˒ Had GNU Bison stopped evolving? ˒ Go ahead - put your favorite complaint about parsing theory here!!! ˒ 2006: GCC migrates it’s parser from Bison to hand-written recursive- descent parsers (C++ was 2004) ˒ 2015: Go migrates it’s parser from Bison to hand-written recursive- descent parsers They are like a dream on a spring night…
Largely absent from major textbooks, such as the Dragon Book ˒ Vaughan R. Pratt, “Top Down Operator Precedence.” (1973) Implementing a Hand-Written Parser Today
both its left and right sides. ˒ Higher numbers mean higher precedence, so * binds more tightly than +. ˒ If an operator’s right binding power is greater than its left, it is left-associative; otherwise, it is right-associative. 1. Binding power (10) + (11) (10) - (11) (20) * (21) (20) / (21) (30) ^ (30)
a token. ˒ LL(k) allows us to look ahead k tokens, but here we assume the usual case: k = 1. ˒ In other words, this forbids multiple rules from beginning with the same token. ˒ In an actual implementation, left-recursive rules cause an in fi nite loop. Recursive Descent Parser (LL parser)
required by LL parser generators. LR parser (1) 2 E: T • ["end of fi le", '+'] 3 T: T • '*' F 3 T: T '*' • F 5 F: • number 0 $accept: E • "end of fi le" 1 E: E • '+' T 1 • * 2 + 3 1 • 1 • + 2 * 3
* rather than + ˒ Since - has the smaller number, parsing stops once at *. How it works (10) + (11) (10) - (11) (20) * (21) (20) / (21) (30) ^ (30) Binding power
either of these issues … ˒ > writing an LL(k) grammar, and keeping it LL(k) after extending it, seems to be a black art … ˒ > However, this is really a draw-back of BNF; the non-terminals tempt one to try to say everything with just context-free rules … ˒ One thing I can say is that, in the pseudocode, what nud and led receive is a token. 3. Anti-BNF
LL parsers require grammar rewriting. ˒ LR parsers are not as simple as Pratt parsers, either. ˒ There was the confusion—or perhaps unease—of not using BNF at all. Excitement and Unease
Ruby. ˒ Normally, statements represent actions, while expressions yield values—but in Ruby, even actions have values. ˒ In parse.y terms, an expr is not an arg, so it cannot be used as an argument, but it is still a smaller unit than a stmt—though that is probably not worth getting into here. Note: What is the “expression”?
so parsing continues. ˒ More precisely, + and - can be either binary or unary: if binary, parsing stops; if unary, parsing continues. ˒ Since the lexer is in EXPR_BEG here, it should produce a unary-operator token. For ‘+’ ‘-’
unary case, it denotes a splat. ˒ However, unary * is not allowed in this position. ˒ Not sure it is entirely right to say that it is “not an expression” simply because it cannot appear here, but for now, let’s treat it as not being an expression. ˒ In fact, token_begins_expression_p explicitly returns true for tokens like UPLUS (+), but not for USTAR (*). For ‘*’
after return. ˒ If the next token is a literal, such as 1, parsing continues. ˒ If the next token is a newline or a post fi x if, parsing stops at that point. ˒ if can also appear in two forms: pre fi x and post fi x. #2: return
not right after rescue. ˒ Anything that token_begins_expression_p function cannot account for has to be handled on the caller side. Responsibility of the caller
similar properties. ˒ Good thing it wasn’t a FOLLOW set :) ˒ The FIRST set of a nonterminal or production is the set of terminal symbols that may appear at the beginning of a string derived from it. FIRST sets?
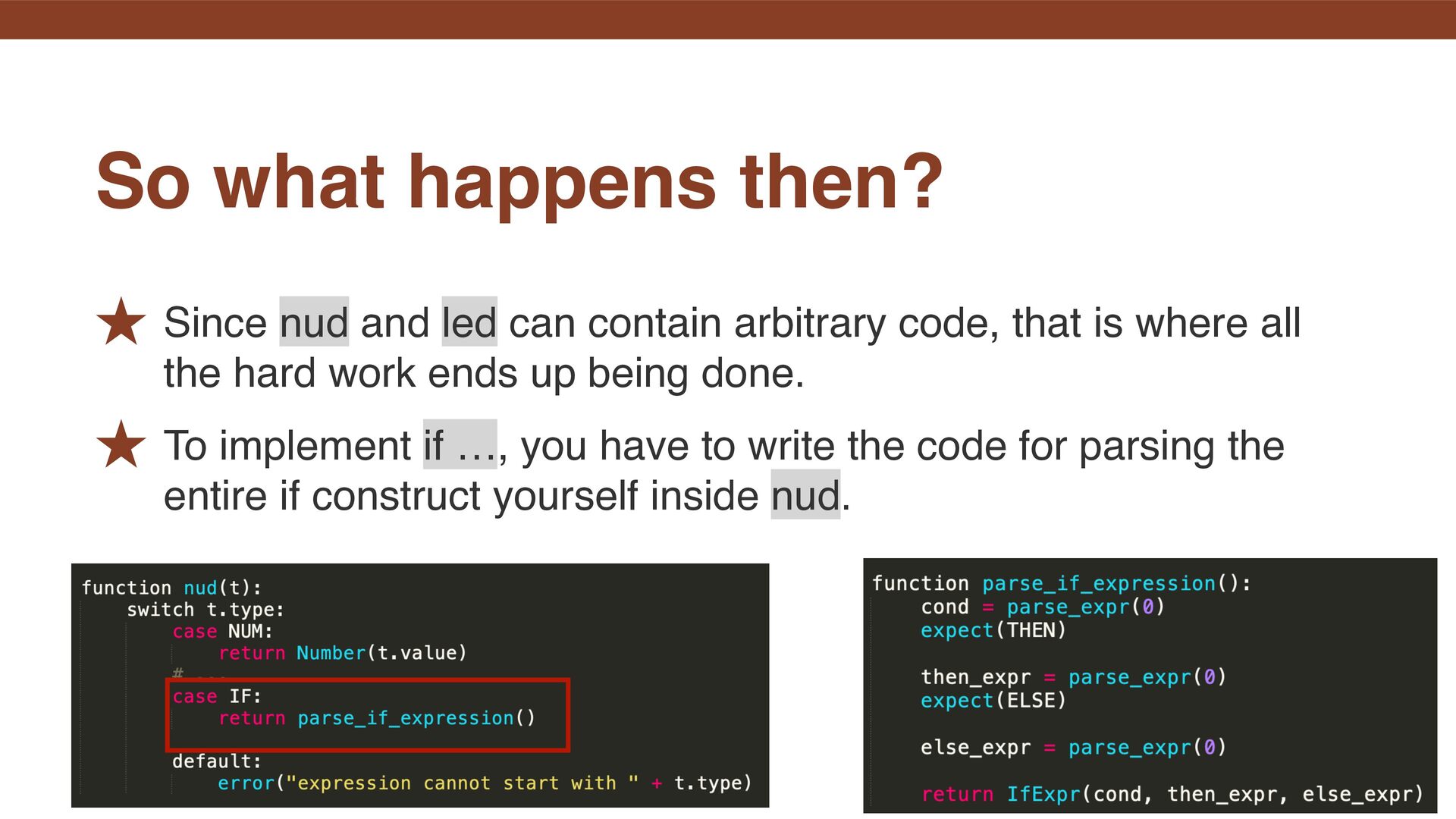
is where all the hard work ends up being done. ˒ To implement if …, you have to write the code for parsing the entire if construct yourself inside nud. So what happens then?
