Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 / Deep Multi-Modal Sets
Search
chck
June 29, 2020
Research
31
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文読み会 / Deep Multi-Modal Sets
社内論文読み会、PaperFridayでの発表資料です
chck
June 29, 2020
More Decks by chck
See All by chck
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.8k
CyberAgent AI Lab研修 / Container for Research
chck
1
2.4k
CyberAgent AI Lab研修 / Code Review in a Team
chck
3
2.4k
論文読み会 / Socio-Technical Anti-Patterns in Building ML-Enabled Software: Insights from Leaders on the Forefront
chck
0
140
CyberAgent AI事業本部MLOps研修Container編 / Container for MLOps
chck
3
6k
論文読み会 / GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models
chck
0
96
論文読み会 / On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
chck
0
73
論文読み会 / GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
chck
0
69
Other Decks in Research
See All in Research
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
Claude Code × autoresearch 実践
mathbullet
0
210
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
4.1k
議論 学術ムーブメントを成功させるために何が必要なのだろうか
rmaruy
0
100
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
480
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
IA for theory
gpeyre
0
270
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
220
Featured
See All Featured
A Modern Web Designer's Workflow
chriscoyier
698
190k
The Language of Interfaces
destraynor
162
27k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
My Coaching Mixtape
mlcsv
0
170
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
340
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
The Spectacular Lies of Maps
axbom
PRO
1
860
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Bash Introduction
62gerente
615
220k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
420
Transcript
Deep Multi-Modal Sets 20/06/29 PaperFriday, Yuki Iwazaki@AI Lab
2 Point: 特徴のDown SamplingやScalabilityを考慮した Multi-Modal Encoderを提案 Authors: Austin Reiter, Menglin
Jia, Pu Yang, Ser-Nam Lim - Facebook AI Research, Cornell University 選定理由: - Creative Researchのslackでちょっと話題に出た - 俺より強いマルチモーダル表現に会いに行く
The Multi-Modal Problem 3
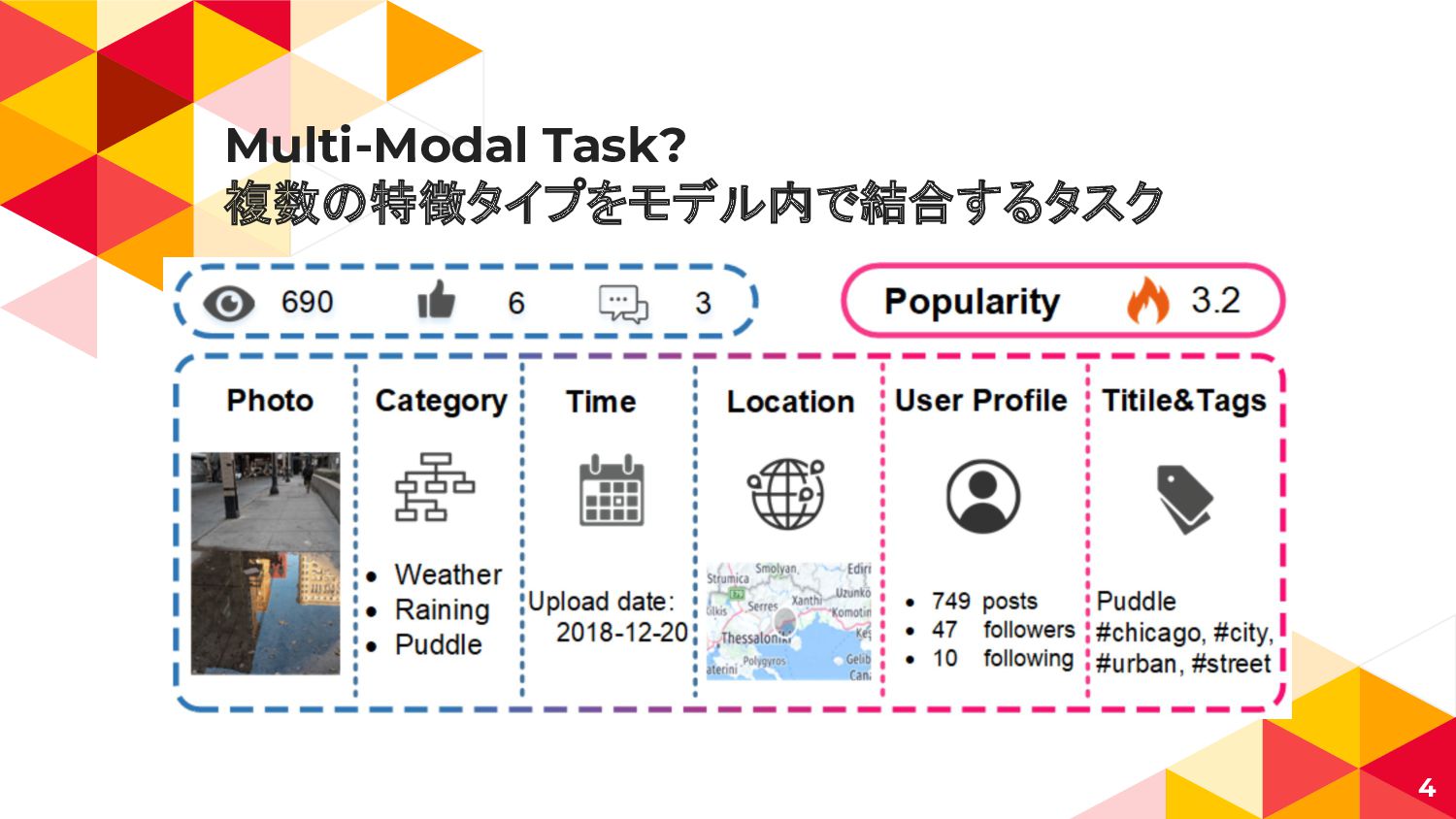
Multi-Modal Task? 複数の特徴タイプをモデル内で結合するタスク 4
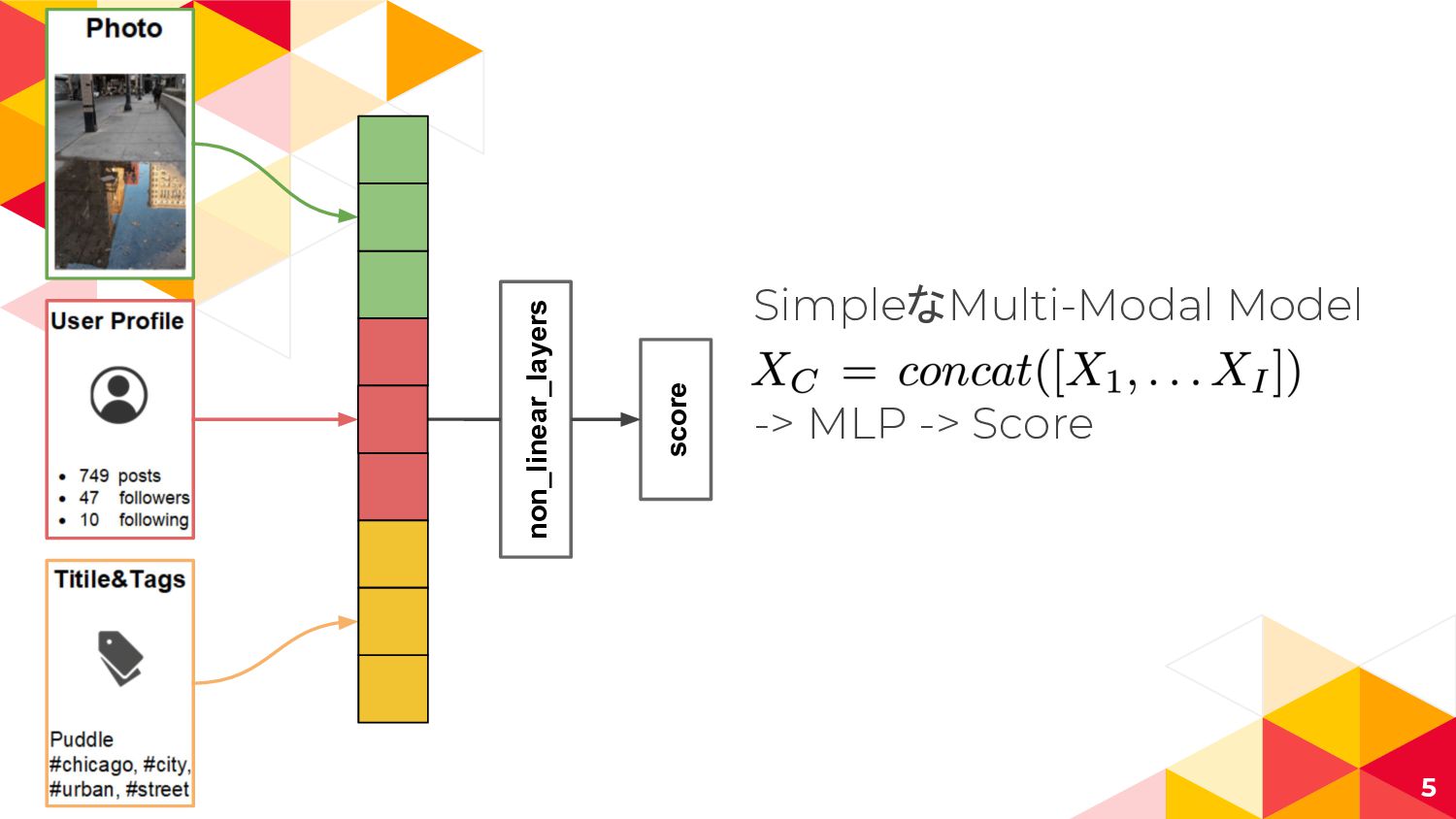
non_linear_layers score 5 SimpleなMulti-Modal Model XC = concat([X1, . .
. XI ]) -> MLP -> Score
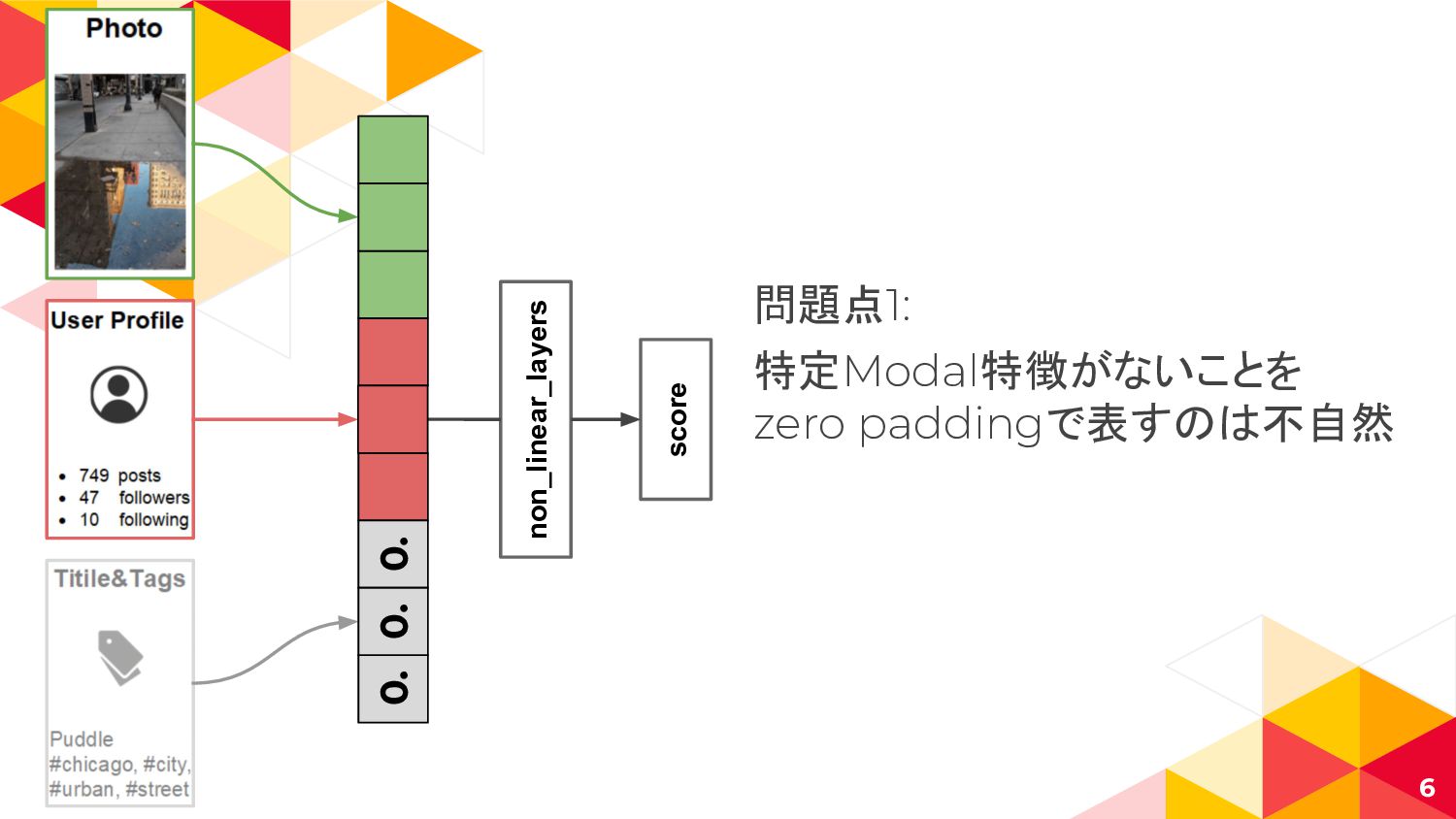
non_linear_layers score 6 問題点1: 特定Modal特徴がないことを zero paddingで表すのは不自然 0. 0. 0.
