こんな感じ I GET 200 10.31 KB null Go-http-client/1.1 https://grafana.threetreeslig I GET 200 26.02 KB null Go-http-client/1.1 https://threetreeslight.com/ I GET 200 10.31 KB null Go-http-client/1.1 https://grafana.threetreeslig I GET 200 26.02 KB null Go-http-client/1.1 https://threetreeslight.com/ 15 / 31
If you’re using GKE and Stackdriver Logging is enabled in your cluster, you cannot change its configuration, because it’s managed and supported by GKE. gcloud beta container clusters update --logging-service=none blog-cluster 27 / 31
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
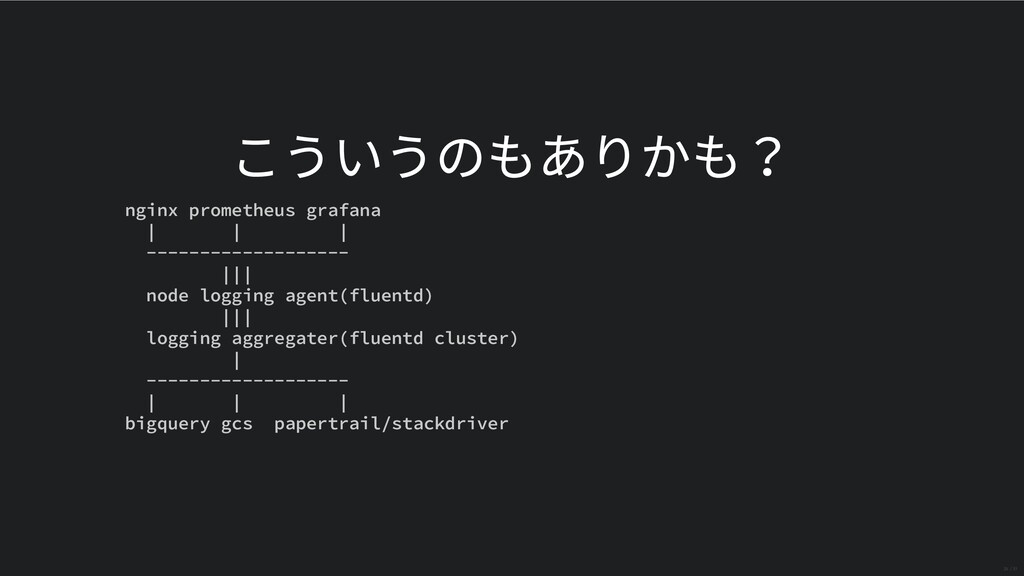{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}