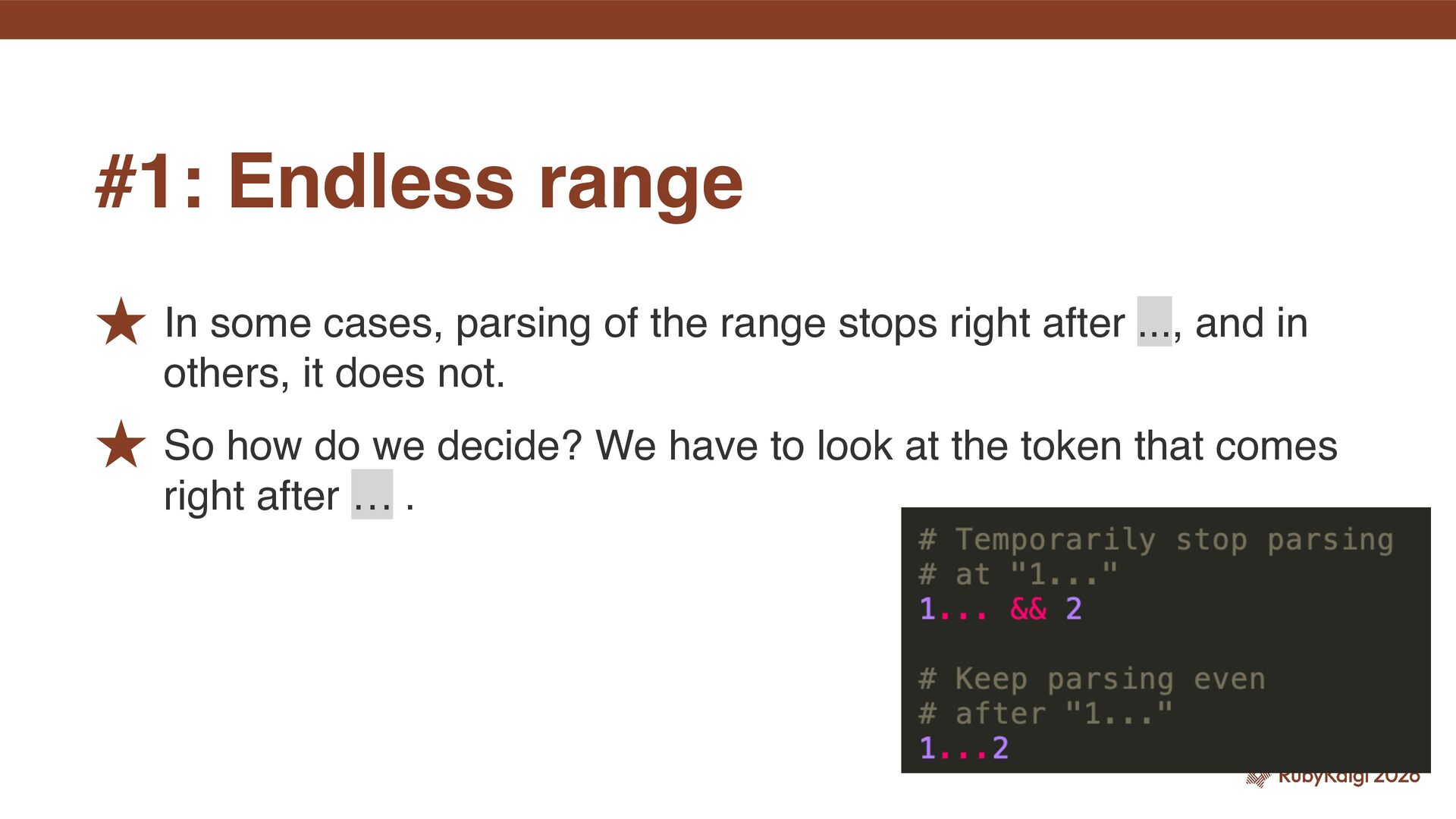
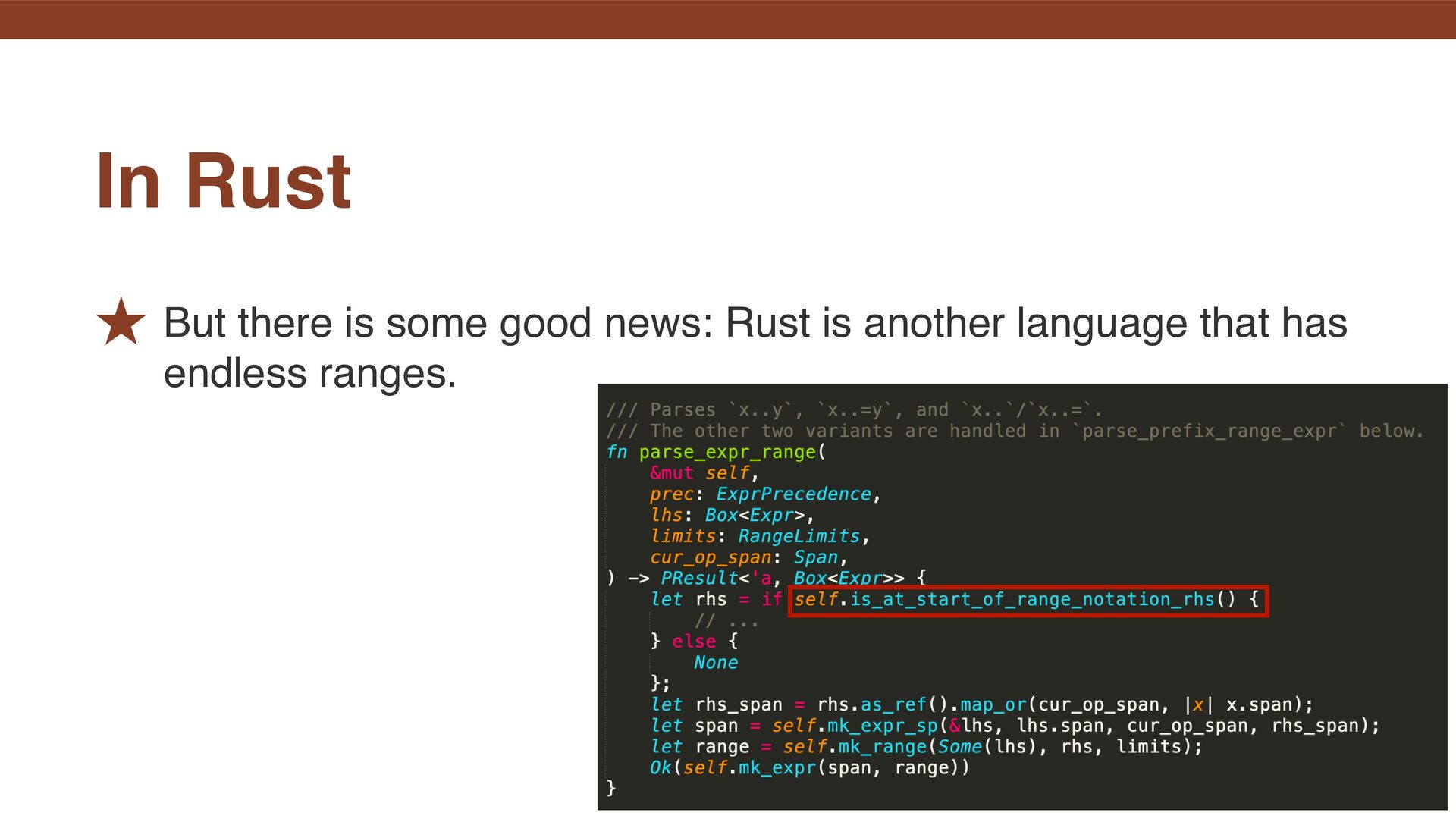
reading … . ˒ There, if the next token is something like an integer literal or class, parsing continues as the right-hand side of a range; otherwise—for example, &&—it is treated as an endless range. #1: Endless range