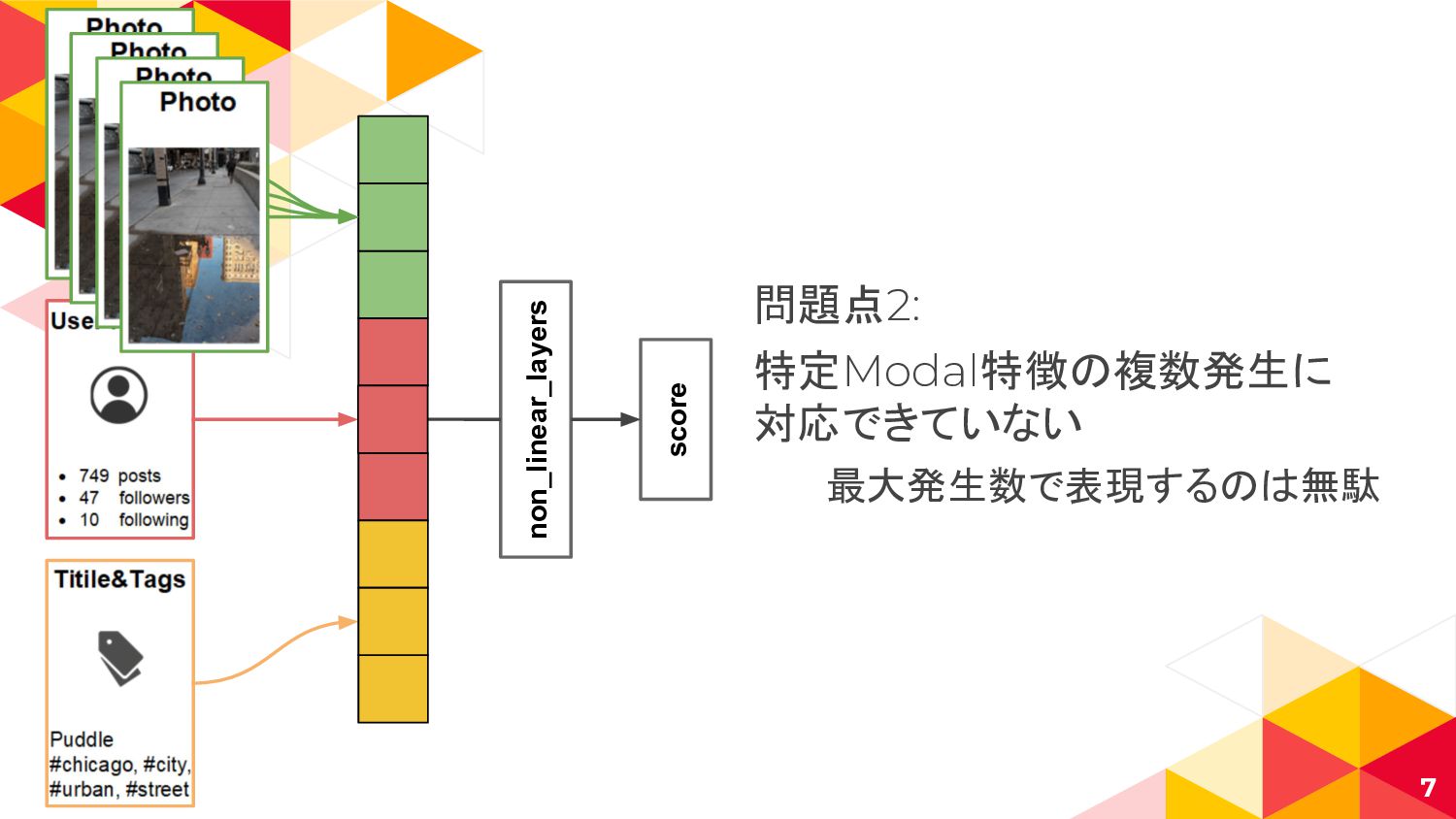
non_linear_layers score 7 問題点2: 特定Modal特徴の複数発生に 対応できていない 最大発生数で表現するのは無駄
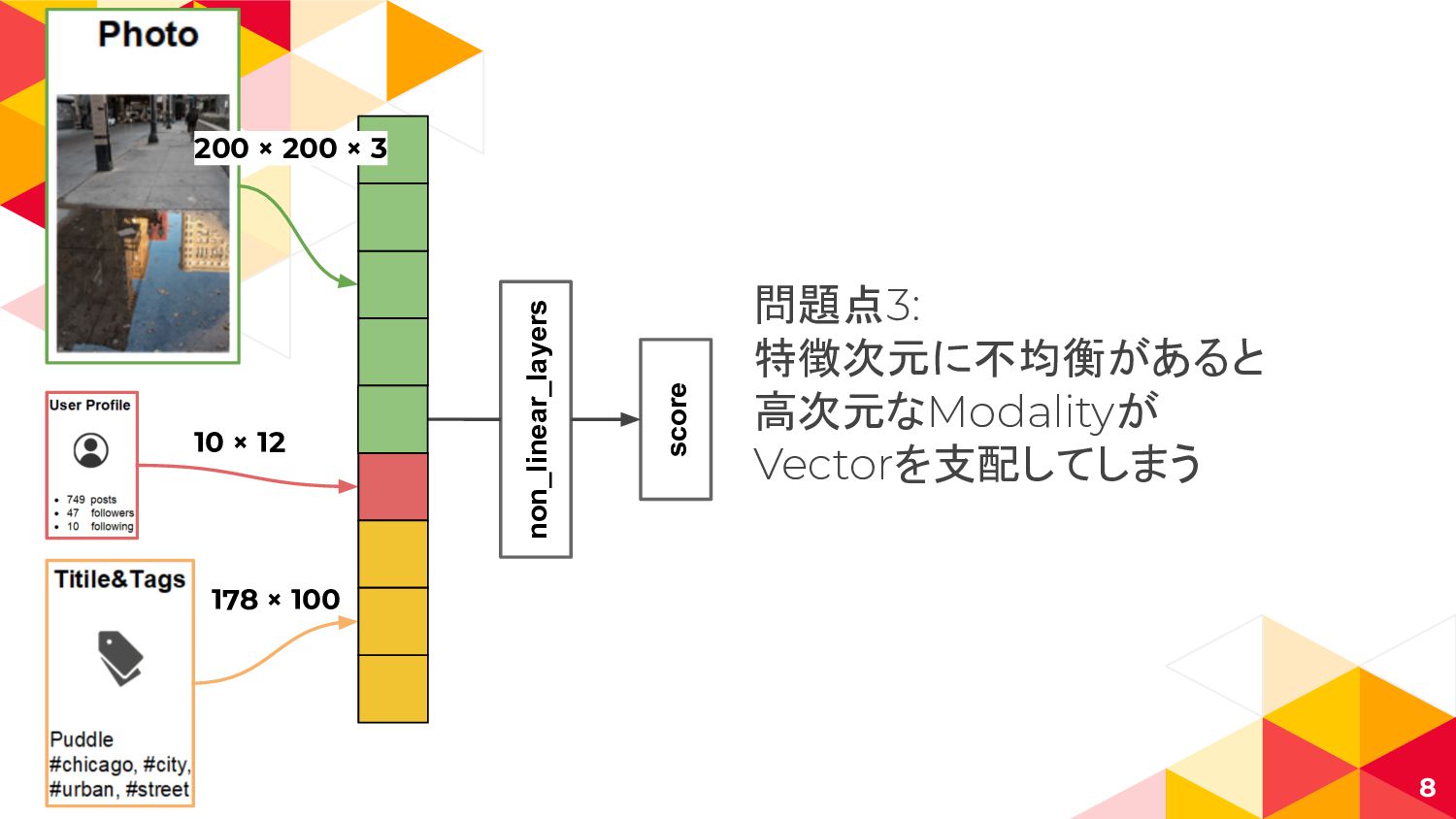
non_linear_layers score 8 問題点3: 特徴次元に不均衡があると 高次元なModalityが Vectorを支配してしまう 10 × 12
