Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
Search
やくも
July 04, 2026
Technology
1.3k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
JAWS ミート 2026
https://jaws-ug-tokaido.connpass.com/event/392910/
やくも
July 04, 2026
More Decks by やくも
See All by やくも
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
83
社内RAGの導入で気を付けたポイント
yakumo
3
180
おいらのAWSアップデートの追い方〜Slack×AgentCore〜
yakumo
2
150
AgentCore Managed Harness を使ってみよう
yakumo
2
490
AgentCoreがWindowsで動かなかった原因を調べてみた
yakumo
1
110
AgentCoreとLINEを使った飲食店おすすめアプリを作ってみた
yakumo
2
430
StrandsとNeptuneを使ってナレッジグラフを構築する
yakumo
2
640
なんとなくの実装を抜け出す! 10分でおさらいするAgentCoreの認証・認可
yakumo
2
790
AWSと生成AIで学ぶ!実行計画の読み解き方とSQLチューニングの実践
yakumo
3
1.5k
Other Decks in Technology
See All in Technology
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
24
10k
そのドキュメント、自動化しませんか?
yuksew
1
410
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
780
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
130
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
160
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
書籍セキュアAPIについて
riiimparm
0
180
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
190
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
4
1.1k
Featured
See All Featured
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Exploring anti-patterns in Rails
aemeredith
3
450
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Mobile First: as difficult as doing things right
swwweet
225
10k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Paper Plane (Part 1)
katiecoart
PRO
1
9.8k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Technical Leadership for Architectural Decision Making
baasie
3
440
Design in an AI World
tapps
1
260
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
How GitHub (no longer) Works
holman
316
150k
Transcript
AgentCoreを利用したText-to-SQLと精度評価 八雲 慎之助/Shinnosuke Yakumo 2026/7/4 JAWS-UG ミート 2026
八雲 慎之助(やくも しんのすけ) • 所属:株式会社クレスコ / JAWS-UG 新潟支部 • 業務:R&D(AI分野)
• AWS Community Builder – AI Engineering • 2025 Japan AWS Jr.Champions Who am I
AgentCore 使ってますか?
Text-to-SQLはやったことありますか?
Text-to-SQLって?? • 自然言語の質問をSQLクエリに変換する • NL2SQLとかあるけどほぼ同じ • 難しい構文を理解しなくても良いので、知識がなくても必 要なデータの取得が可能になる。
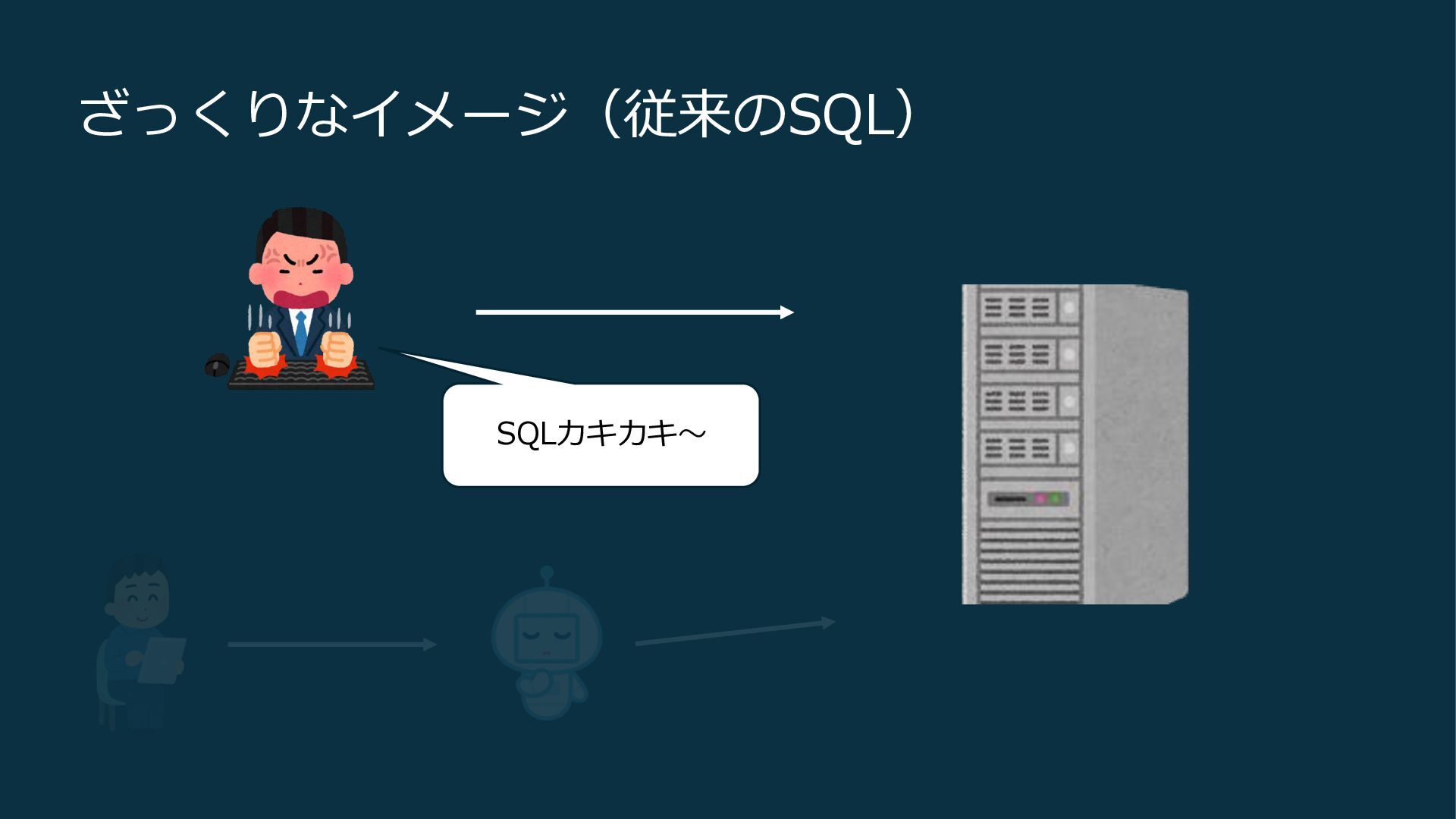
ざっくりなイメージ(従来のSQL) SQLカキカキ〜
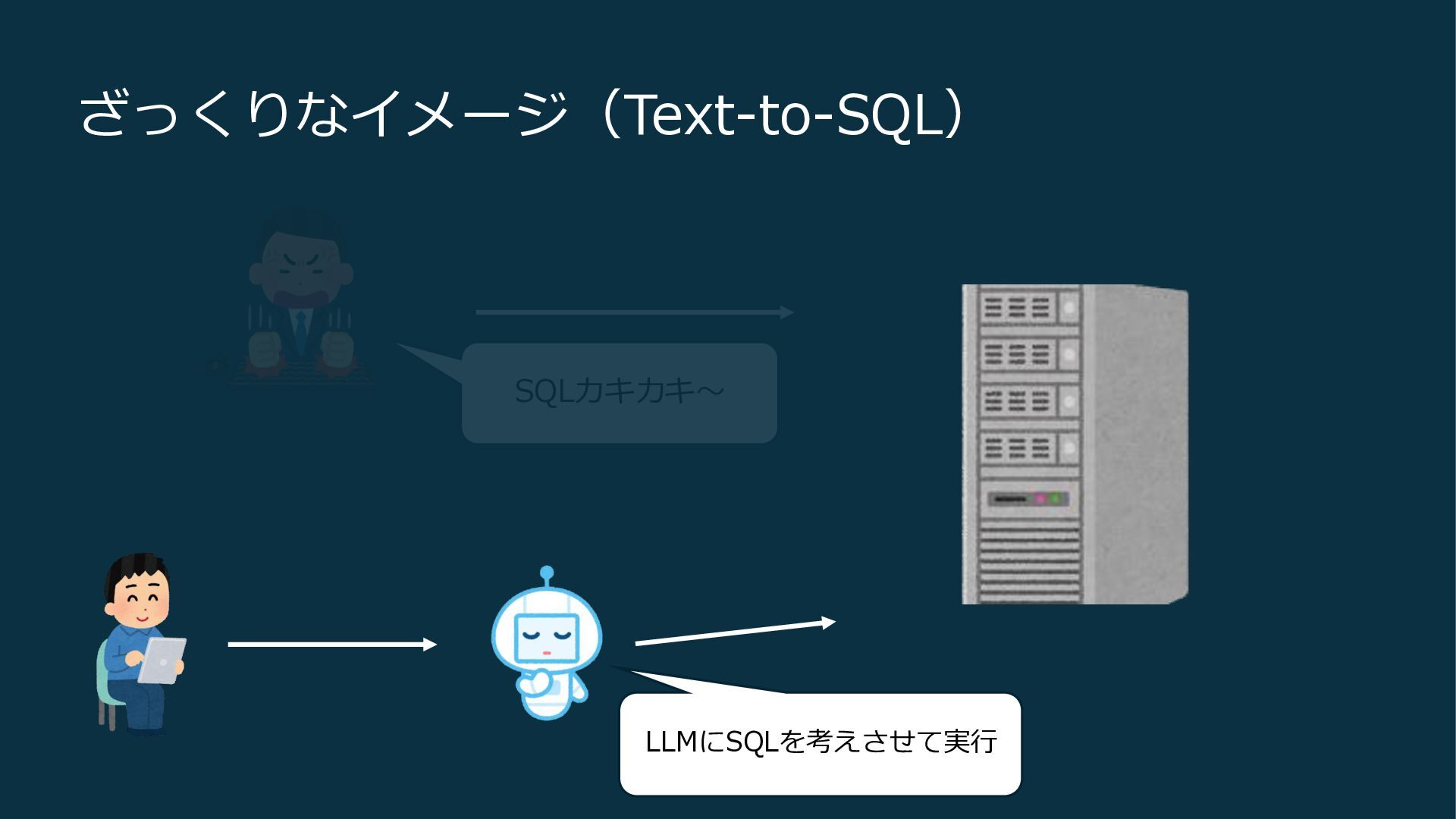
ざっくりなイメージ(Text-to-SQL) SQLカキカキ〜 LLMにSQLを考えさせて実行
Text-to-SQLの課題や弱点 • LLMに生成させるのでハルシネーションは起こりうる • 場合によってはレイテンシーが大きくなる • 生成されたSQLの精度が評価しづらい
導入の背景やメリット • アプリ部門にいた時代、SQLによる分析や実行計画からの 改善の負担が大きかった • 職人気質な分野だが若手が任されやすい • 本来の開発に時間をかけたいので、LLMを使えるなら活用 して時間を短縮したい!