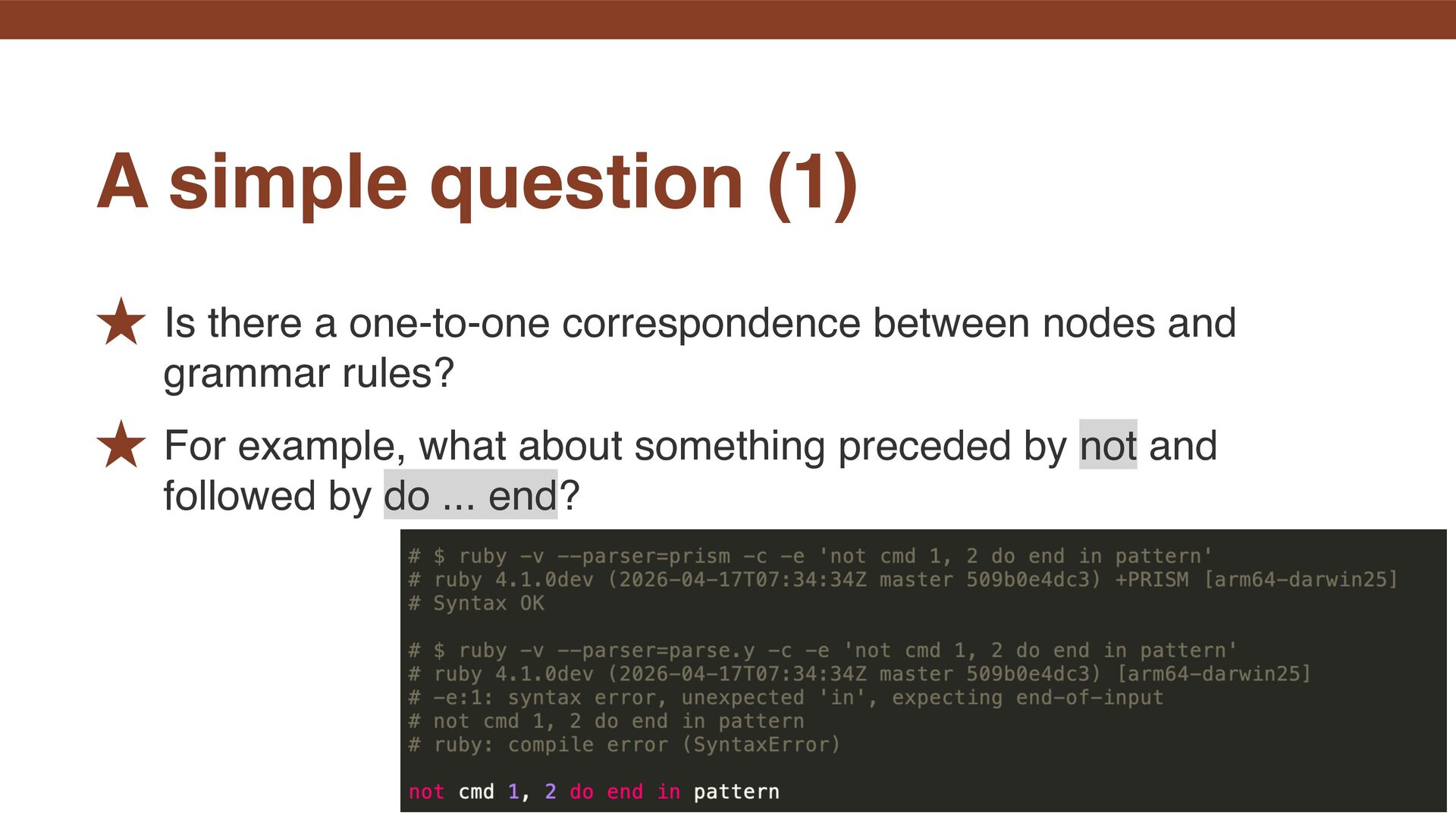
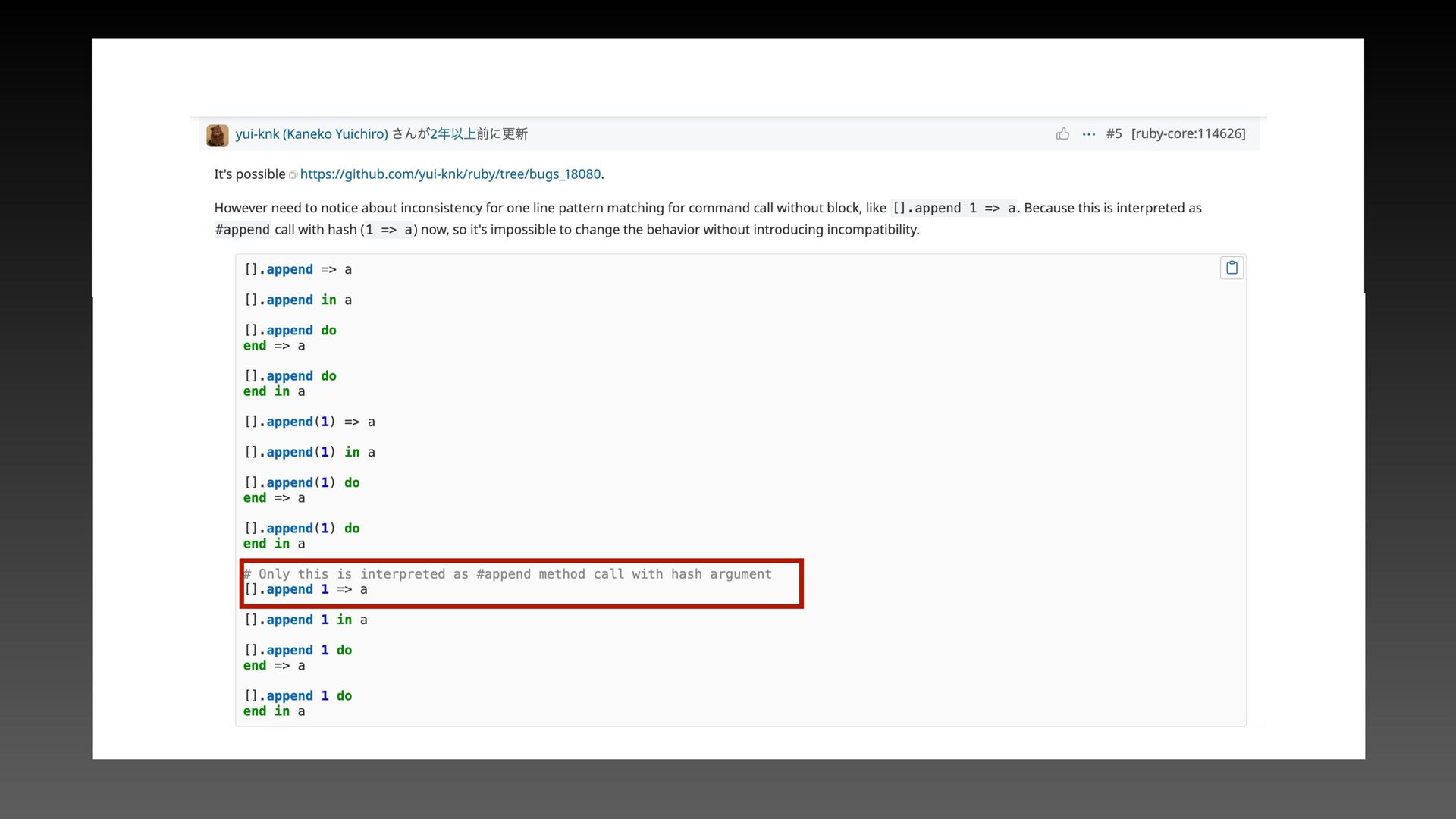
appears to the left of in. ˒ Since the issue involves the in fi x operator in, checking only the fi rst token of the left-hand side is not enough to resolve it. What’s the problem?
