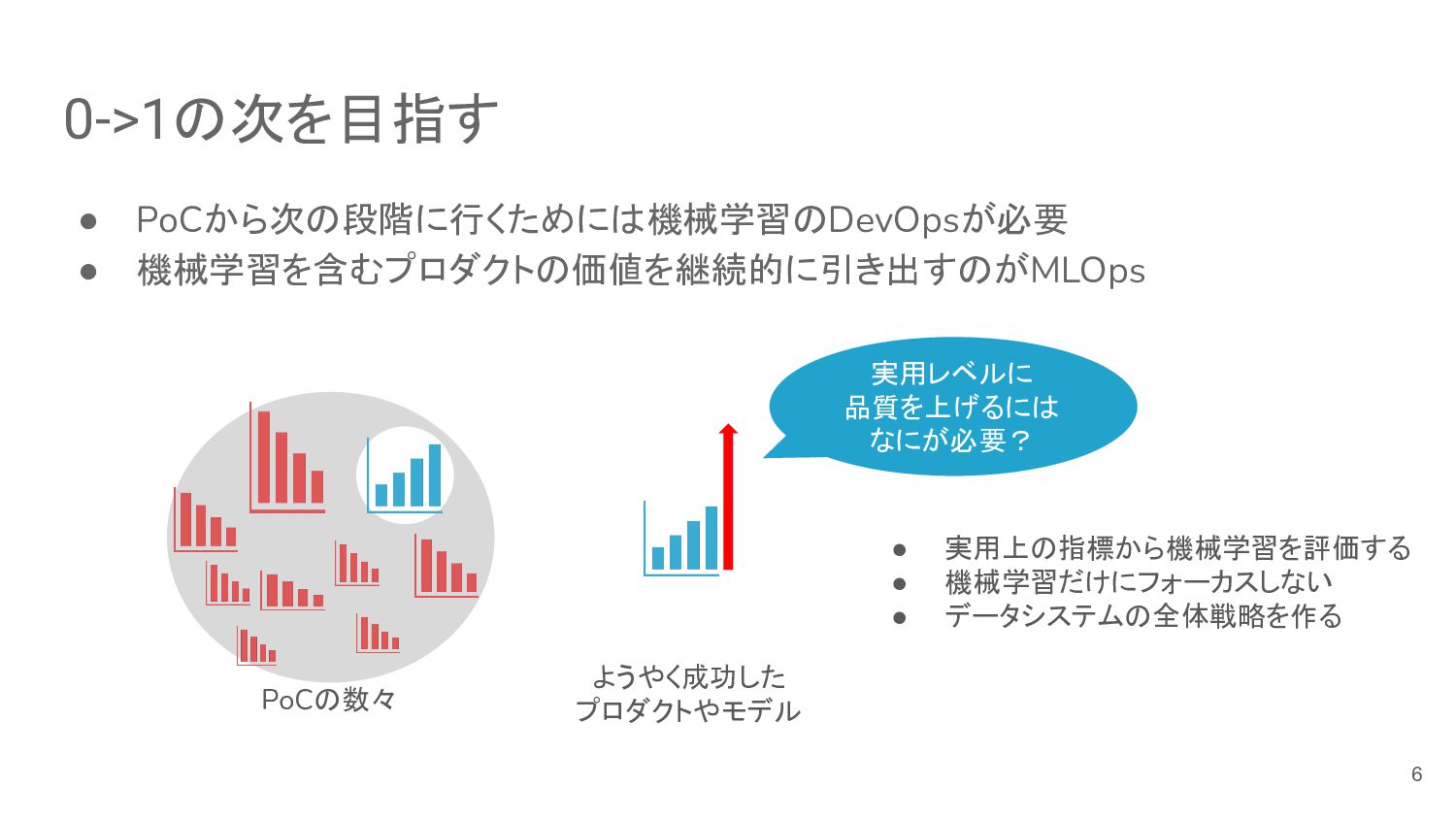{kind=link}
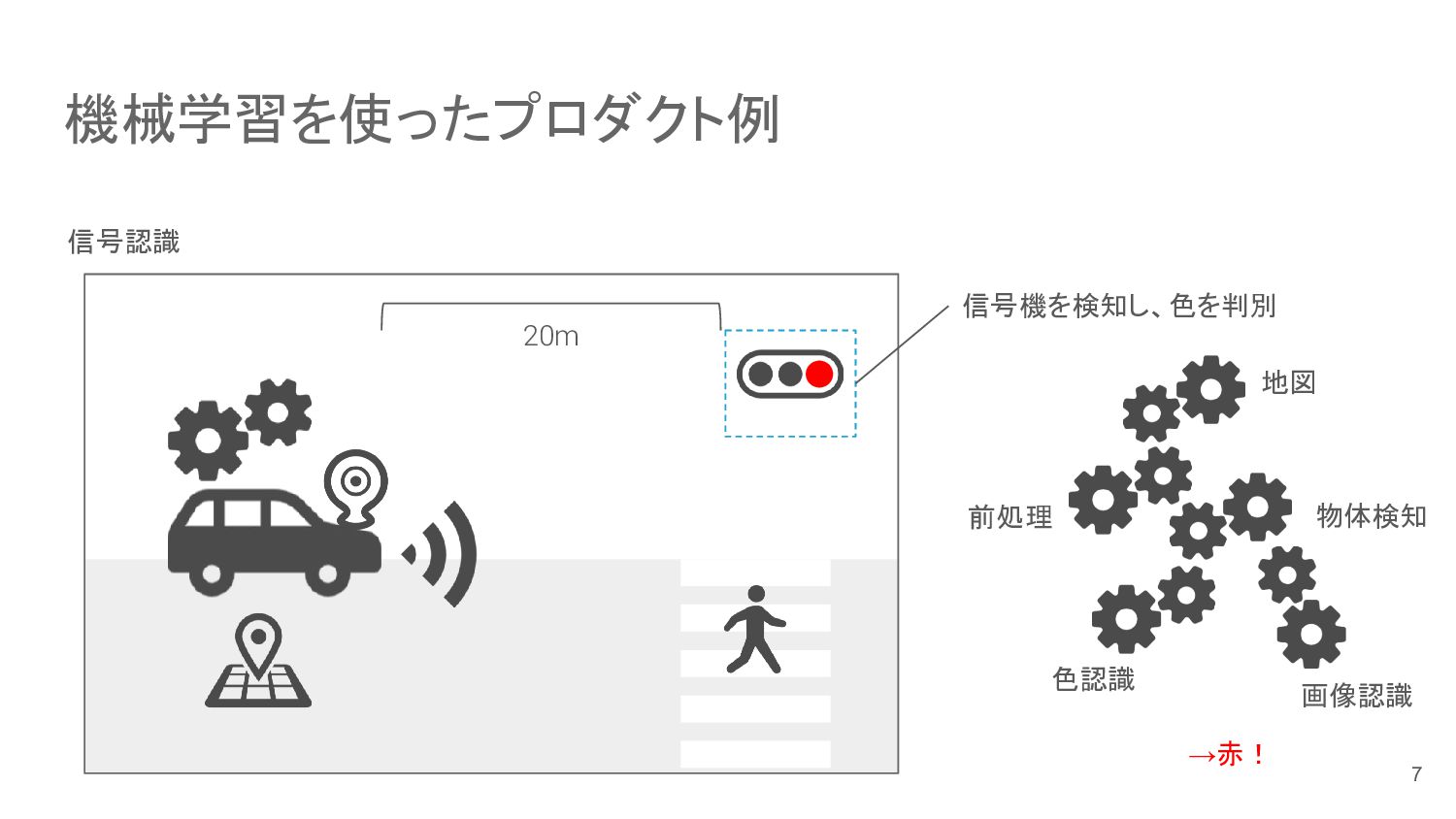