178 × 100 200 × 200 × 3
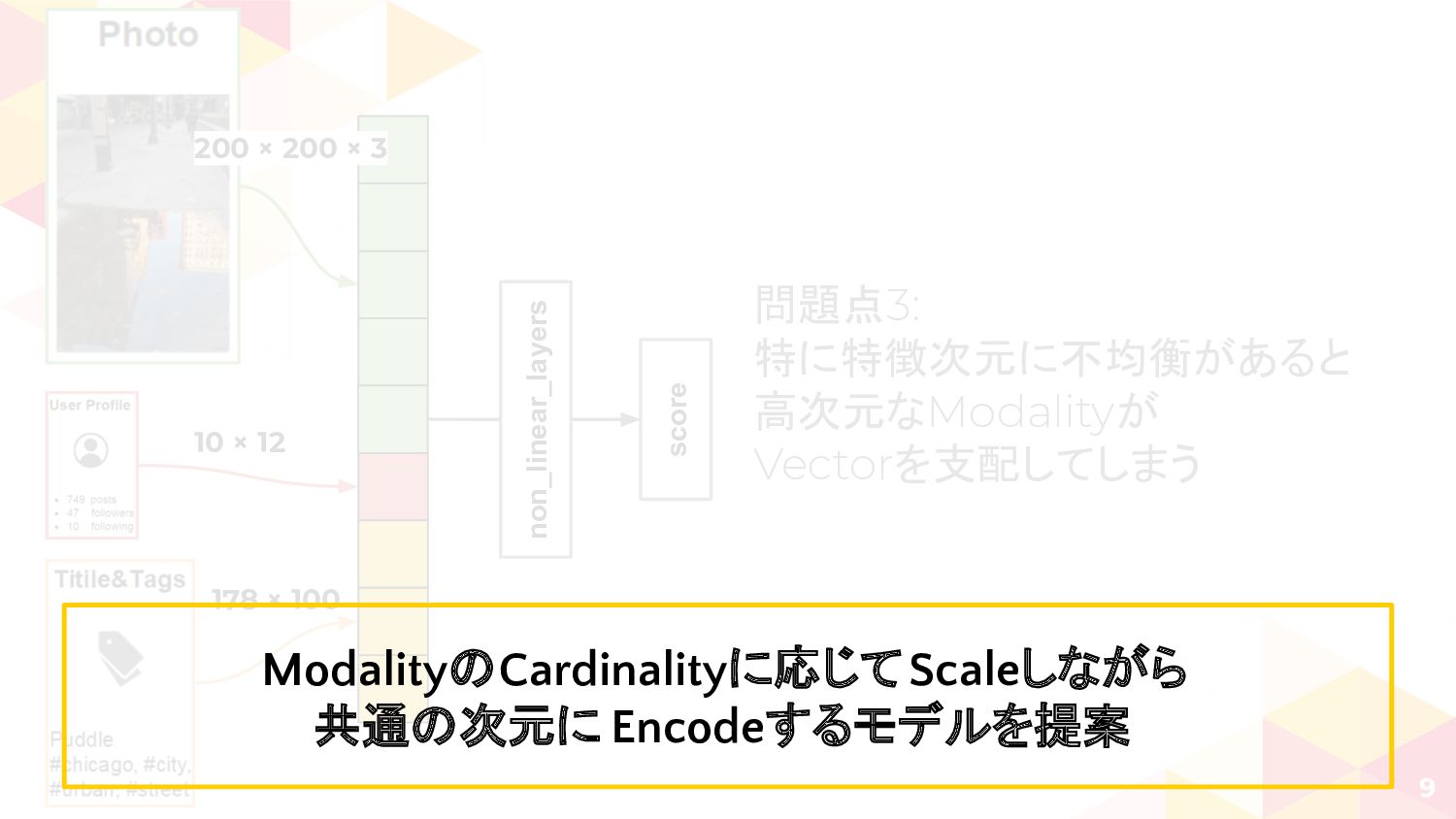
non_linear_layers score 9 問題点3: 特に特徴次元に不均衡があると 高次元なModalityが Vectorを支配してしまう 10 × 12
178 × 100 200 × 200 × 3 ModalityのCardinalityに応じてScaleしながら 共通の次元に Encodeするモデルを提案