appear on the left-hand side of in and some cannot. Doesn’t this ultimately turn into a function that enumerates all the syntax trees that are not allowed there? A simple question (2)
single fi xed precedence within the grammar. ˒ To handle operators like modi fi er rescue, whose precedence changes depending on the situation, you need some extra mechanism outside the Pratt parser itself. ˒ From a parser-generator person’s point of view, this really starts to look like a nonterminal. Assumption
how to read con fl ict reports and so on. ˒ This is knowledge you only need when working with parser generators. 1. Knowledge speci fi c to parser generators
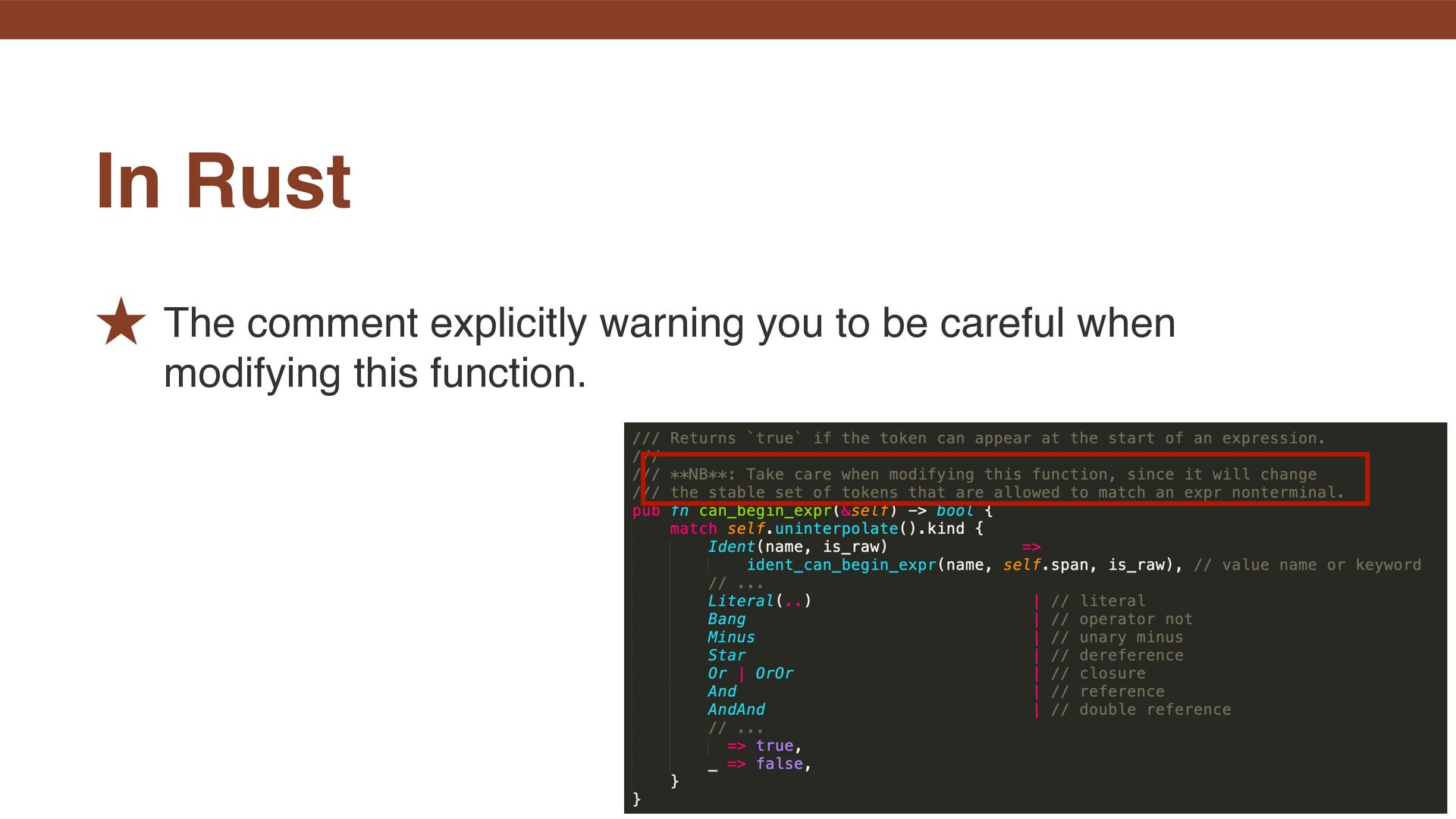
works. ˒ You may also need to understand functions like token_begins_expression_p and parse_expression_terminator. ˒ My personal impression is that Pratt parsing has a fairly narrow scope: it really only handles operators. As a result, you have to face the problem of how to design everything outside that scope, and what makes it dif fi cult is that those parts tend to become highly language-speci fi c. With a hand-written parser.