{kind=link}
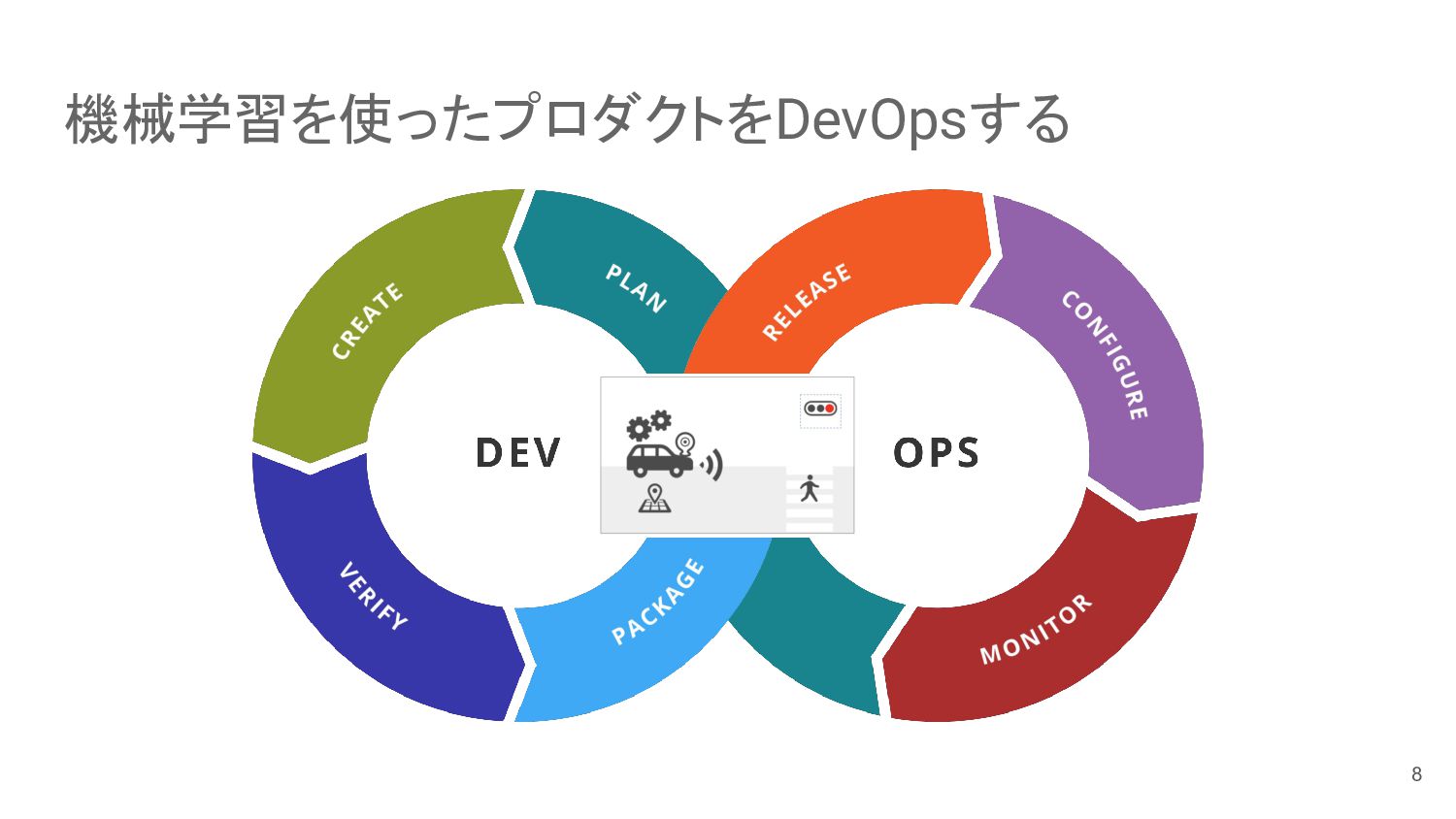{