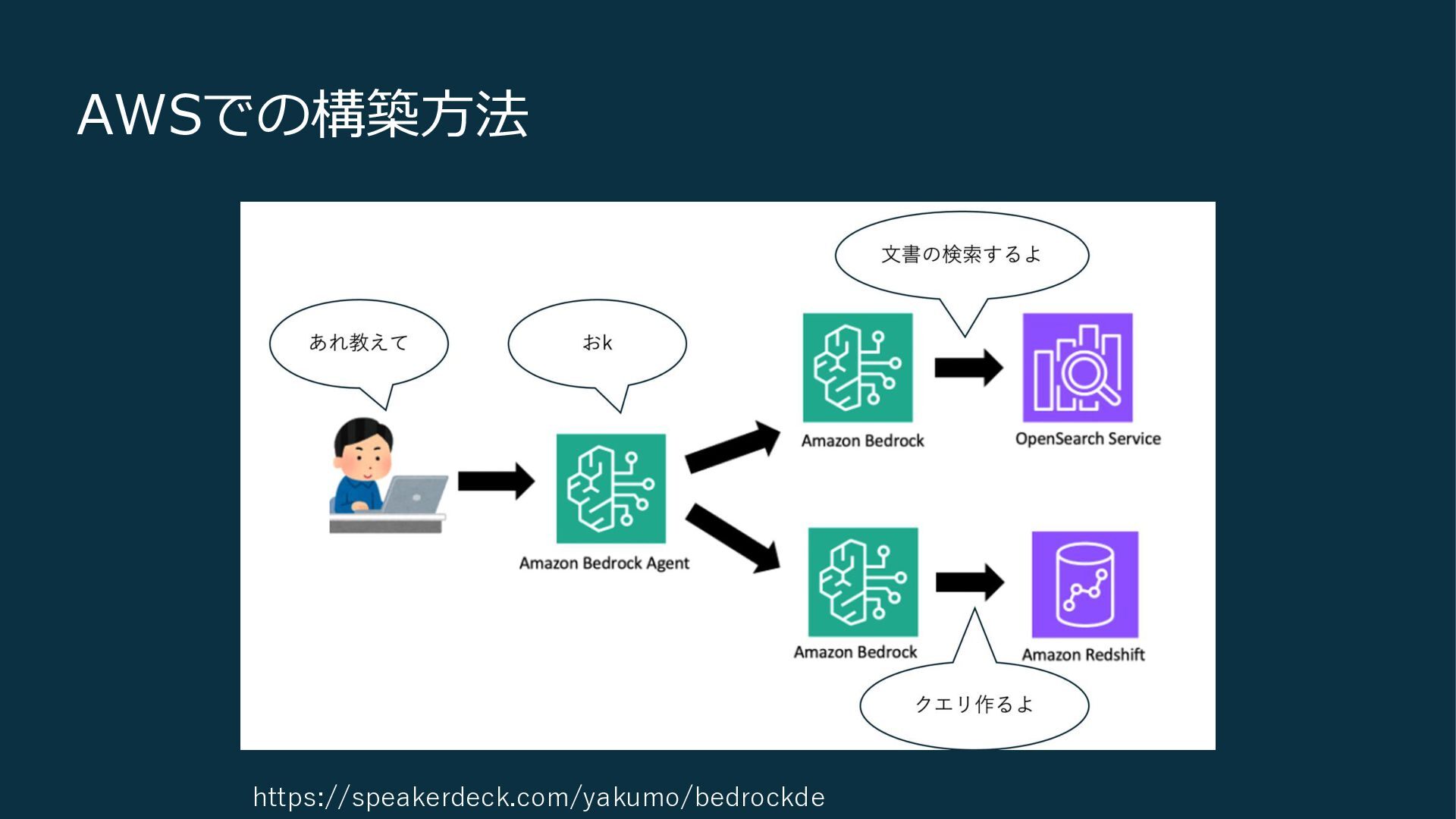
AWSでの構築方法 https://speakerdeck.com/yakumo/bedrockde
Bedrock Agentsさん…(7/30より新規利用停止) https://aws.amazon.com/about-aws/whats-new/2026/06/aws-service-availability/
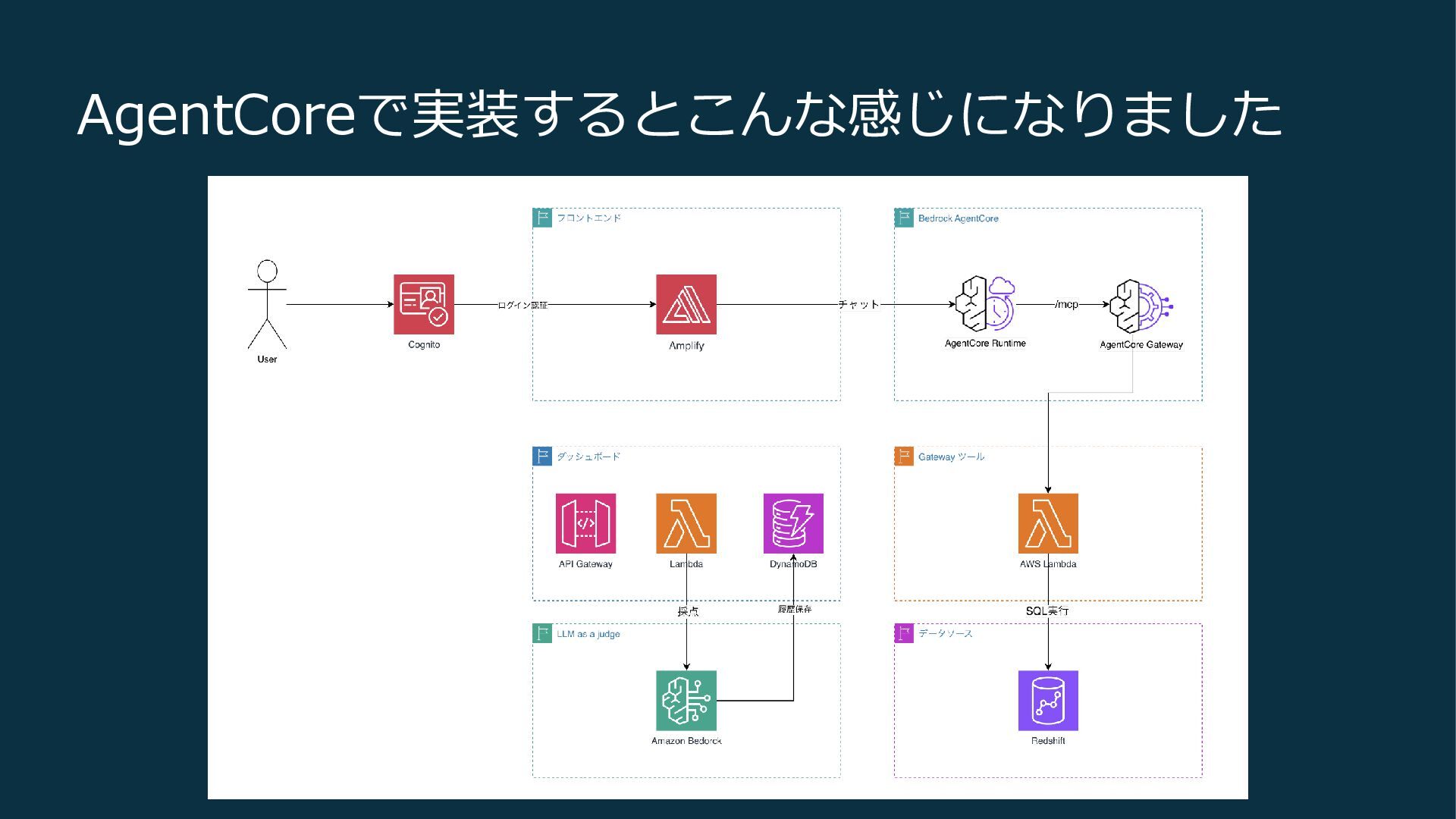
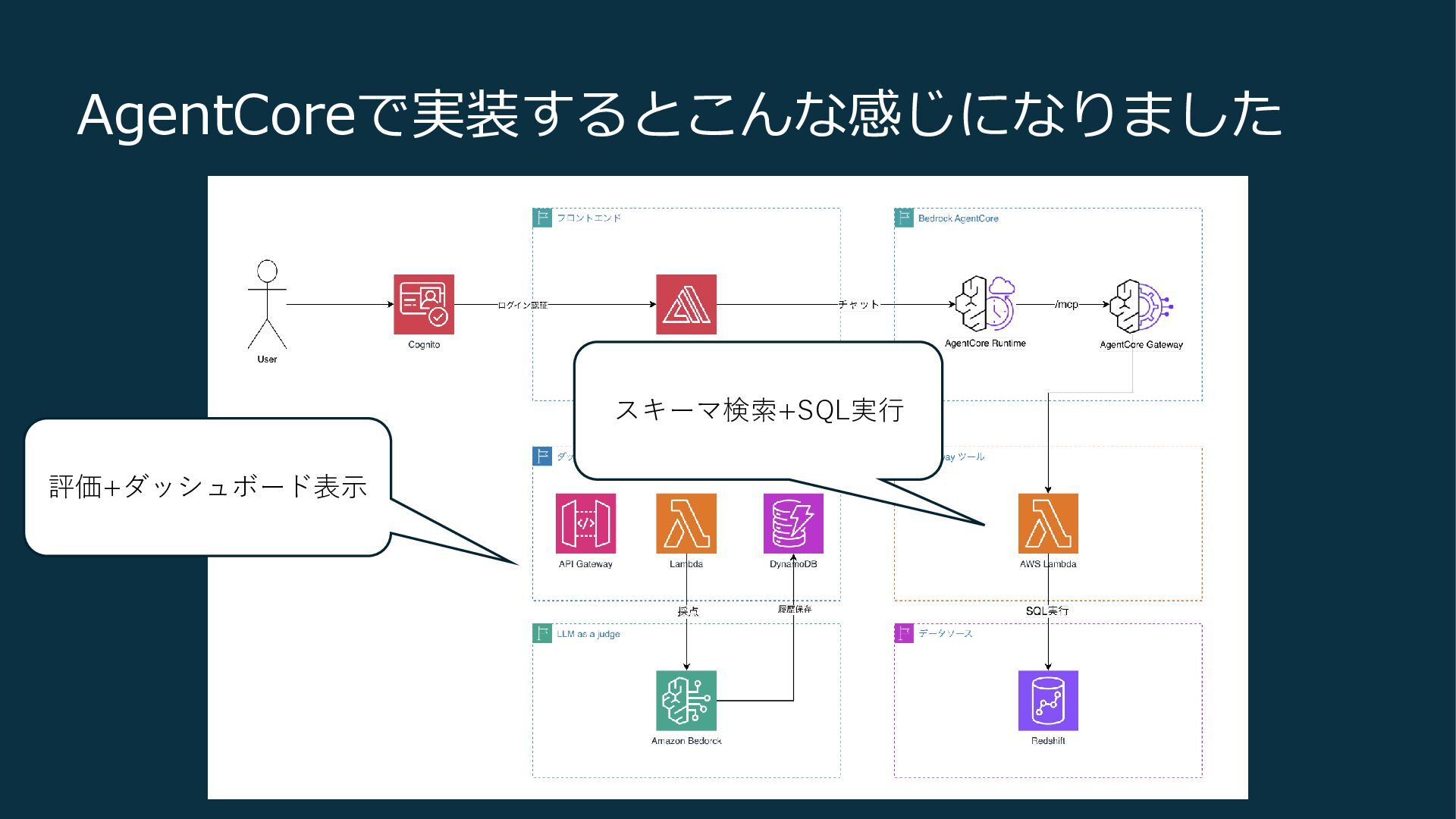
AgentCoreで実装するとこんな感じになりました
動作イメージ(次のスライド)
AgentCoreで実装するとこんな感じになりました 評価+ダッシュボード表示 スキーマ検索+SQL実行