when things are going well, but you may still need this kind of knowledge when investigating the cause of a con fl ict. ˒ Of course, anyone implementing a parser generator is expected to have a solid understanding of parsing. ˒ But that’s part of the fun, isn’t it? With parser generators
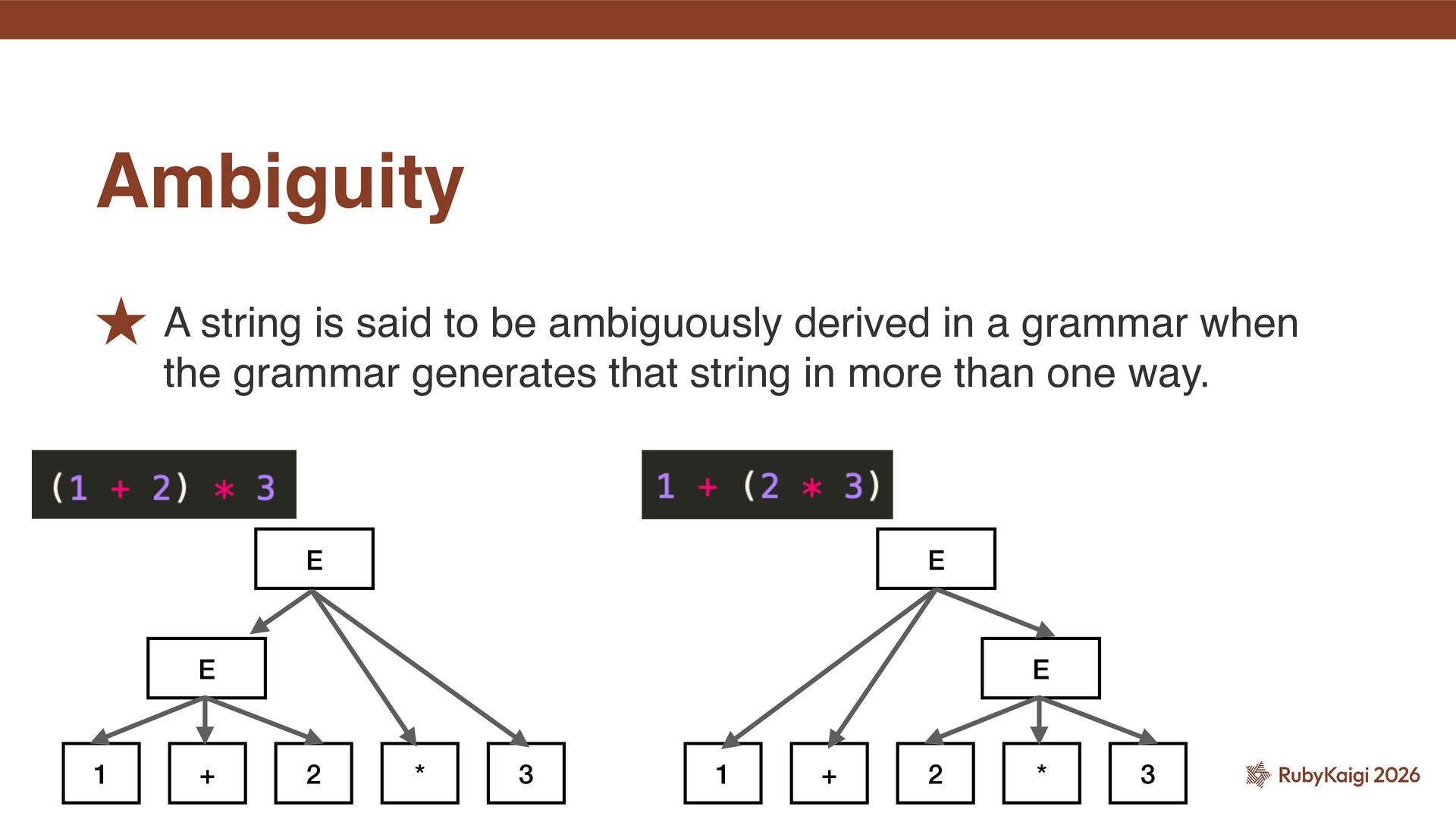
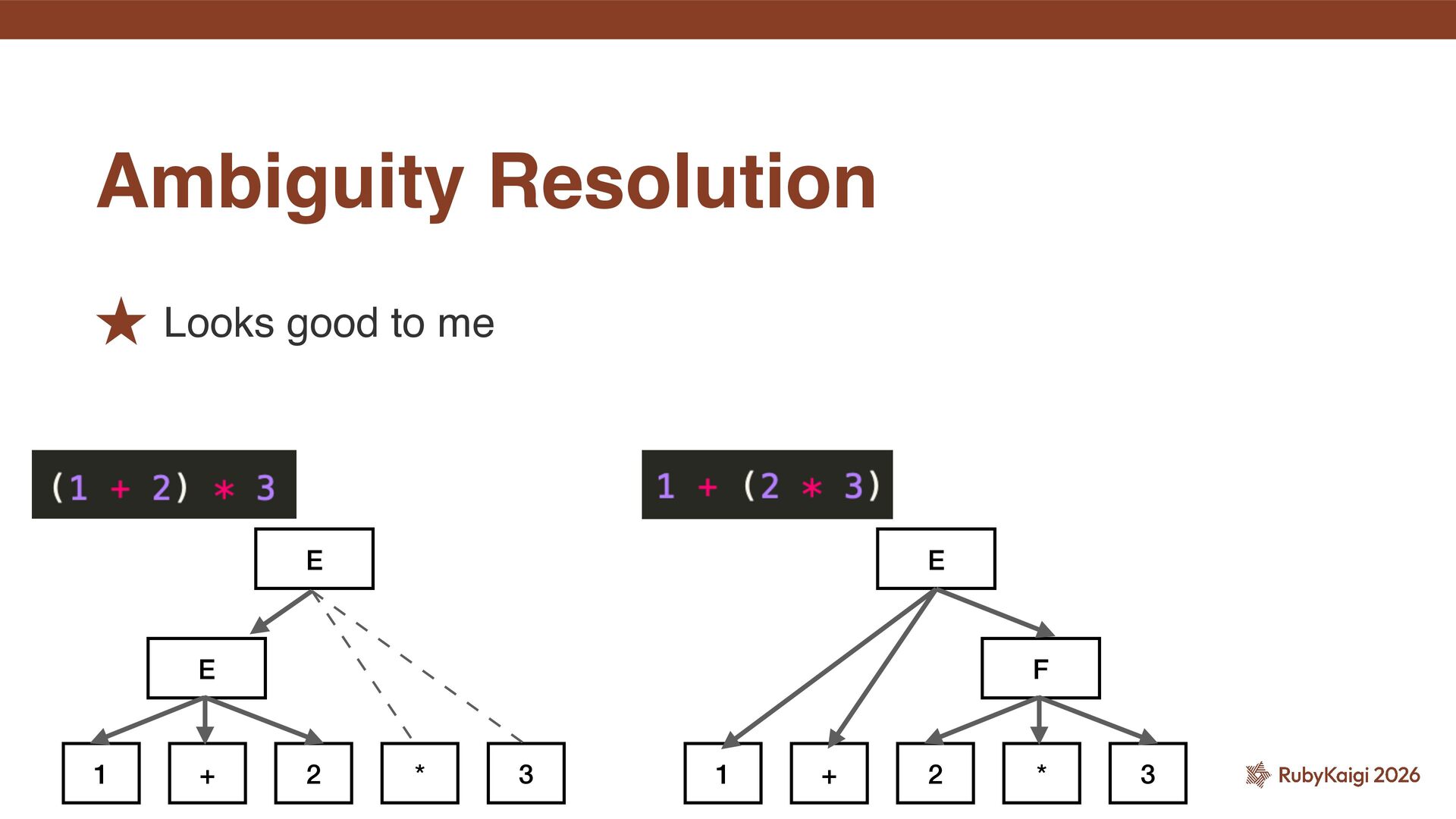
˒ For an ambiguous grammar, what choices were made to resolve the ambiguity. ˒ This is necessary whether the parser is hand-written or built with a parser generator. 3. Grammar knowledge of the target language
new grammar. ˒ One of the points that comes up in such discussions is whether adding that grammar is syntactically sound. ˒ In other words, whether it introduces ambiguity. ˒ At the same time, this also leads to discussions about how far such additions can go. Grammar is a living thing
hand- written parsers verify ambiguity? ˒ You think it’s a stretch to make the parser responsible for feedback on new grammar? ˒ Perhaps. But surely it remains the case that someone, somewhere, must do it, does it not? Grammar is a living thing
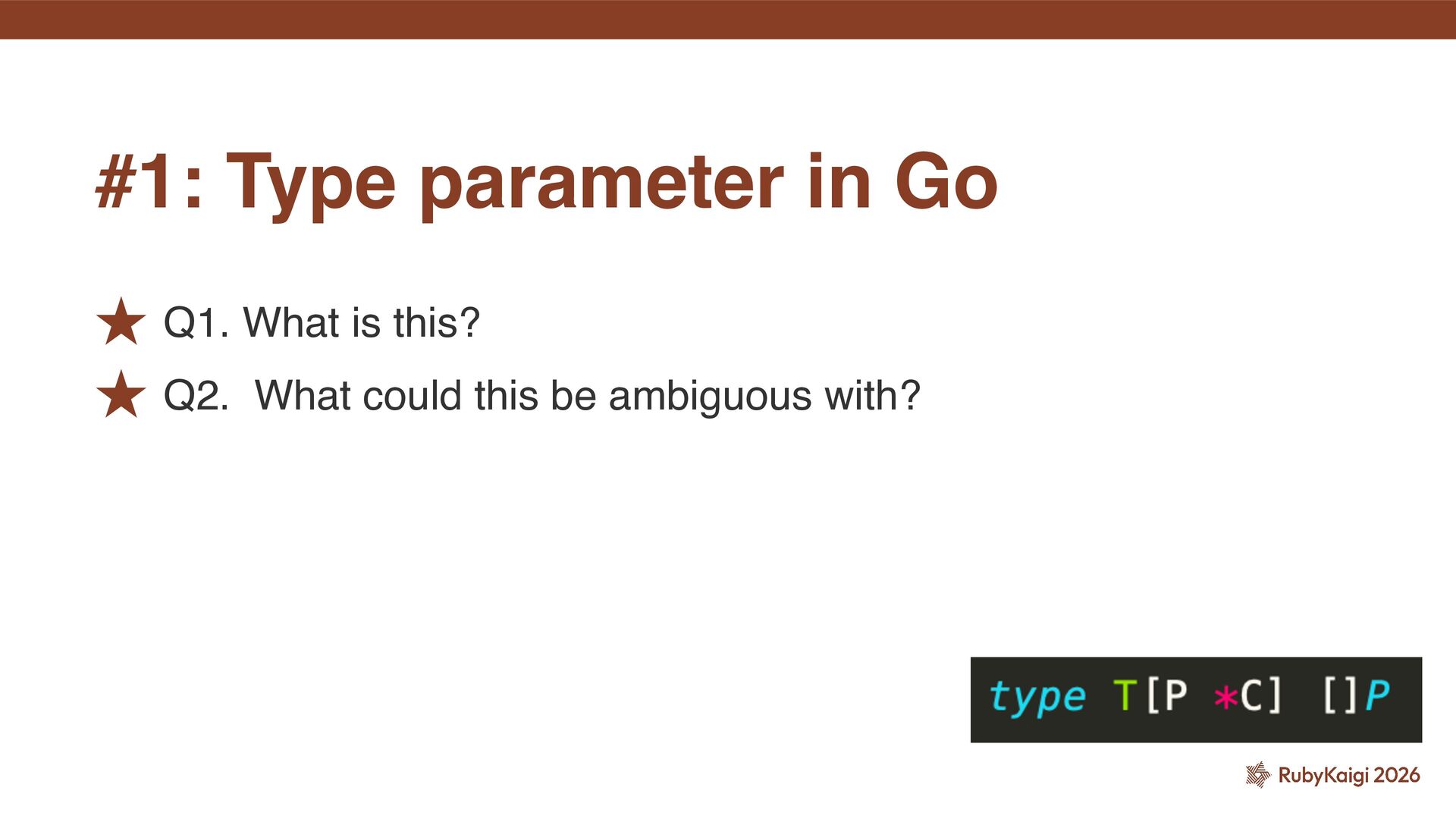
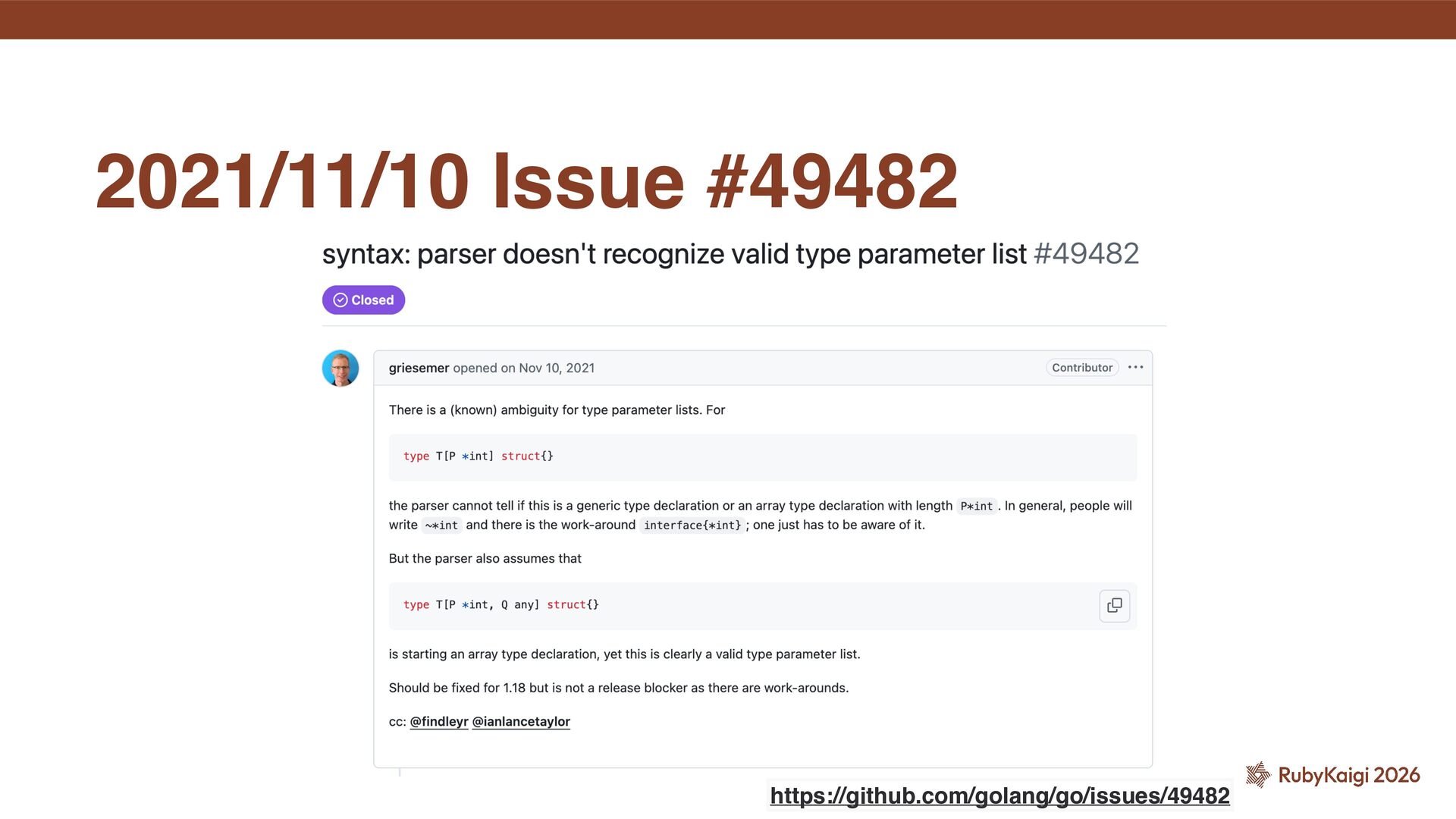