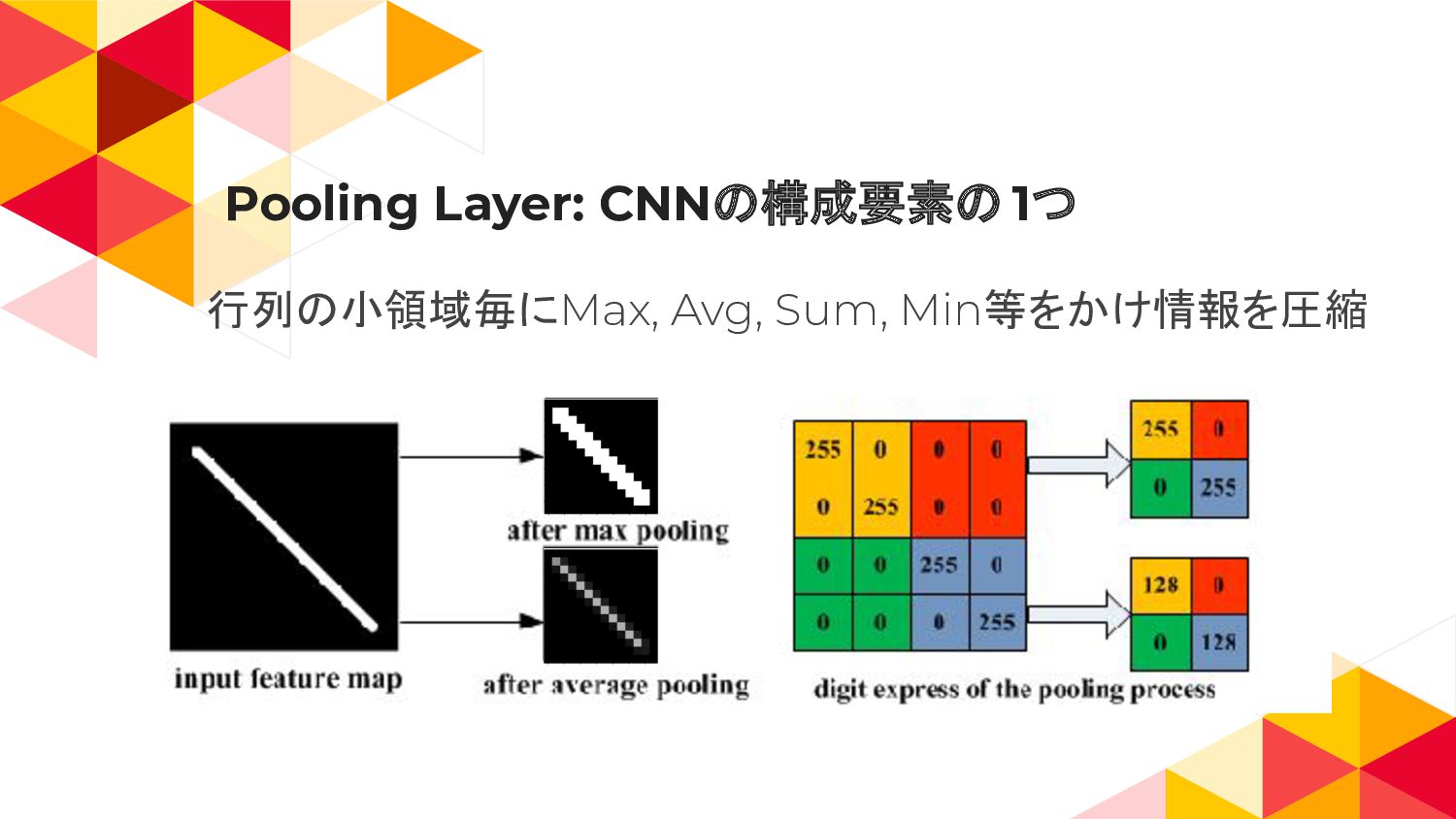
Pooling Layer 10
Pooling Layer: CNNの構成要素の 1つ 行列の小領域毎にMax, Avg, Sum, Min等をかけ情報を圧縮
Deep Sets 12
Deep Sets [Zaheer, 17] CNN(Pooling)の位置不変性を利用して Scalableな埋め込み表現を学習するモデル CNNでいう画像サイズが変わろうが、GCNでいうユー ザに対するアイテムの順番が変わろうが、 各要素、特徴自体の位置はPoolingのおかげで 大きく変わらない