やっていることの解説など • スキーマの検索・取得 • AgentCore Memoryの活用 • LLM as a
judgeによるSQLの精度評価 • 実行計画の確認とSQLの修正(未実装(泣))
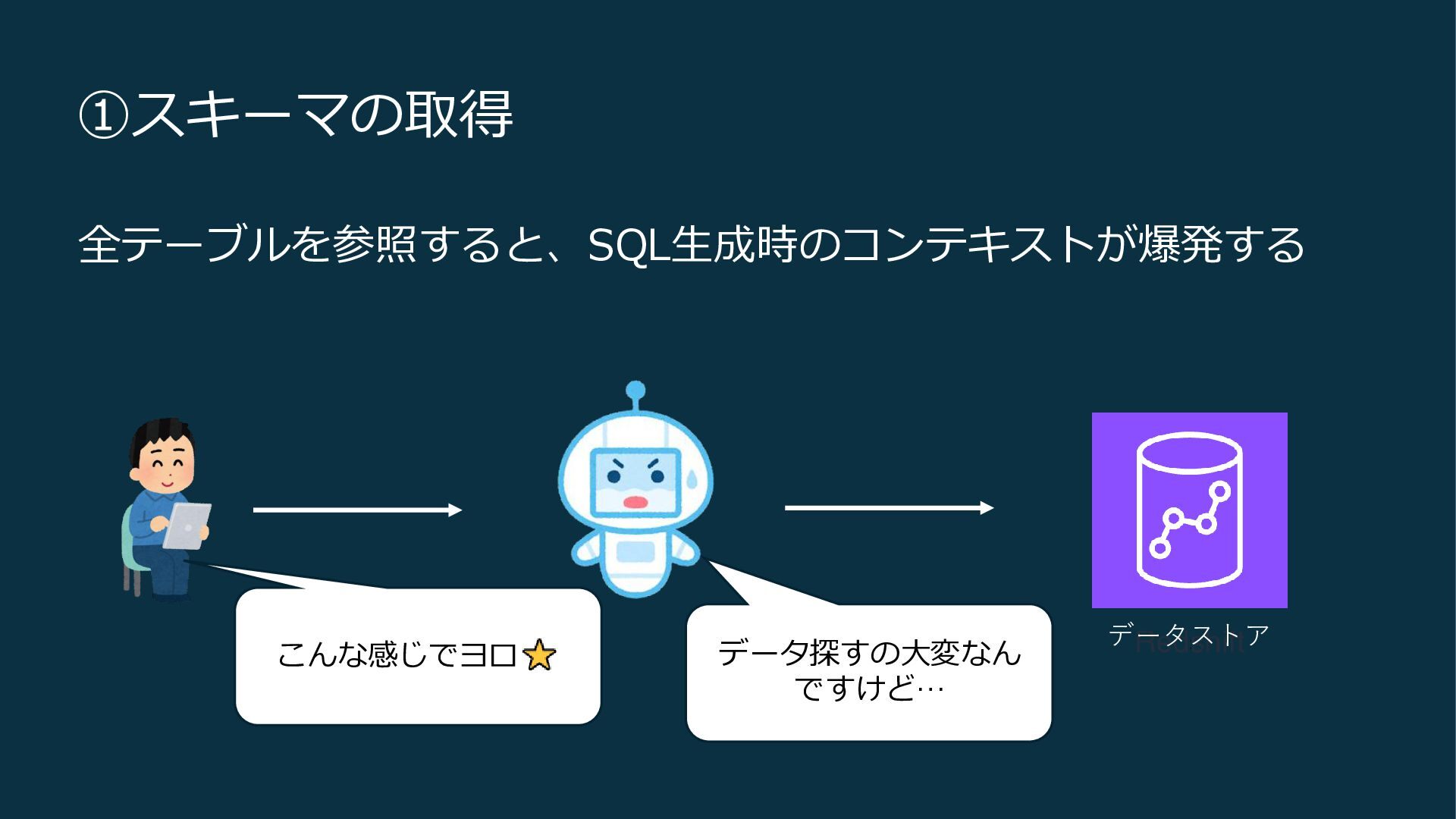
①スキーマの取得 全テーブルを参照すると、SQL生成時のコンテキストが爆発する データストア こんな感じでヨロ データ探すの大変なん ですけど…
①スキーマの取得 エージェントが効率的にSQLを書くために、どのテーブル・カラム を使えばいいかを判断する →コストの削減(トークンベースで1/10)、精度向上、レスポンス短縮
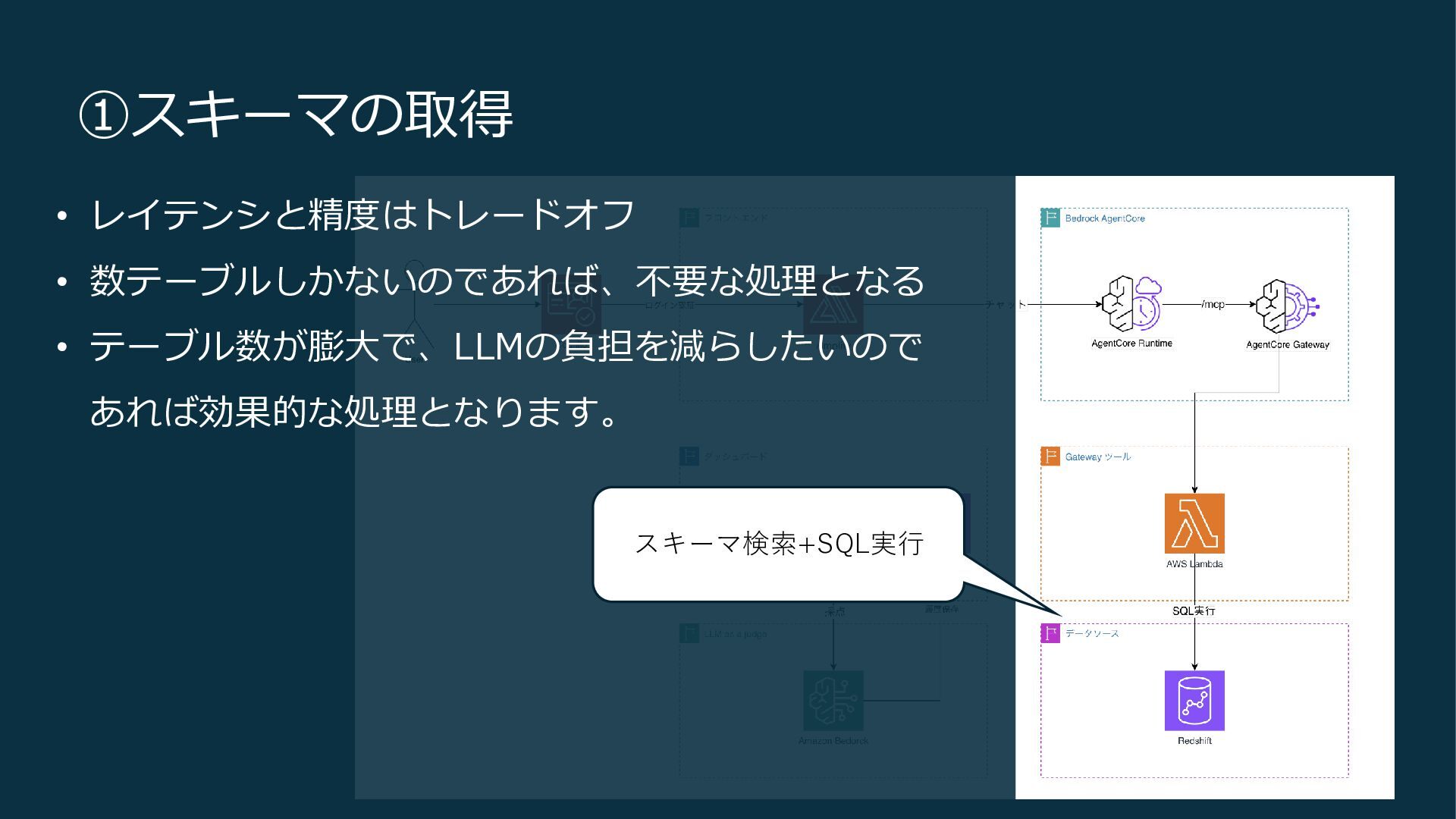