indistinguishable from an expression and the type declaration is parsed as an array type declaration. To resolve the ambiguity, embed the constraint in an interface or use a trailing comma: ˒ https://go.dev/ref/spec#Type_parameter_declarations This is an array type
of this grammar here. ˒ My personal view is that operators often end up being contested between types and the core grammar, which makes it dif fi cult to integrate types cleanly into the grammar. ˒ What interests me here is whether this was actually designed that way. What to Focus On
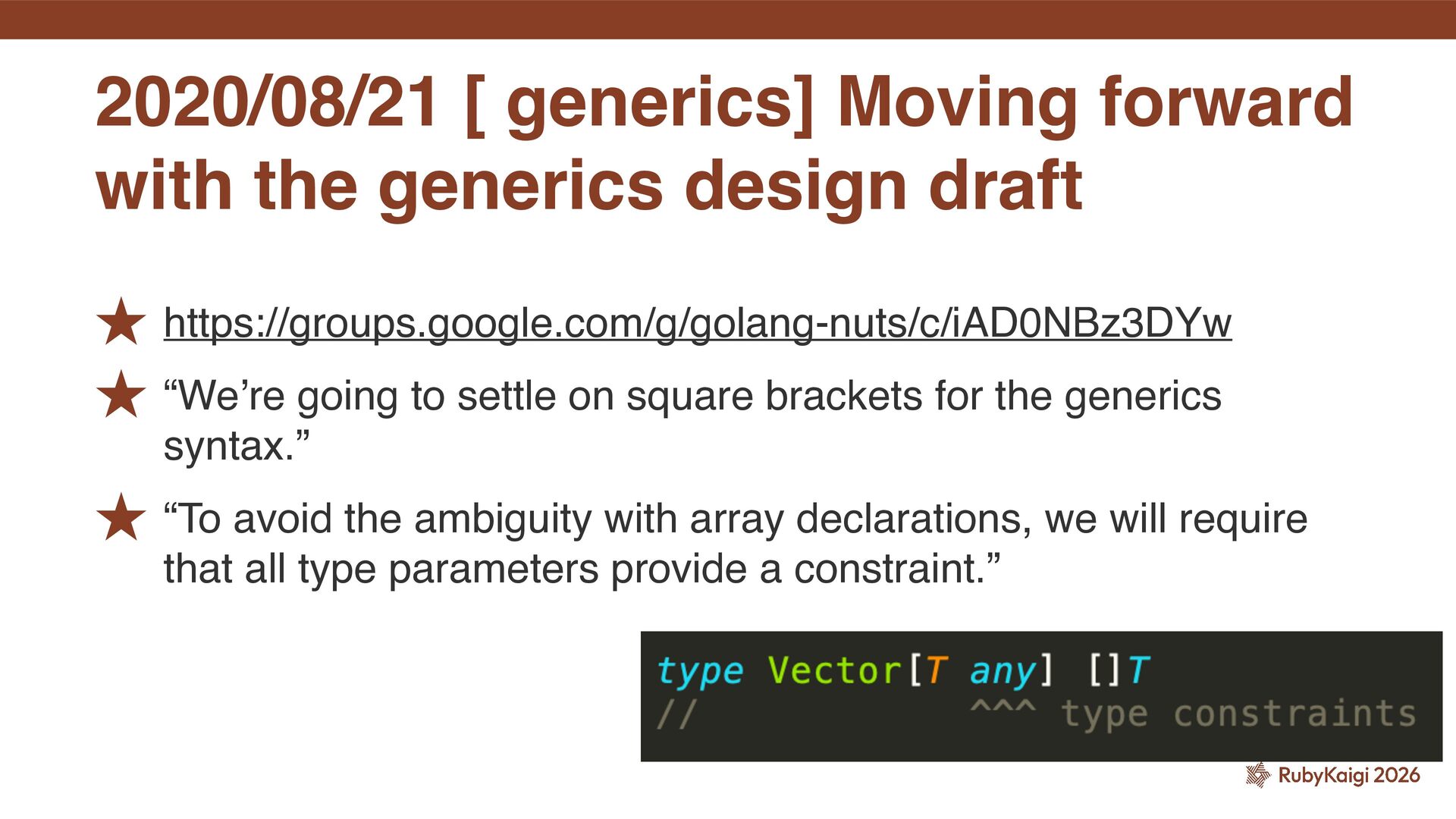
for the generics syntax.” ˒ “To avoid the ambiguity with array declarations, we will require that all type parameters provide a constraint.” 2020/08/21 [ generics] Moving forward with the generics design draft
as two comparison expressions. ˒ It can also be read as a call to w, instantiated with the types x and y, taking z as an argument. Why not use the syntax F<T> like C++ and Java?
of type x(T)—that is, the type x instantiated with the type parameter T. ˒ But it can also be read as a parameter named x with type T. Why not use the syntax F(T)?