15 Graph Convolutional Network
Proposed Method 16
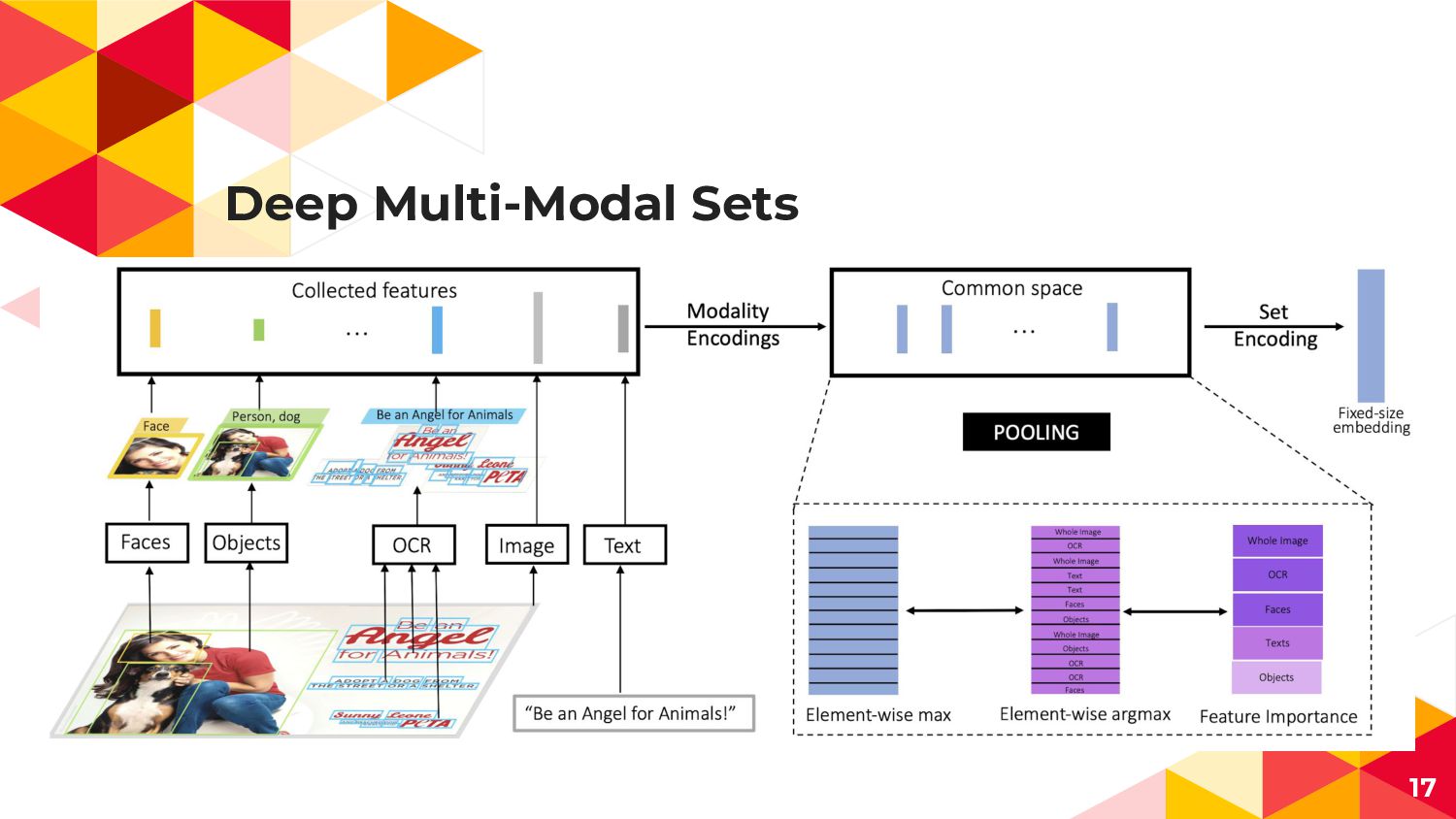
Deep Multi-Modal Sets 17
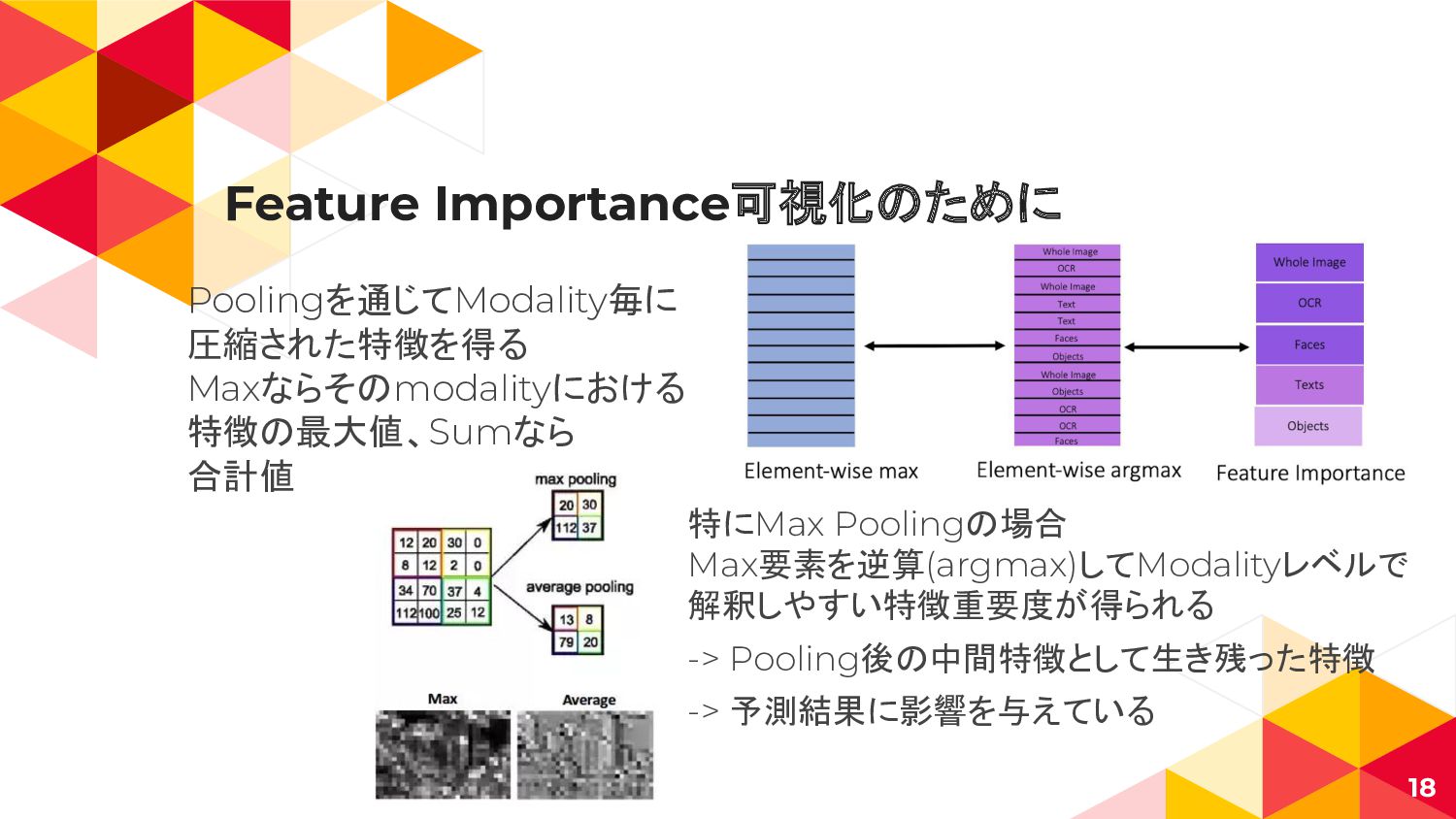
Feature Importance可視化のために Poolingを通じてModality毎に 