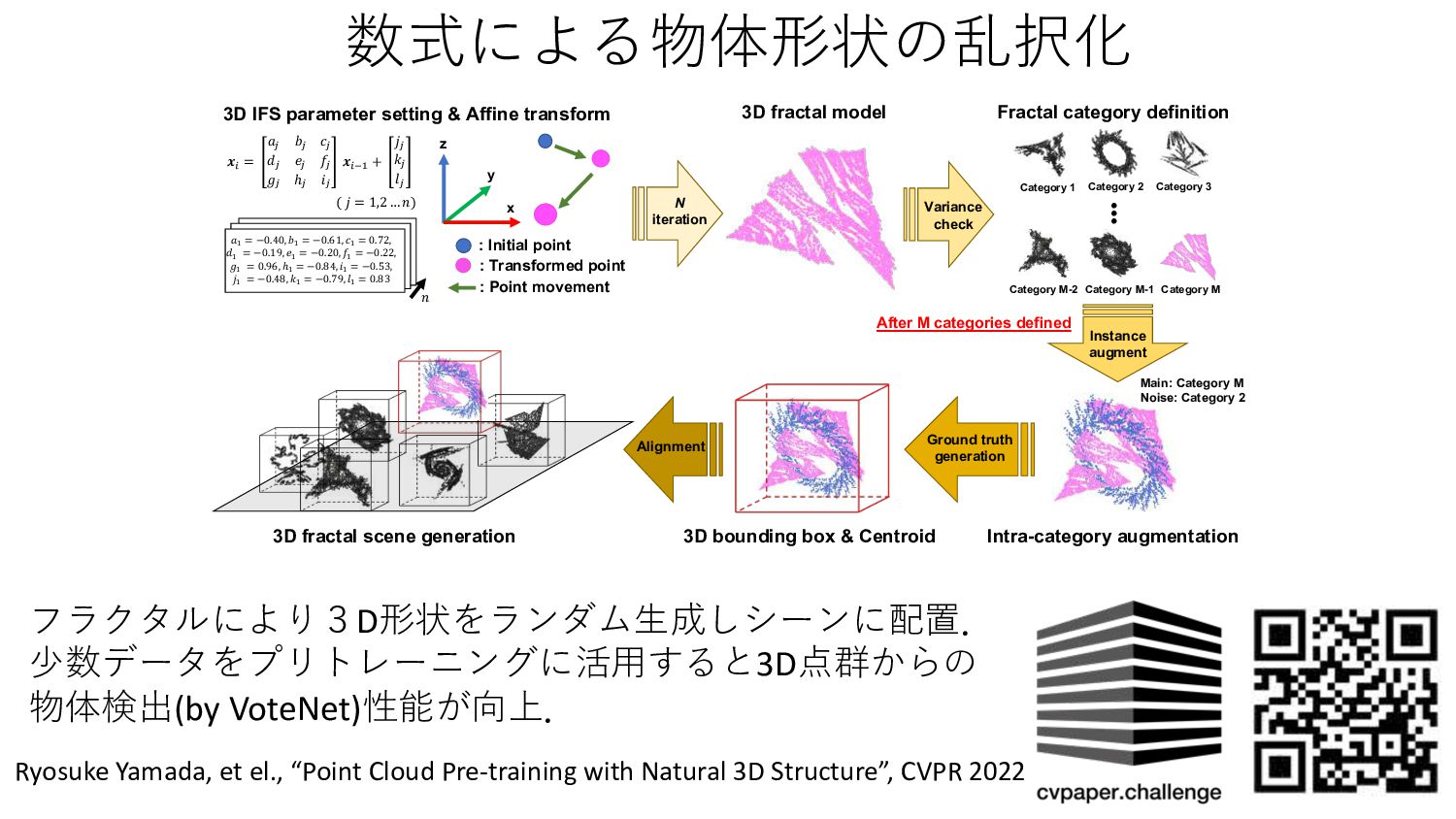
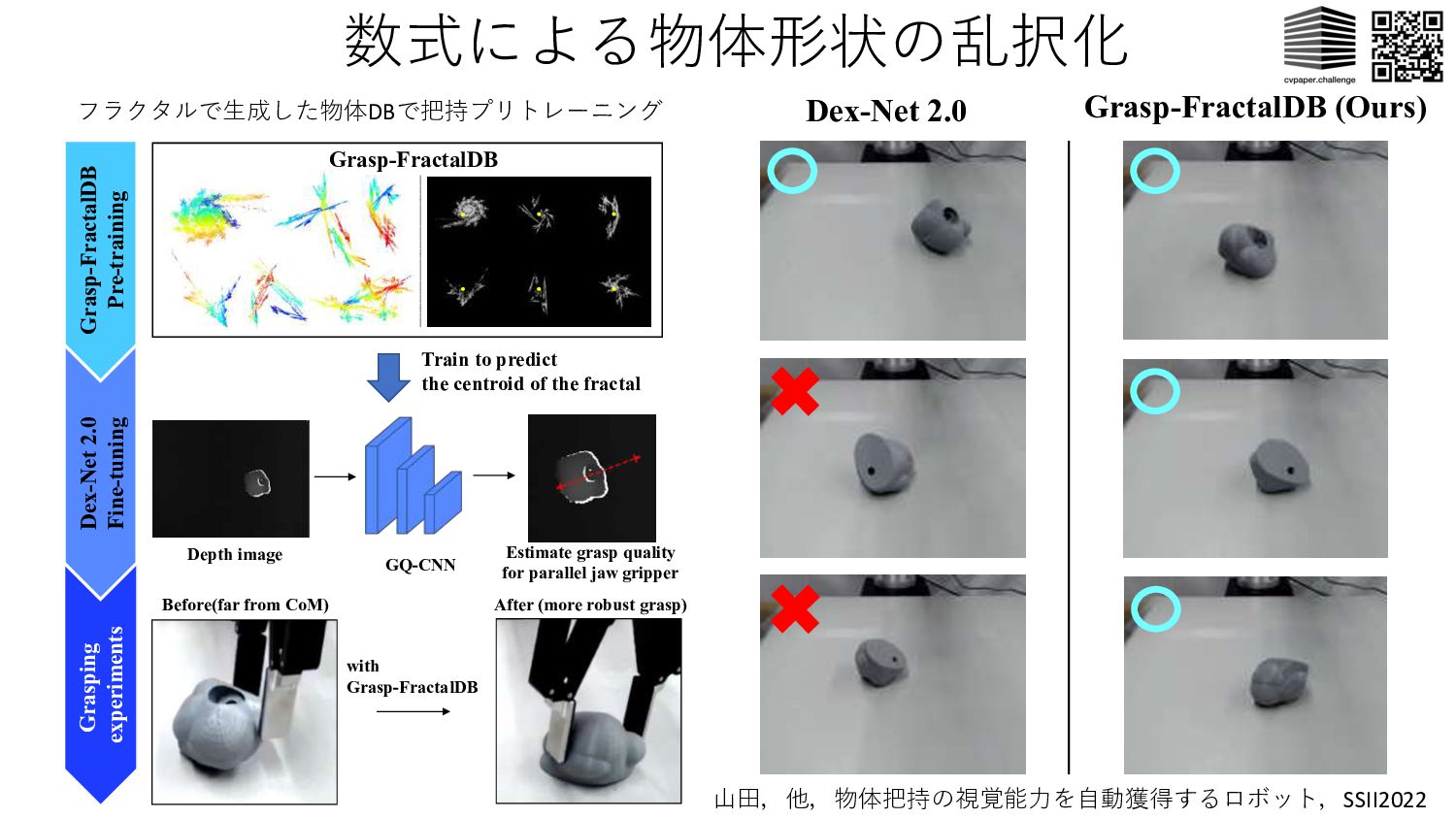
3D fractal model Variance check Ground truth generation N iteration Alignment 3D bounding box & Centroid 3D fractal scene generation 3D IFS parameter setting & Affine transform x y z Intra-category augmentation !! = $" %" &" '" (" )" *" ℎ" ," !!#$ + ." /" 0" !! = −0.40, (! = −0.61, +! = 0.72, /! = −0.19, 