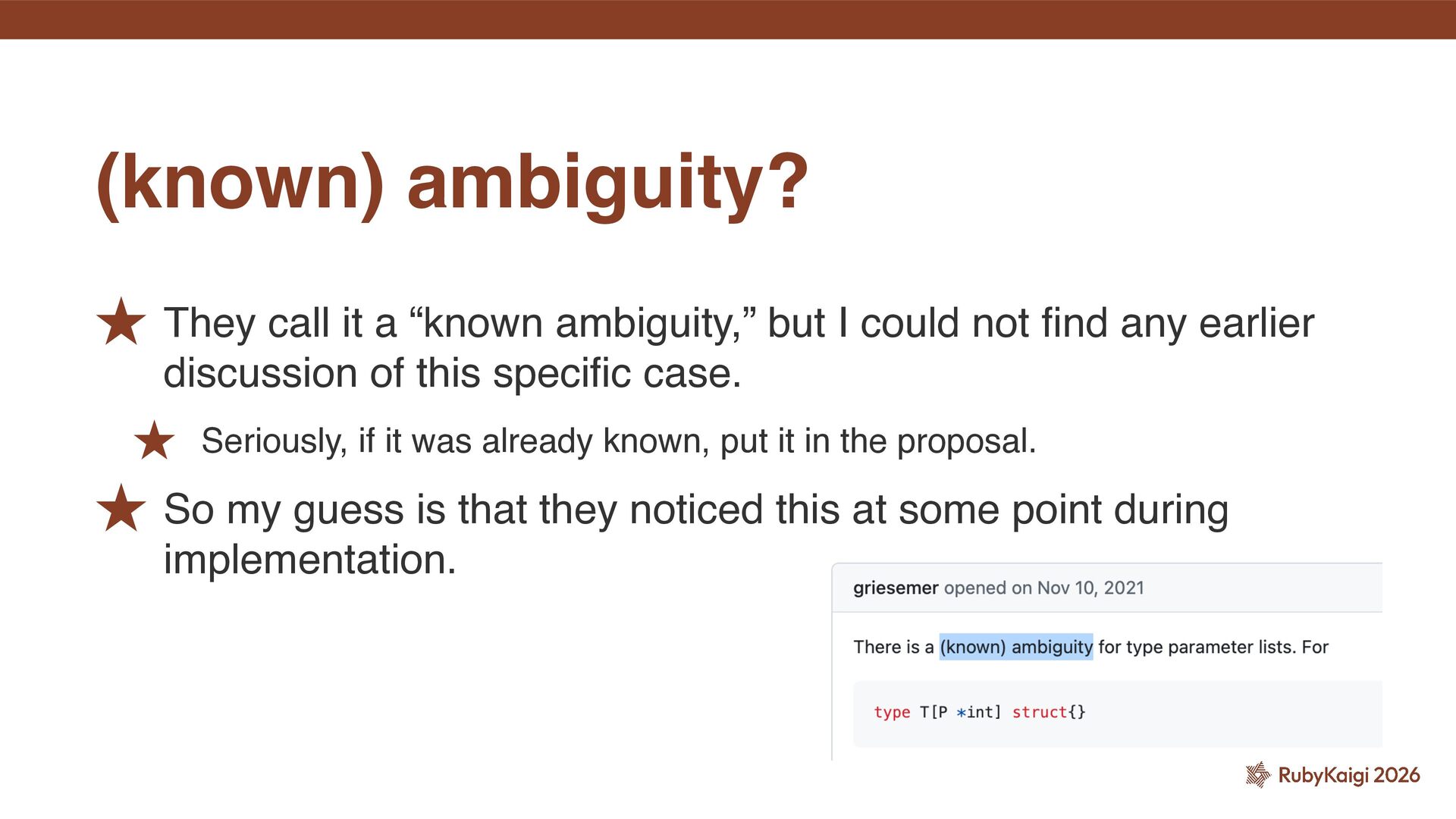
not fi nd any earlier discussion of this speci fi c case. ˒ Seriously, if it was already known, put it in the proposal. ˒ So my guess is that they noticed this at some point during implementation. (known) ambiguity?
the syntax still has to be parsed, right? Why not try using AI or something? As they say, use whatever is available—even your parents, if they are standing there. そうは言っても文法は管理しないといけないし 構文は解析しないといけないでしょ? AIとか試してみたら? 立ってるものは親でも使えってね
a rescue b in c, which is currently parsed as (x = (a rescue b)) in c, is instead parsed as x = (a rescue (b in c)). … In parse.y, when handling arg keyword_in, I changed it so that b in c is folded into the body of rescue only when the left-hand side is a simple assignment or an endless def / defs, and the right-hand side is a modi fi er rescue. The core of the implementation is in parse.y (line 1660), and the call site is in parse.y (line 3565).