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
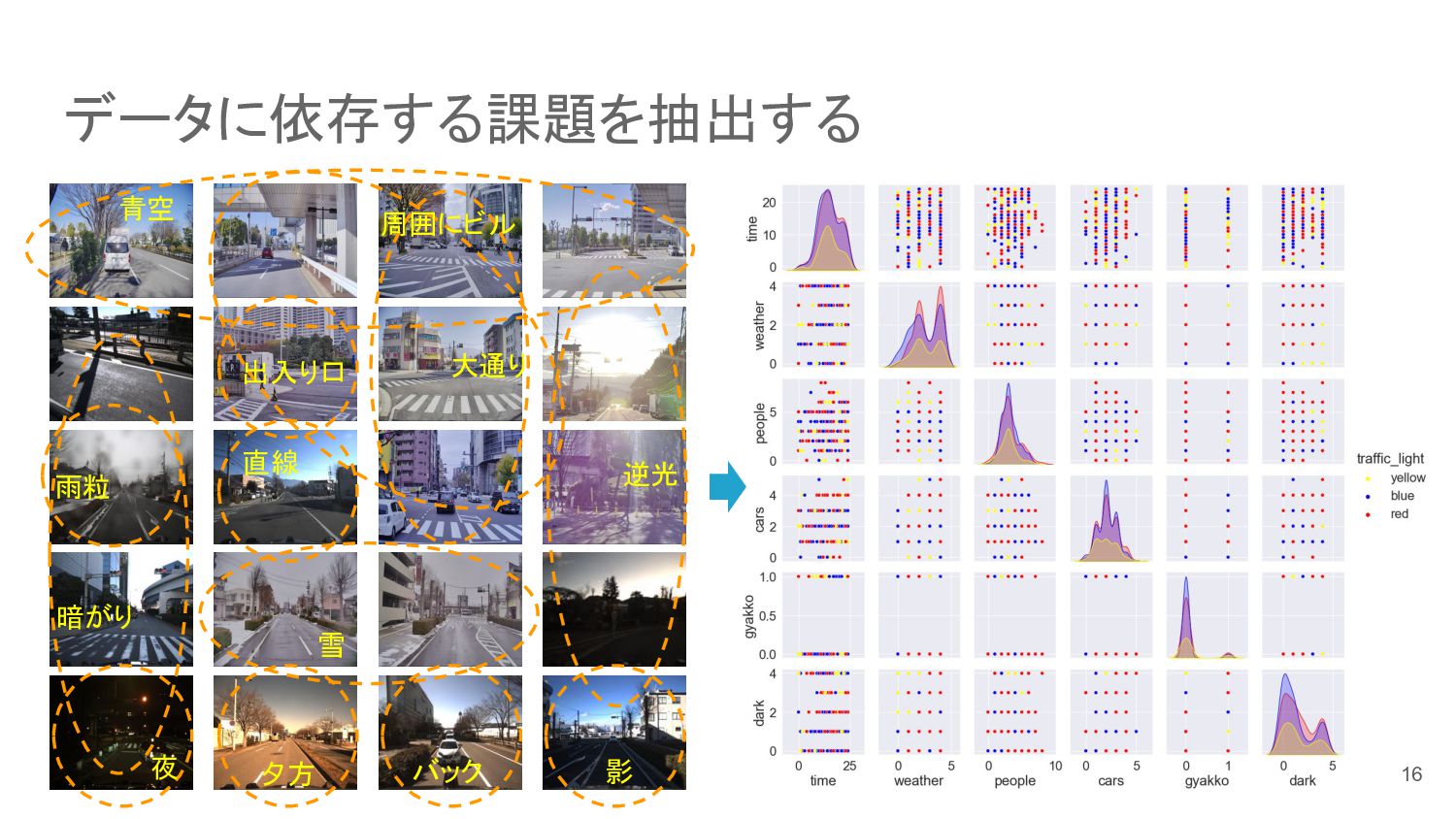{kind=link}