1! = −0.20, 2! = −0.22, 3! = 0.96, ℎ! = −0.84, 6! = −0.53, 9! = −0.48, :! = −0.79, ;! = 0.83 1 ( . = 1,2 … 1) After M categories defined Category 1 ••• Category M-2 Category M-1 Category M Category 2 Category 3 Fractal category definition Main: Category M Noise: Category 2 Instance augment フラクタルにより3D形状をランダム⽣成しシーンに配置. 少数データをプリトレーニングに活⽤すると3D点群からの 物体検出(by VoteNet)性能が向上. Ryosuke Yamada, et el., “Point Cloud Pre-training with Natural 3D Structure”, CVPR 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“⾒え”の乱拓化 レンダリングを⼀様にランダム化. 実世界の視覚的変動にロバストに対処. 積み⽊のピッキングを実現[1]. [1] Domain randomization for transferring deep](https://files.speakerdeck.com/presentations/a433516c1a6942ff9400fad98a1aa258/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
![“動き”の乱択化 物体やロボットの質量・⼨法 摩擦、制御ゲイン(PID),観測ノイズ, 関節の制約などの物理ダイナミクスに関する パラメタを乱択化しながらタスク学習. [1808.00177] Learning Dexterous In-Hand Manipulation](https://files.speakerdeck.com/presentations/a433516c1a6942ff9400fad98a1aa258/slide_13.jpg){kind=link}
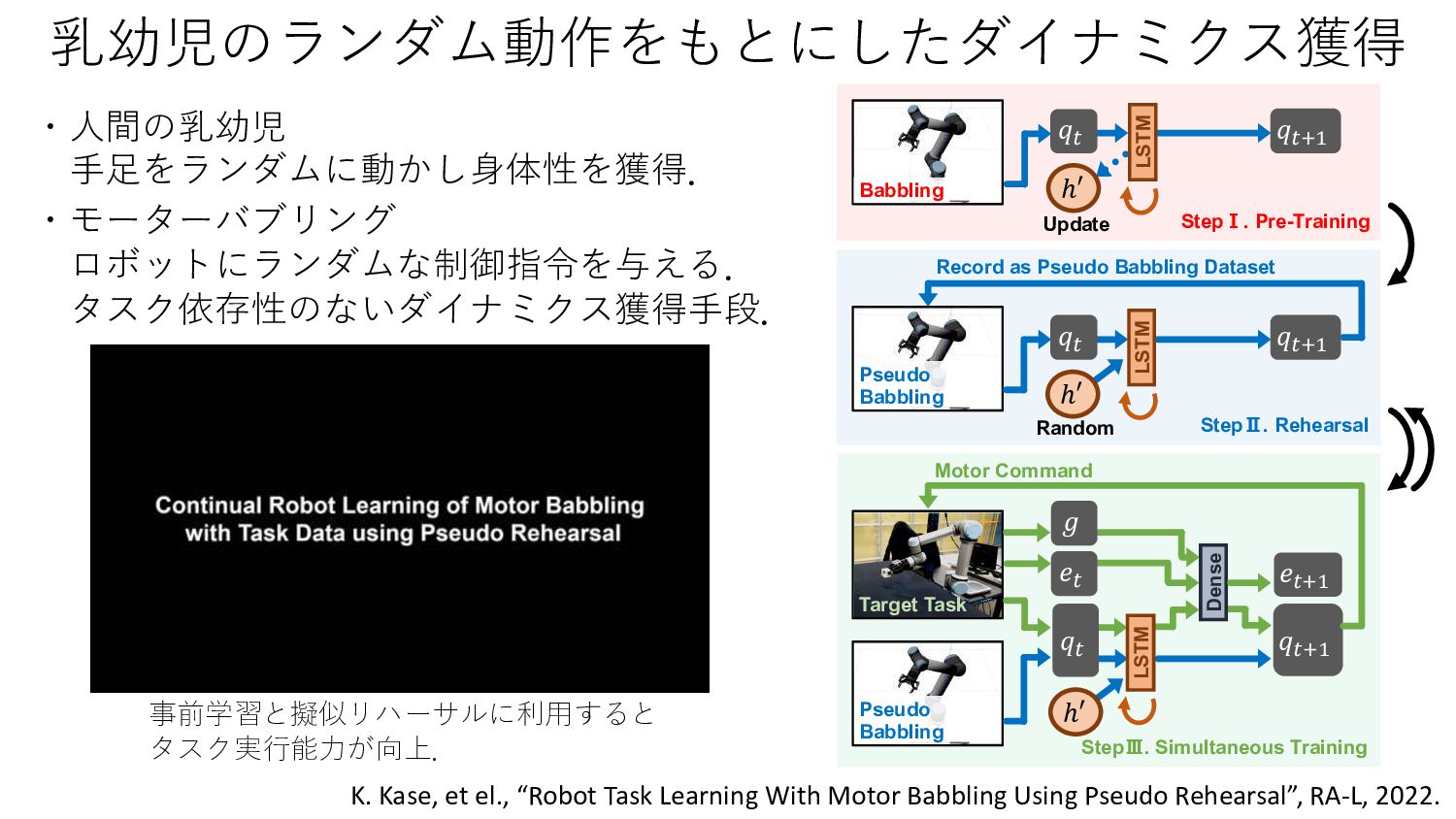{kind=link}
{kind=link}
{kind=link}
{kind=link}
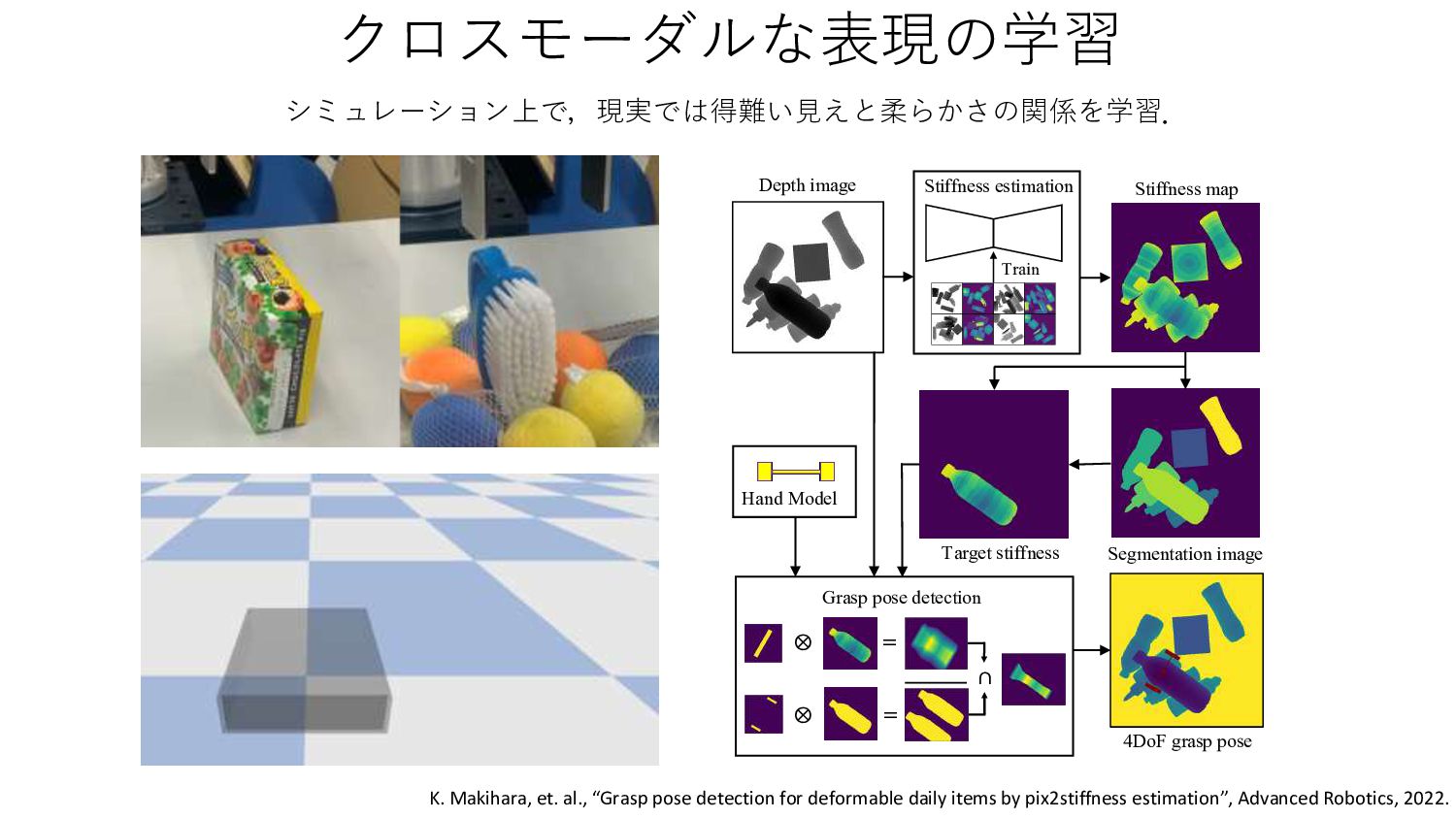{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}