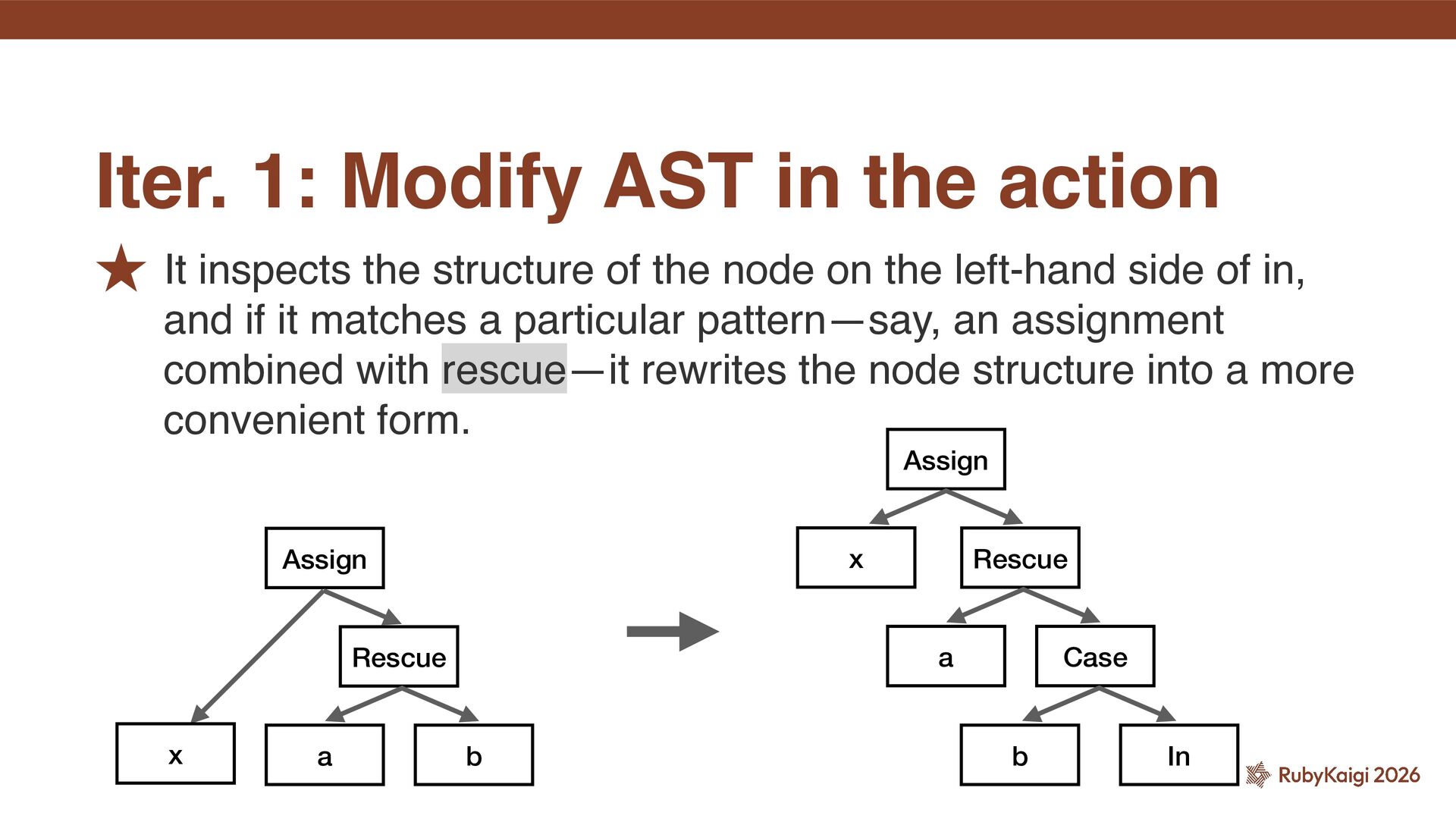
left-hand side of in, and if it matches a particular pattern—say, an assignment combined with rescue—it rewrites the node structure into a more convenient form. Iter. 1: Modify AST in the action Assign Rescue x a b Rescue a Case b In Assign x
the semantic action, try achieving it by changing the production rules themselves. Revised parse.y so that it no longer relies on post hoc AST rewriting, and instead resolves the issue through the production rules alone. I added a long, dedicated rule for rescue ... in ..., and assigned %prec tLOWEST to the shorter ... rescue ... side so that keyword_in is picked up fi rst. At the same time, I introduced a pattern entry point speci fi cally for the right-hand side of rescue, so that |, .., …, and => can be parsed without breaking ordinary pattern matching.
fi nitions and right- hand sides of assignments that involve both rescue and in. ˒ It also adjusts precedence to prevent reduction when in is present. ˒ Fair enough, I guess. Iter. 2: New production rules
a result, compared with p_top_expr_body, what p_rescue_expr mainly restricts is top-level abbreviated forms. What it does not allow: * bare array patterns: a, b * bare rest/tail patterns: *a, a, *rest * bare fi nd patterns * bare hash patterns: a:, a: 1, **rest
just the in case. I changed the => side as well so that it is handled directly by the grammar rules. I added long, dedicated rescue ... => ... rules to arg_rhs and endless_arg, so that x = a rescue b => c and def f = a rescue b => c are now parsed as x = (a rescue (b => c)) and def f = (a rescue (b => c)), respectively.
adding restrictions to patterns—is also one worth considering. ˒ Allow it only in assignments that aren't arg rule ˒ As for the implementation, I would like to see it shared a bit more with the existing rules. ˒ That would require adding new functionality to the generator. ˒ Overall, it is not as bad as I expected. Impressions
Adding %prec keyword_in gives that reduce side the same low precedence as keyword_in. Since | has higher precedence than that, the parser chooses to shift |. In fact, the report says: * Con fl ict between reduce by "p_rescue_as -> p_rescue_alt" and shift '|' resolved as shift ("'in'" < '|')
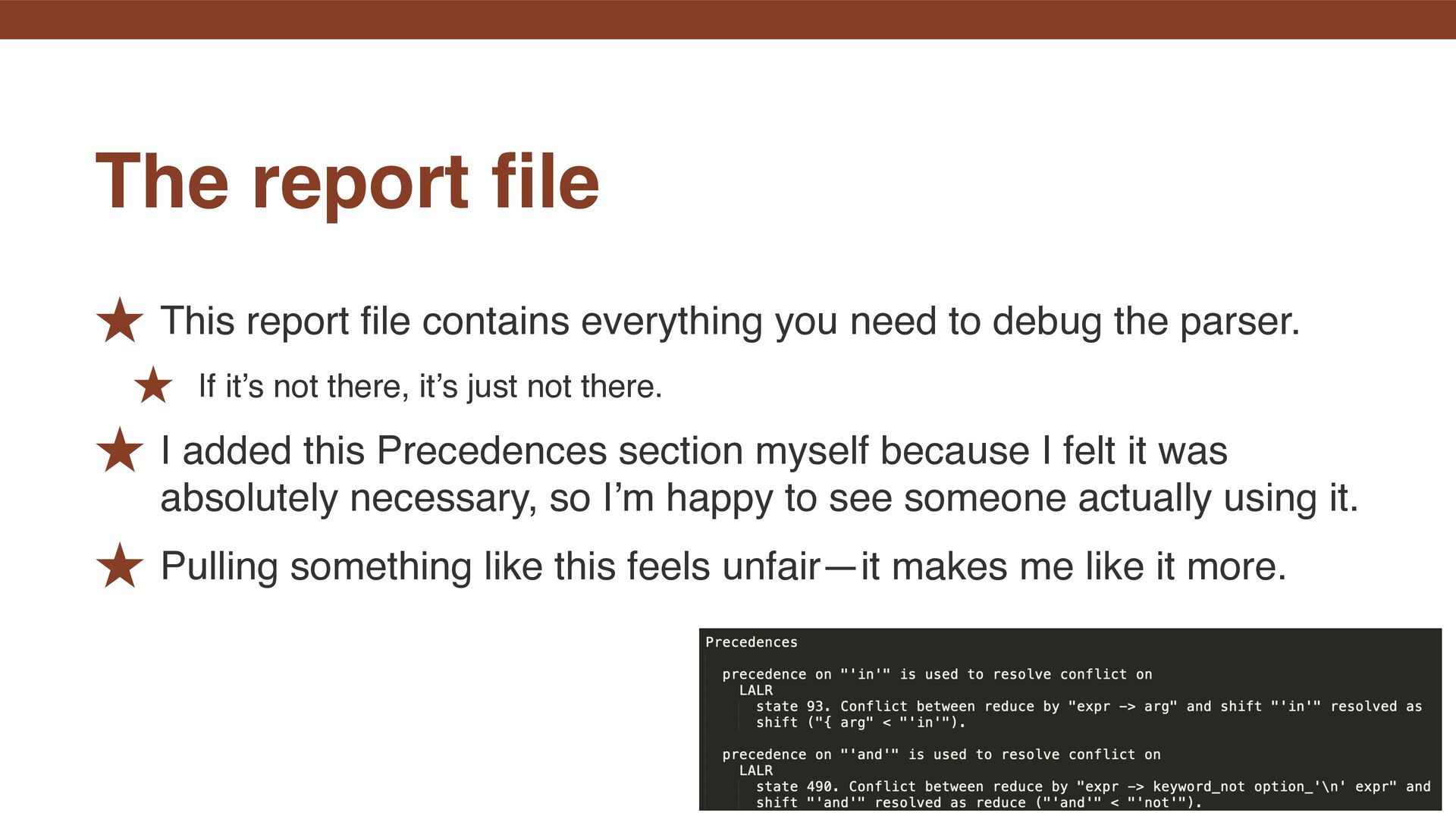
debug the parser. ˒ If it’s not there, it’s just not there. ˒ I added this Precedences section myself because I felt it was absolutely necessary, so I’m happy to see someone actually using it. ˒ Pulling something like this feels unfair—it makes me like it more. The report fi le
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Chapter 1 [Pratt 1973]](https://files.speakerdeck.com/presentations/44ec784275b647ab8f6e8e07408e6109/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}