圧縮された特徴を得る Maxならそのmodalityにおける 特徴の最大値、Sumなら 合計値 18 特にMax Poolingの場合
Max要素を逆算(argmax)してModalityレベルで 解釈しやすい特徴重要度が得られる -> Pooling後の中間特徴として生き残った特徴 -> 予測結果に影響を与えている
Experiments 19
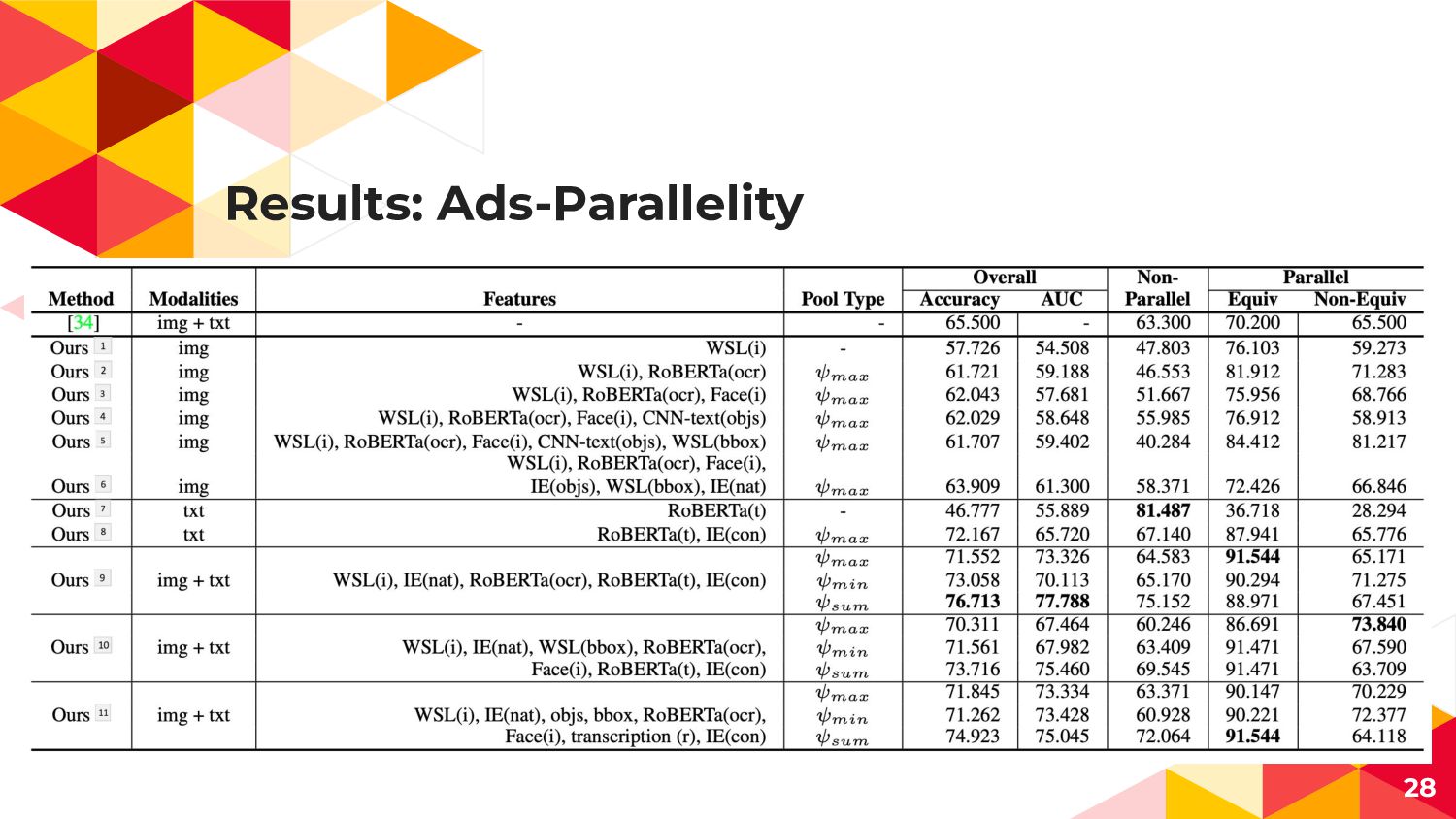