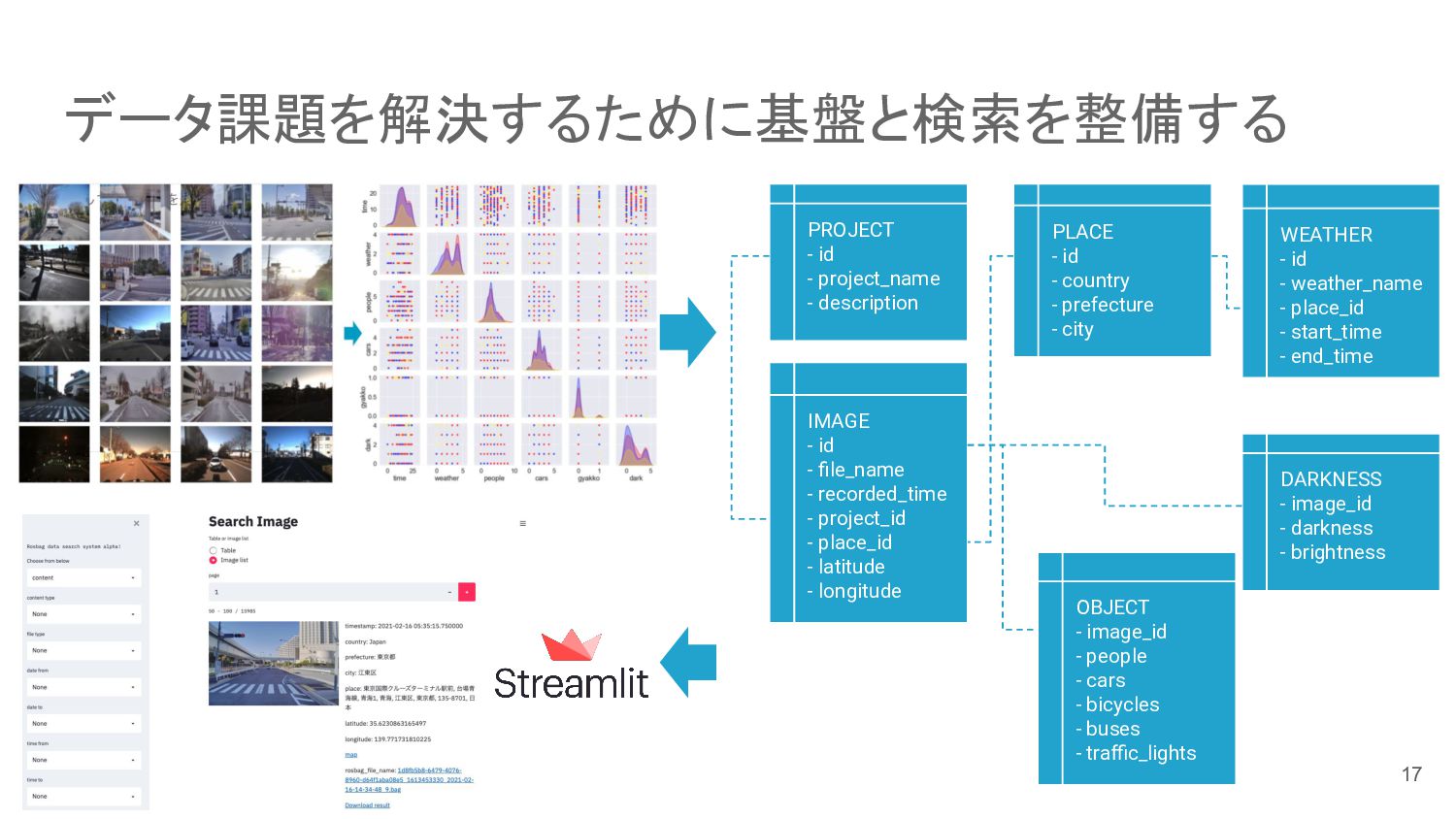{kind=link}
{kind=link}
{kind=link}
