Künstliche Intelligenz (KI) revolutioniert Geschäftsmodelle und -prozesse, erfordert aber gleichzeitig neue Paradigmen in der zugrundeliegenden IT-Infrastruktur.
Im Vortrag beleuchten Wolfgang und Kerstin unter anderem spezifische Anforderungen in den Phasen Training und Inferenz, erklären, warum herkömmliche Storage-Lösungen scheitern (müssen), und zeigen sinnvolle Ansätze für den Betrieb einer optimalen Infrastruktur für KI-Workloads auf.
Dabei konzentrieren sie sich auf die Bereiche Storage, Memory und Speichernetzwerk. Es werden technologische Optionen und Architekturbeispiele vorgestellt. Führungskräfte und technische Verantwortliche erhalten Hinweise für die Auswahl und Beschaffung geeigneter Produkte.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
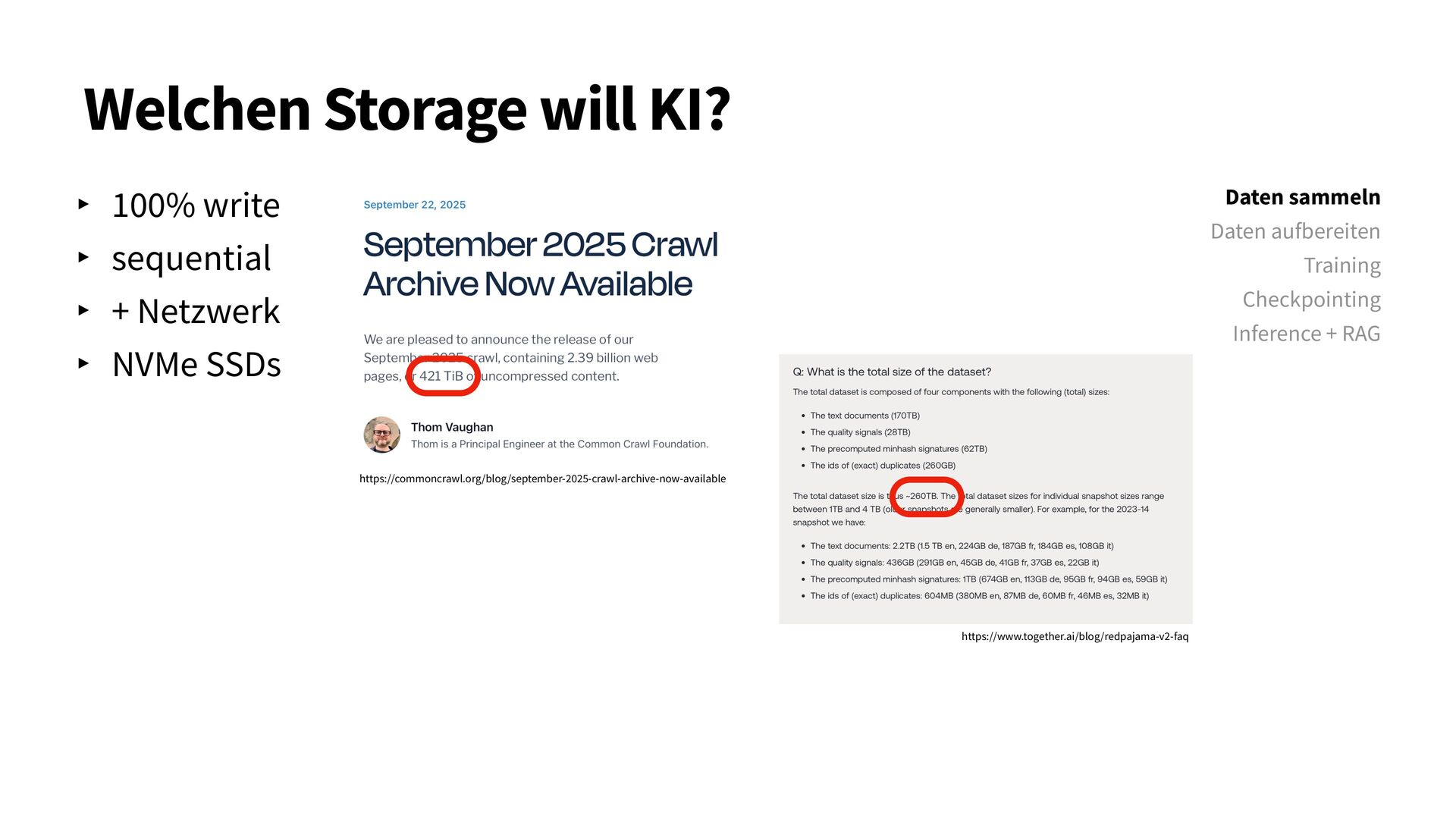{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
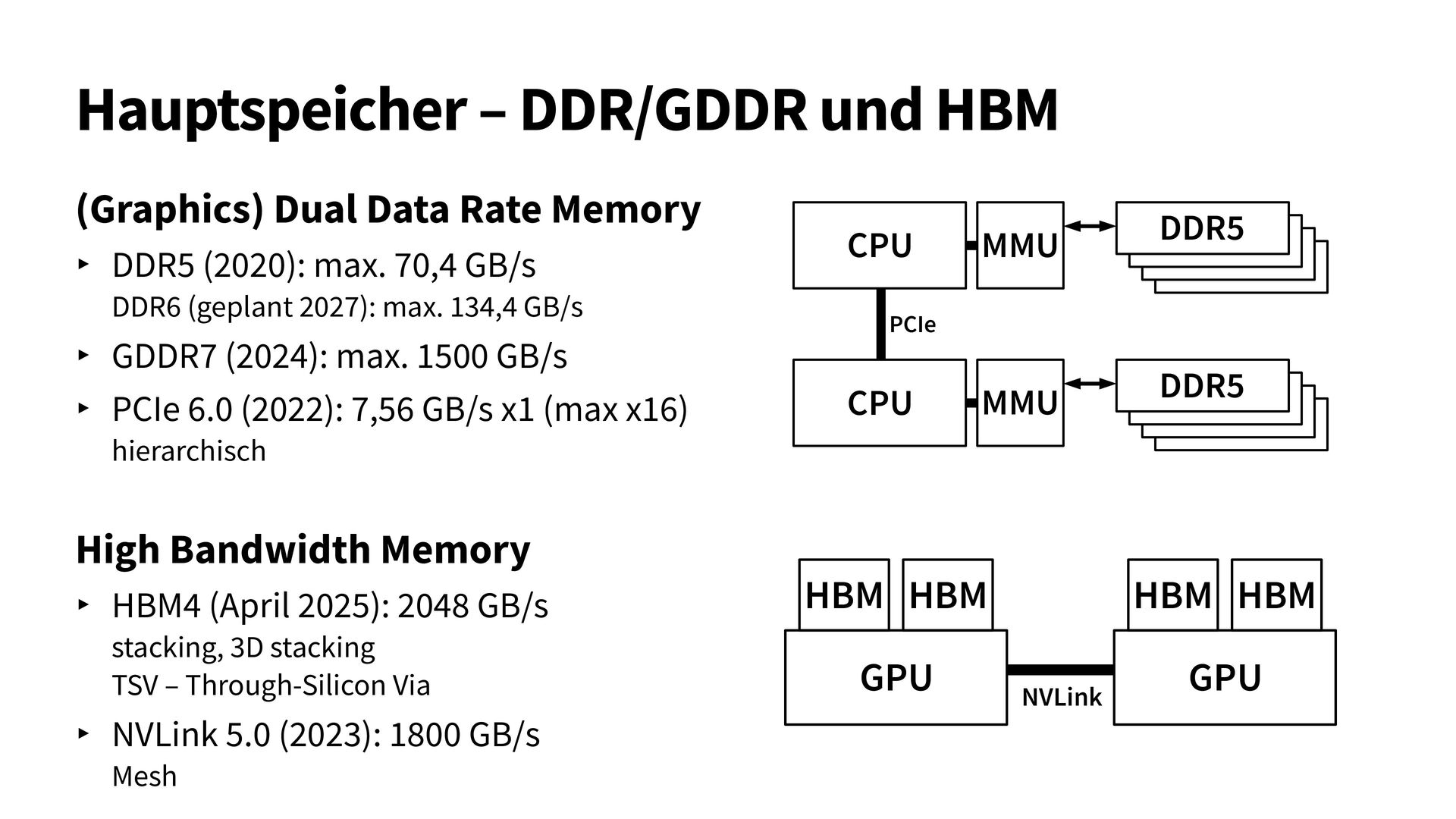{kind=link}
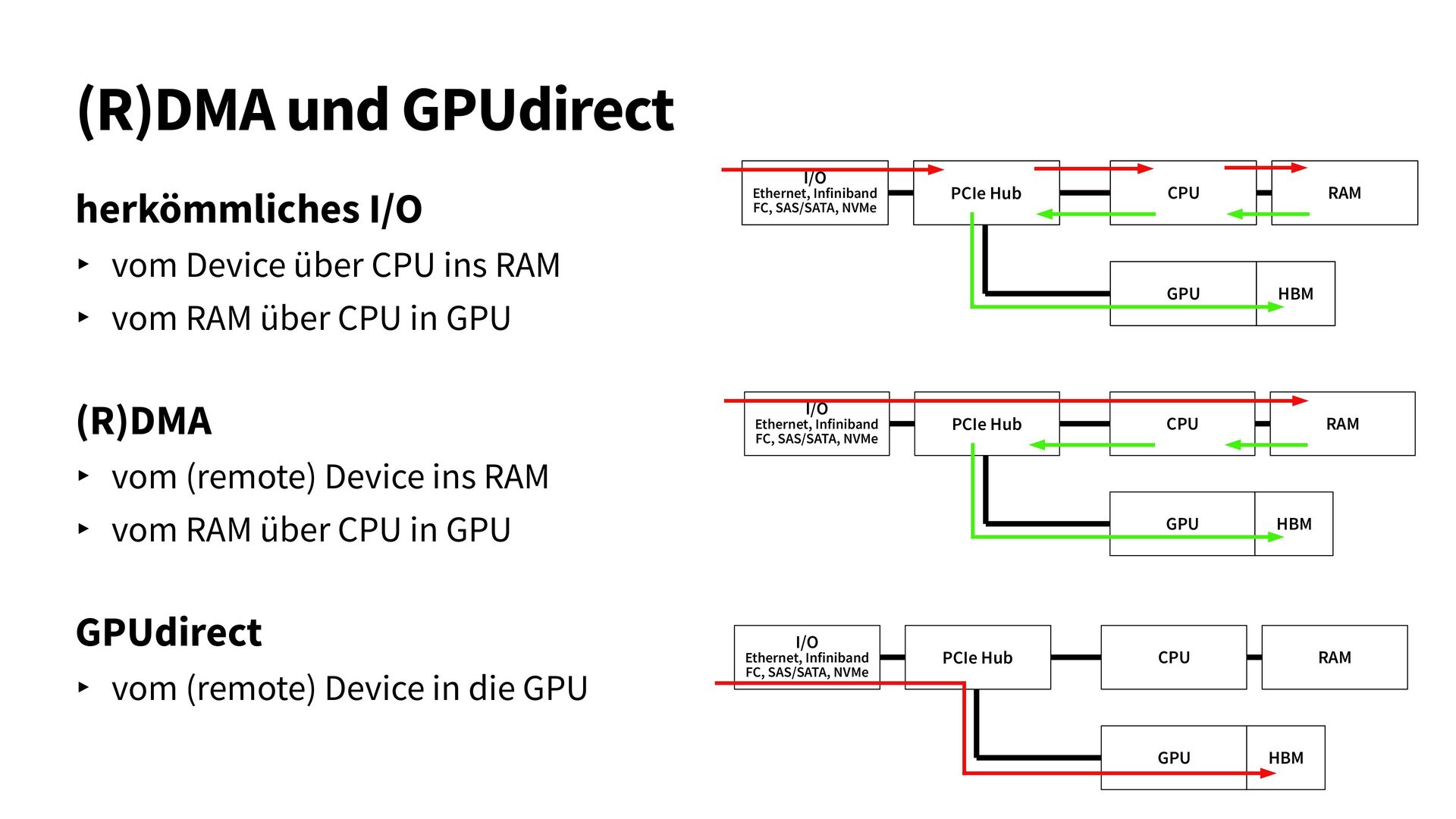{kind=link}
{kind=link}