①スキーマの取得 スキーマ検索+SQL実行 • レイテンシと精度はトレードオフ • 数テーブルしかないのであれば、不要な処理となる • テーブル数が膨大で、LLMの負担を減らしたいので あれば効果的な処理となります。
②AgentCore Memoryの活用 1. ユーザーの質問をメモリに保存 2. 類似の過去事例を取得 3. 参考にSQLを生成
②AgentCore Memory使用・未使用の比較 1. 質問 2. スキーマ取得 3. SQLを生成 • 過去の正解例を知らない
• 似た質問でも毎回ゼロから推論 1. 質問 2. Memory検索(類似の正解を取得) 3. スキーマ取得 4. SQLを生成 • 正解を手本に • JOINのパスやカラム選択の精度の向上 毎回推論して生成する Memoryを参照するのでどんどん 精度が向上する Memory 未使用 Memory 使用
LLM as a judgeによるSQL評価について • LLM自身がLLMのアウトプットを評価する手法 • なぜLLM as a
judge? • BIRDのようなベンチマークはオフライン評価 • 本番で稼働し、データが変わり続ける場合LLMを利用した方が 品質の担保がしやすかった • 本番導入前のオフラインでの検証では有用かもしれない • Ex)スキーマ検索の有無、Memoryの有無での精度比較など
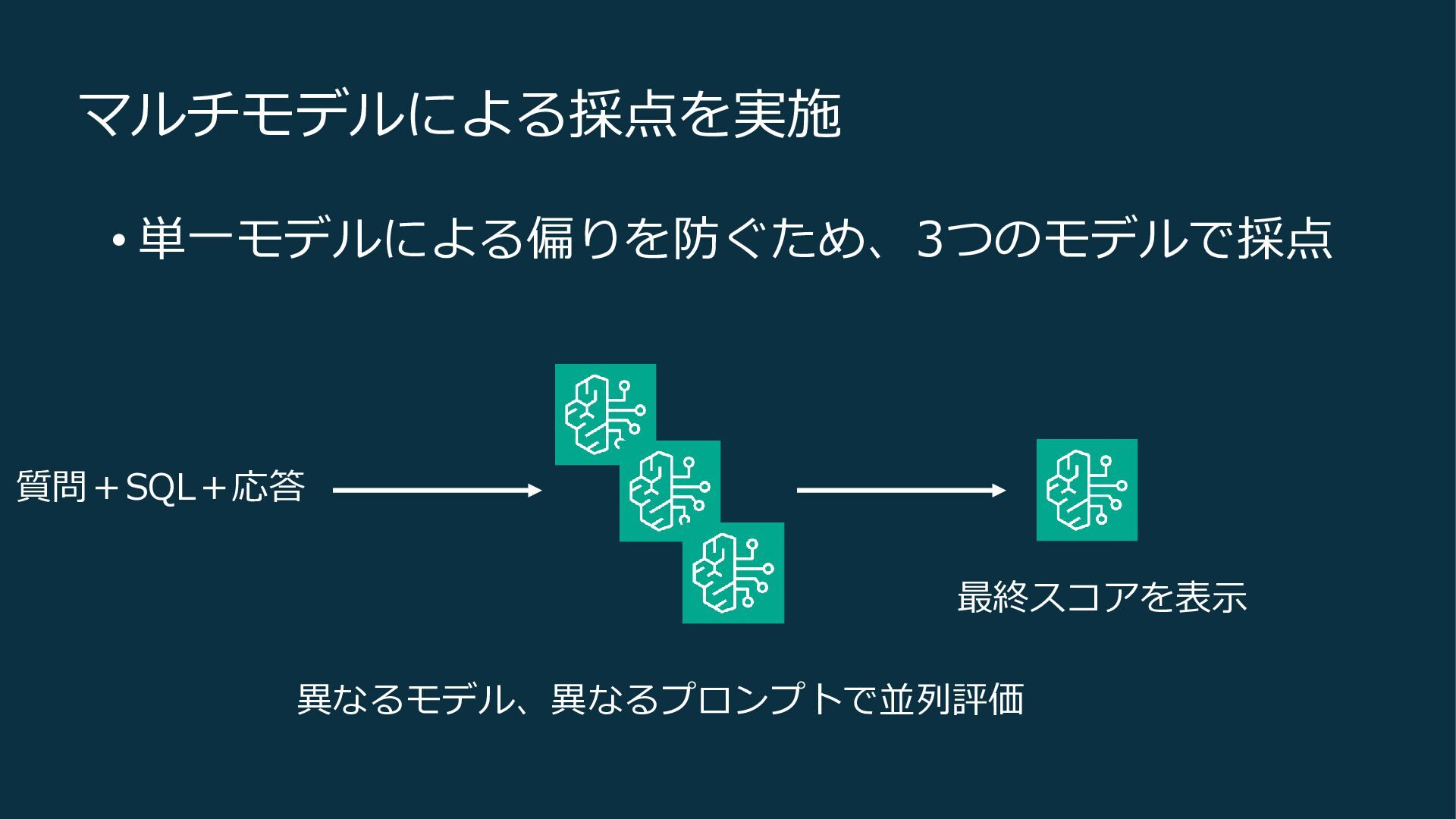
マルチモデルによる採点を実施 • 単一モデルによる偏りを防ぐため、3つのモデルで採点 質問+SQL+応答 異なるモデル、異なるプロンプトで並列評価 最終スコアを表示