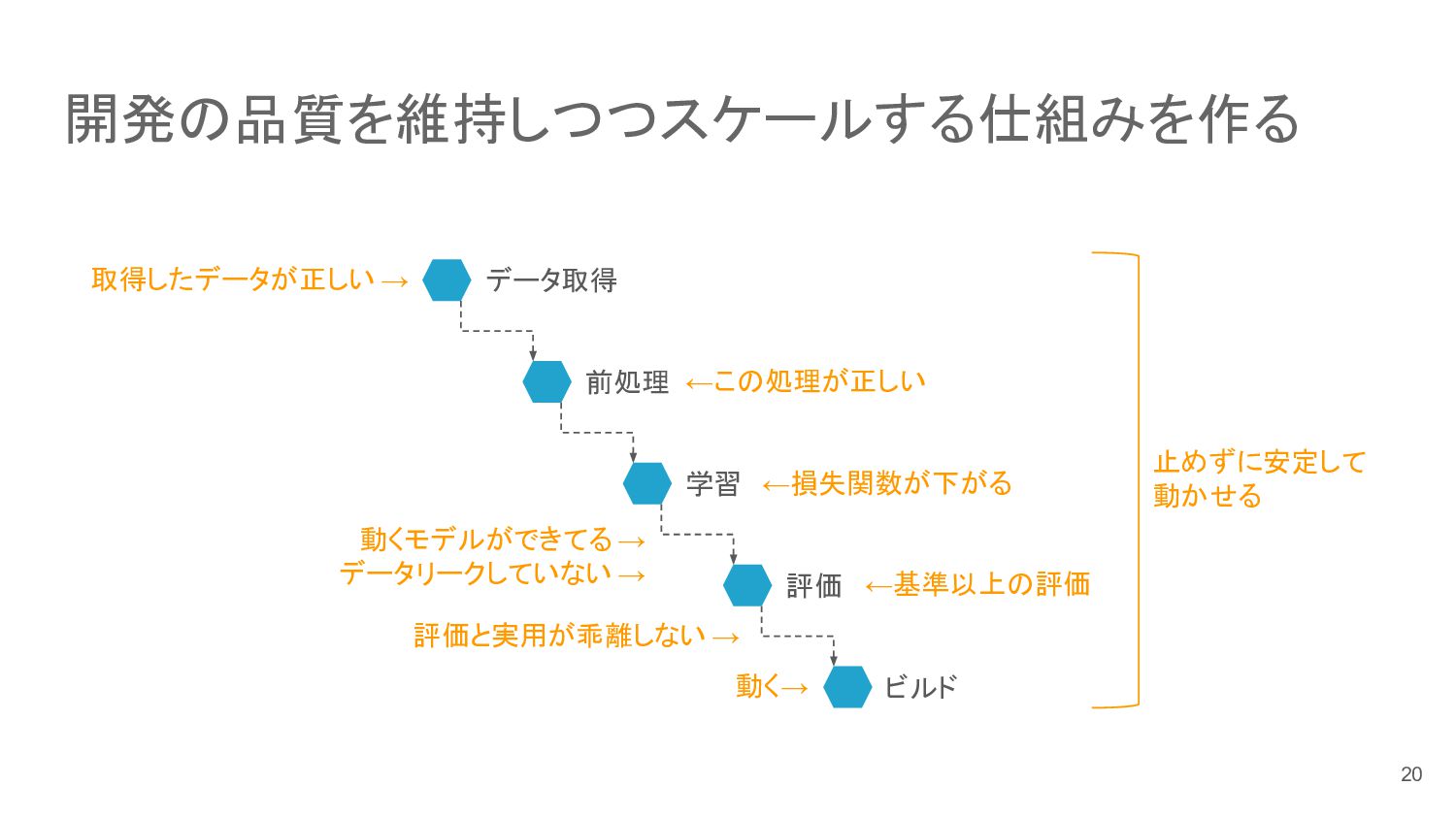{kind=link}
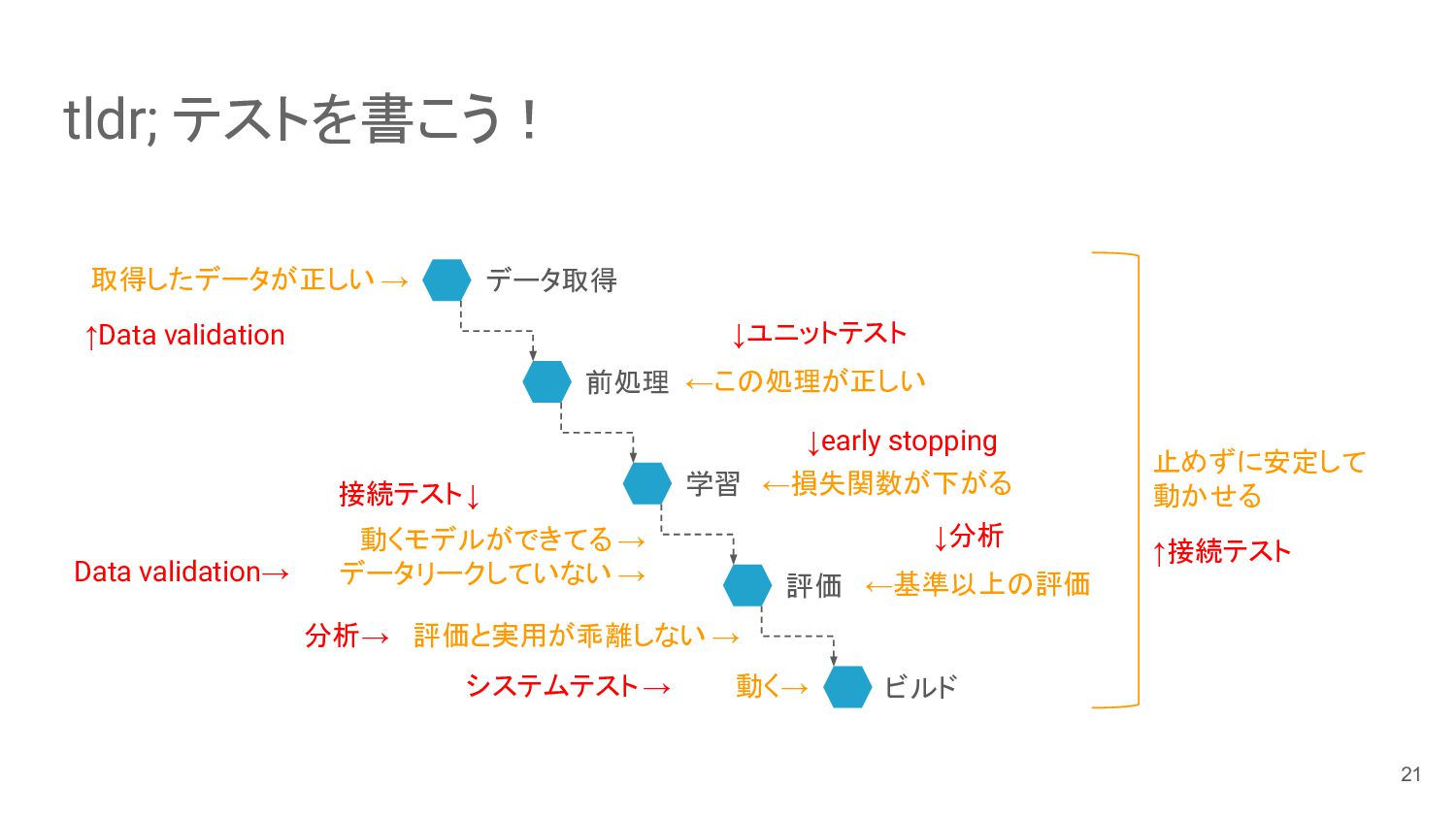{kind=link}