{kind=link}
{kind=link}
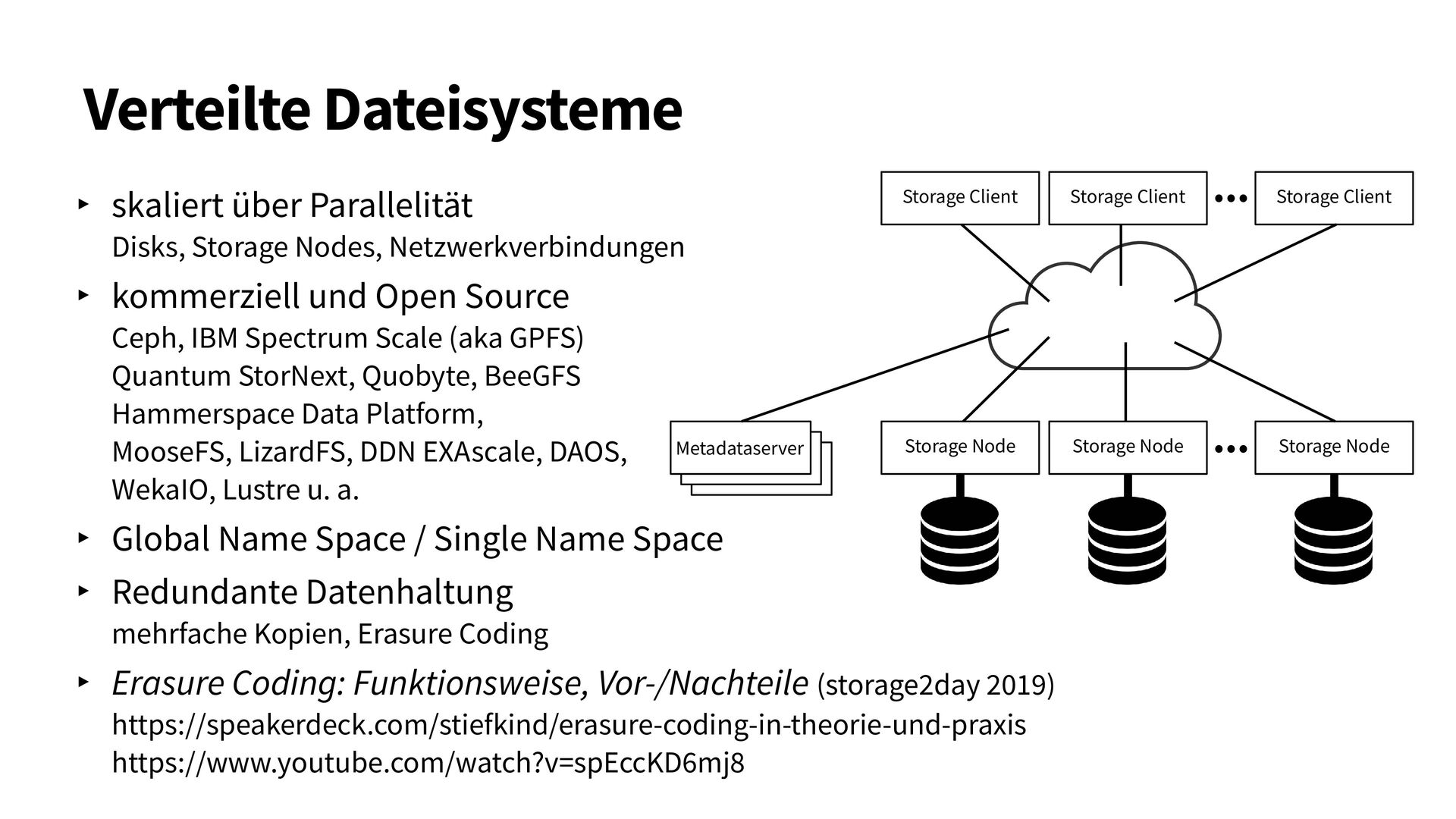{kind=link}
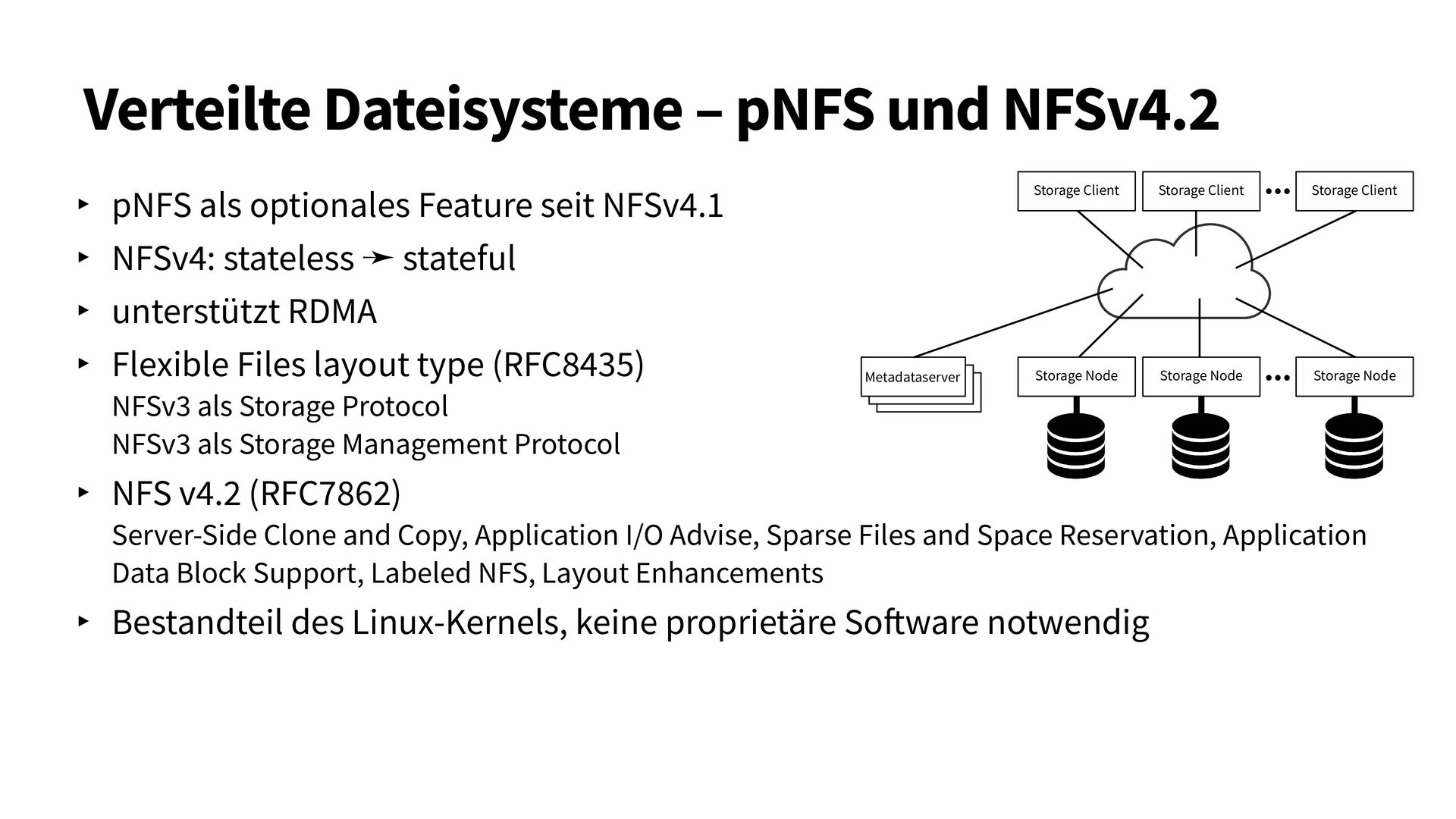{kind=link}
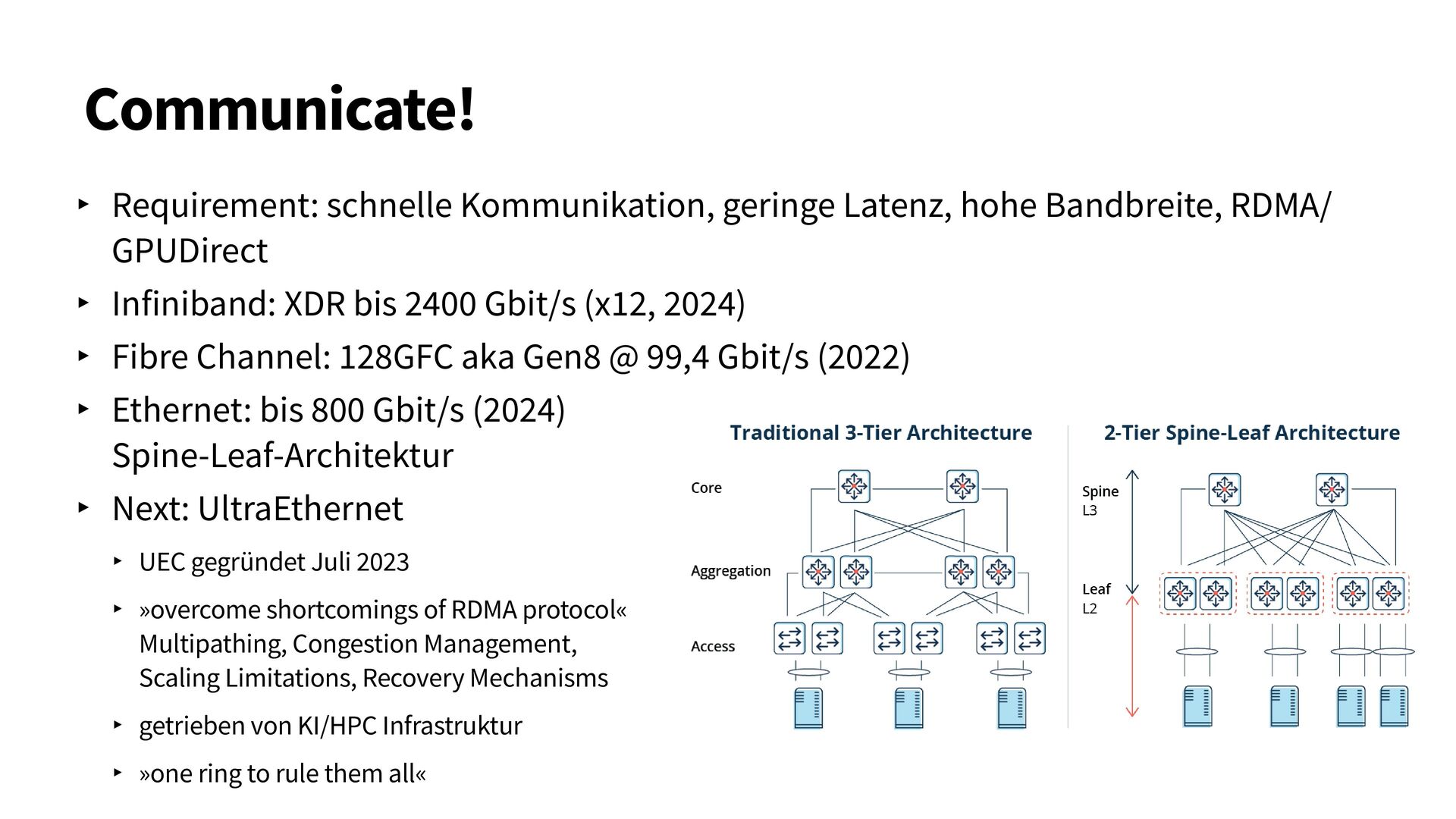{kind=link}
{kind=link}
{kind=link}
![Kerstin Mende-Stief Wolfgang Stief [email protected] https://www.linkedin.com/in/wstief @stiefkind.bsky.social @[email protected] https://speakerdeck.com/stiefkind https://datadisrupted.tech/](https://files.speakerdeck.com/presentations/2b865241a59d42a4a2cbc1d6ac4be921/slide_21.jpg){kind=link}