採点モデルごとのプロンプト例 • Opus • SQLの正確性に関する深い検証 • テーブルやカラム、JOIN条件などの妥当性 • Sonnet •
回答品質の評価 • 質問に対して的確に答えているか?わかりやすいか? • Haiku/Amazon Nova • 効率性のチェック • フルスキャン、冗長なJOINがないか
AgentCore Evaluationsについて • AgentCoreで実装しているなら、組み込み機能のEvaluationsを使 えばいいのでは?? →実はAgentCore Evaluationsもオンライン評価に対応しているの で、技術的には可能です。 • ですが今回はユーザー体験が良い方を優先しました。
なぜAgentCore Evaluationsじゃないのか 1. 非同期表示のため • 実行後、即座に、シームレスに評価を確認したい場合がある。 • Evaluationsは毎回CloudWatchを見る手間があり、表示にタイムラグもある。 2. GenAIダッシュボードを見る必要がある
• 結果・評価の確認、実行計画の改善などを単一ダッシュボードで改善したかった 3. マルチモデル評価やコメント合成未対応 • マルチモデルによる評価は不可 • ビルトイン評価の場合、モデルそのものが不明(カスタムの場合指定可能)
さいご • LLMを利用したSQL生成により、初学者・新規参画者の湿気がグッ と下がることを実感 • AgentCoreに縛られず、要件や現場に適した実装や技術選定のの 重要さを改めて理解 • 実行計画の改善機能が残っているので、早めに実装する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}