{kind=link}
{kind=link}
{kind=link}
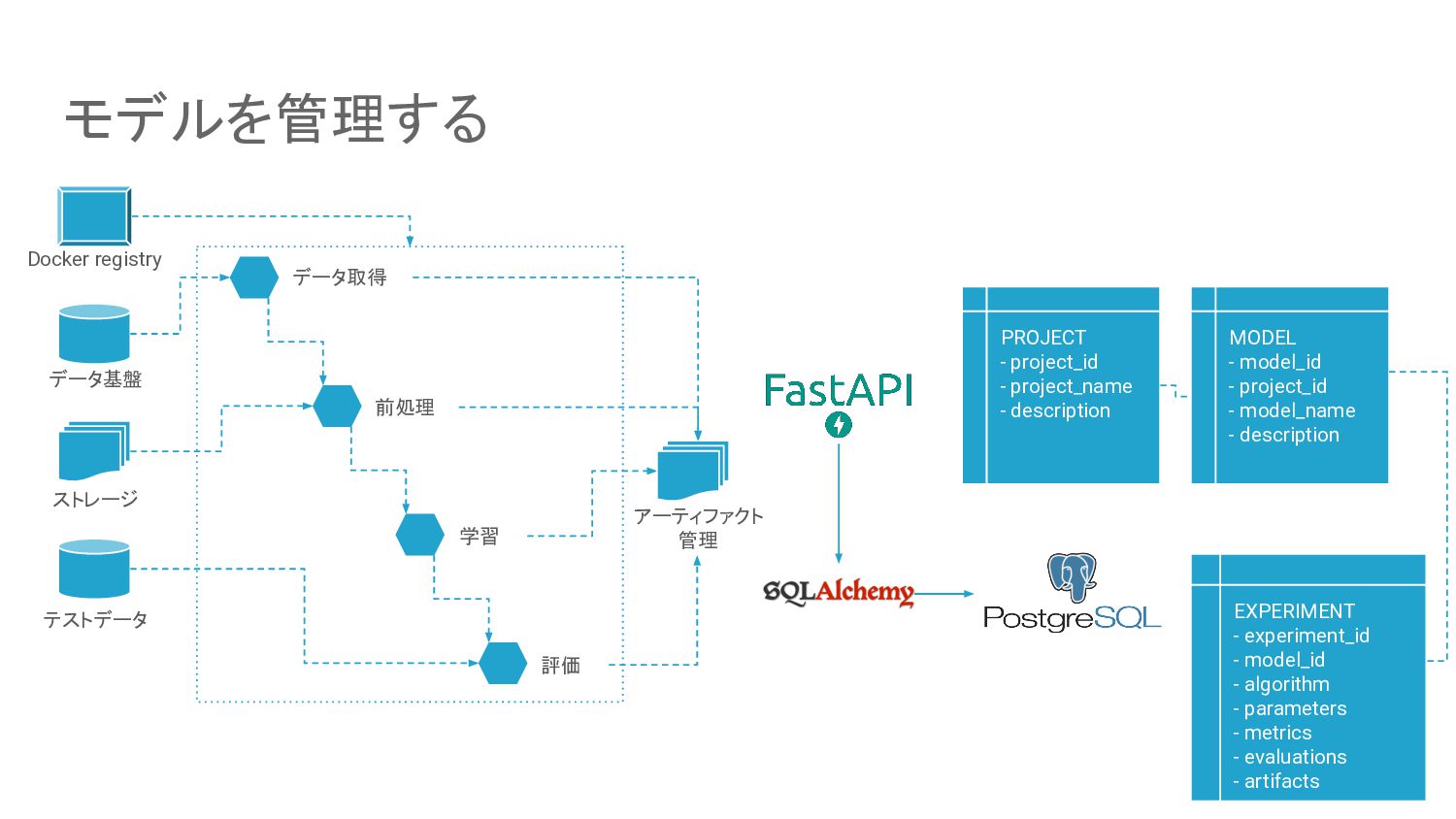{kind=link}
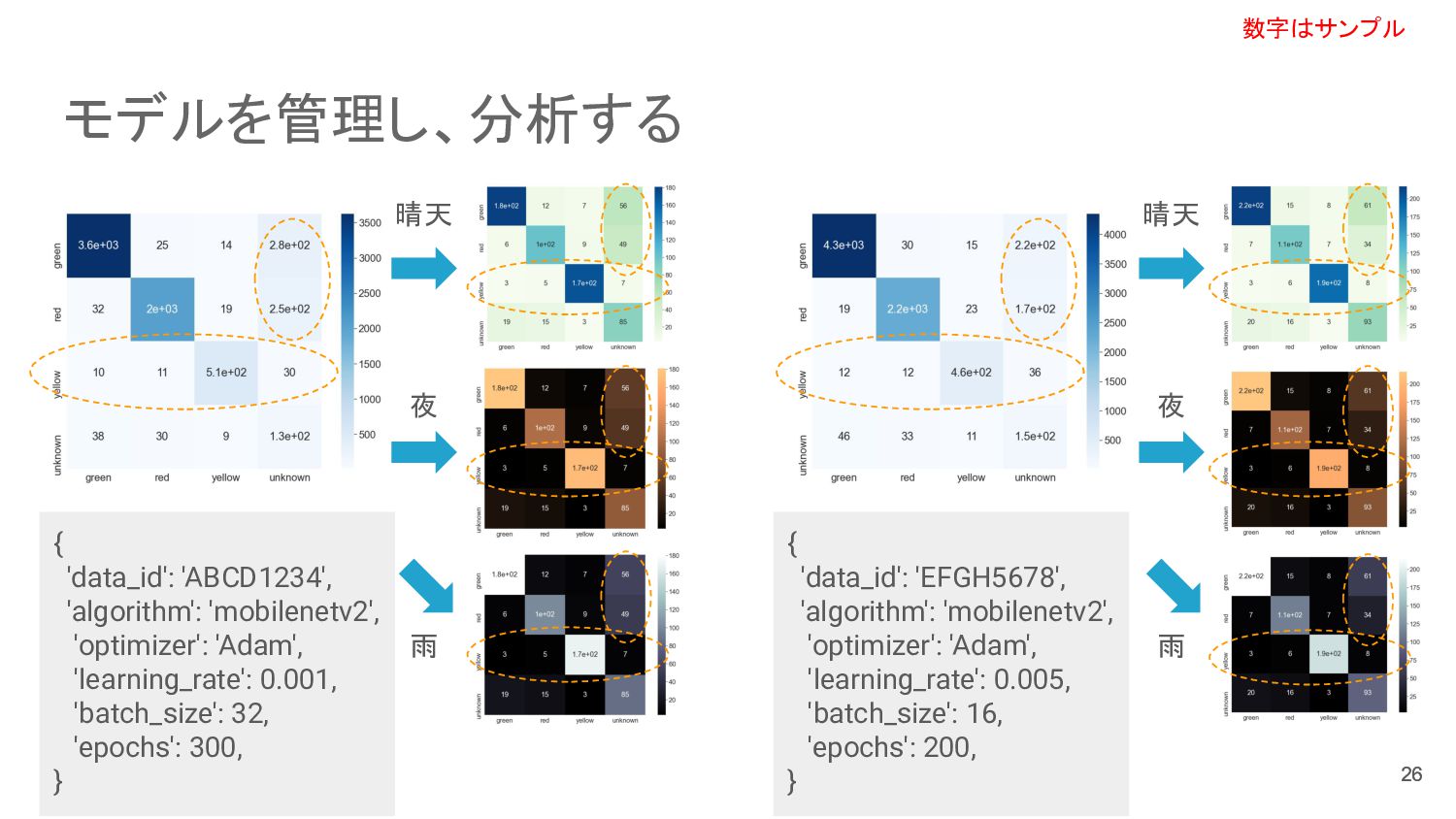{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
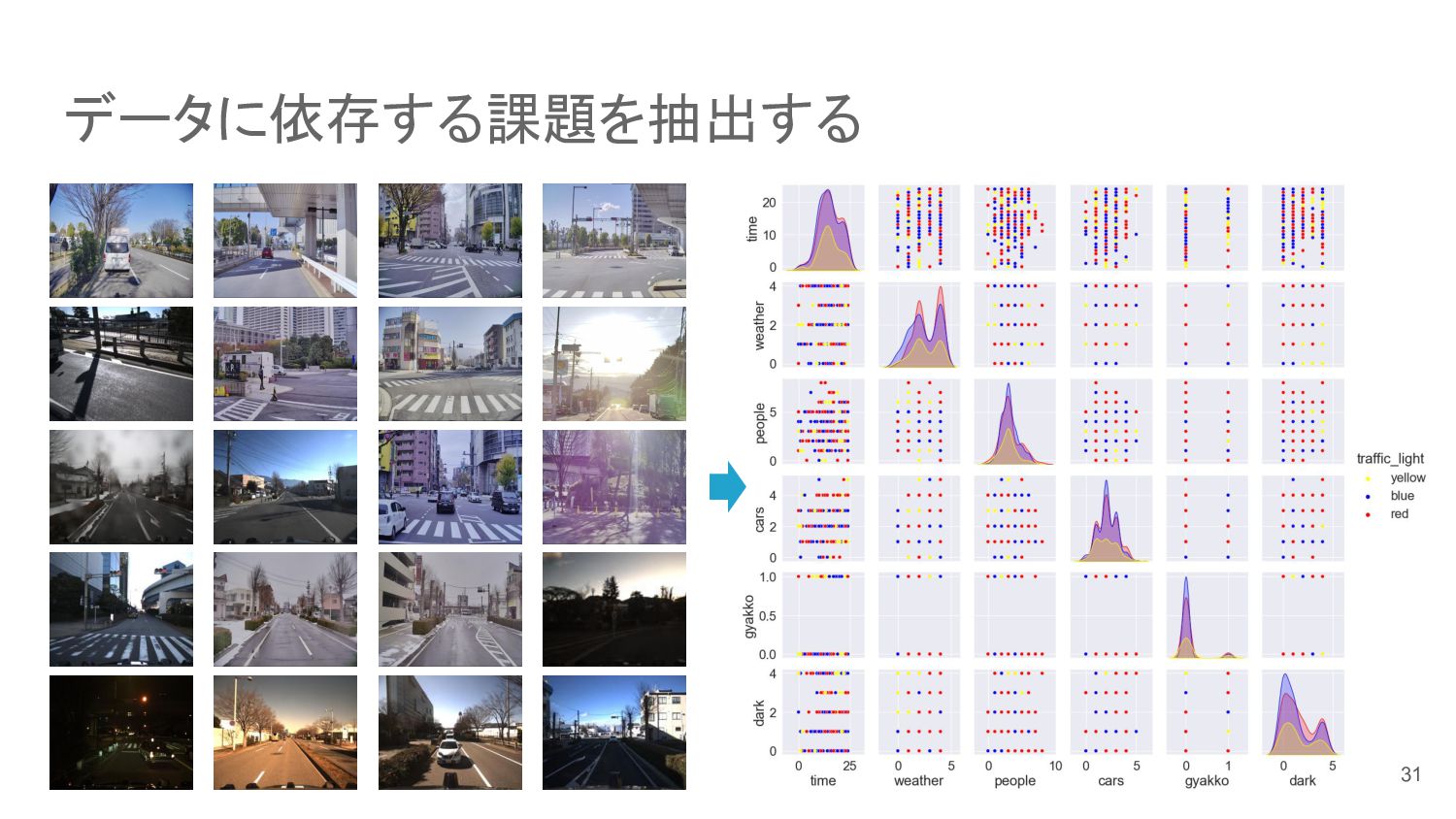{kind=link}
{kind=link}