Datasets: Ads-Parallelity Dataset 広告画像 + 説明文-> 関係性 Parallelity: ImageとTextが一貫して同じメッセージ性を持つか (どちらかがなくても伝わるか)
20
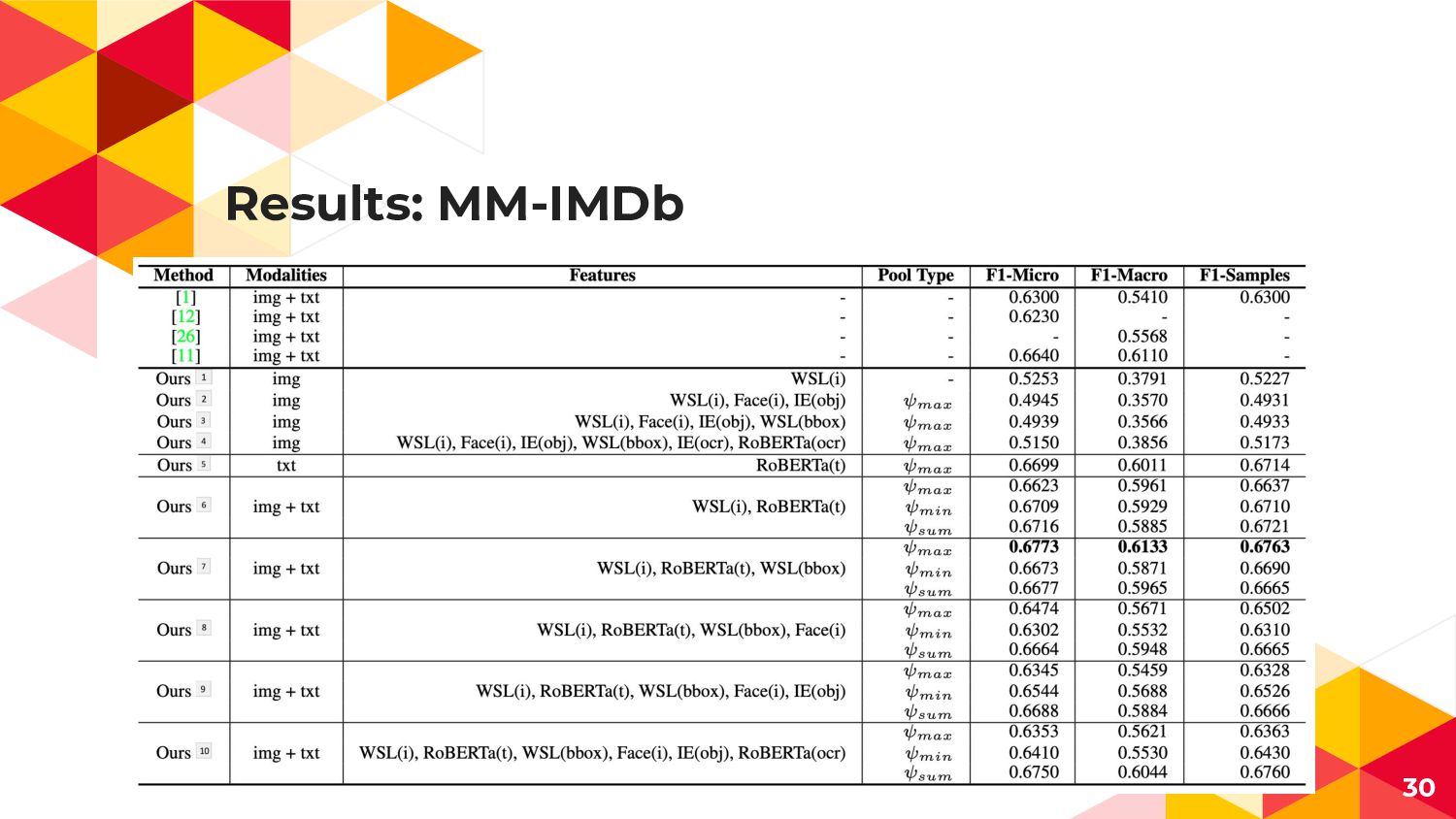
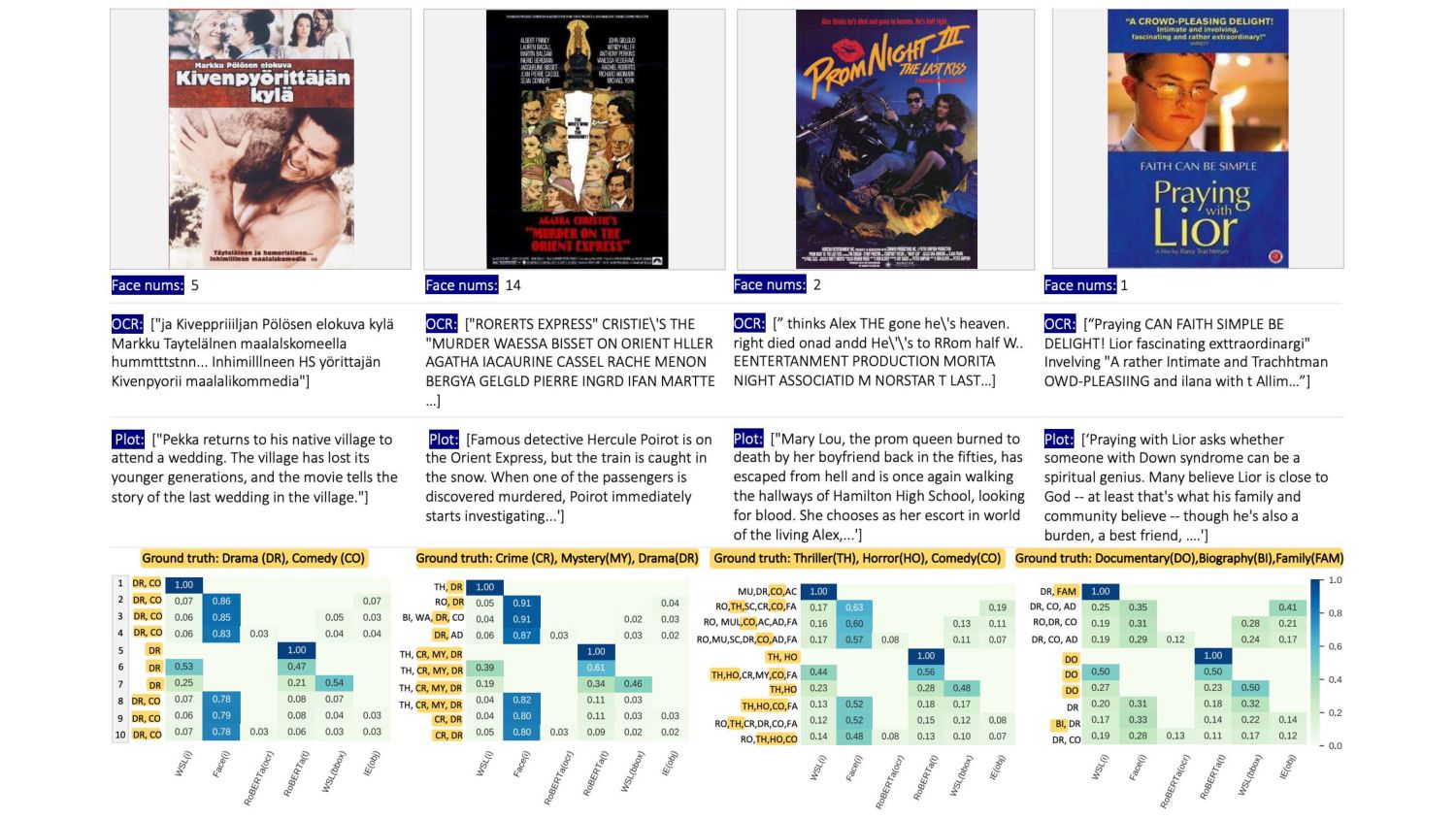
Datasets: MultiModal-IMDb 映画のジャケ画像 + 説明文 -> 映画のジャンル 21
Features 22
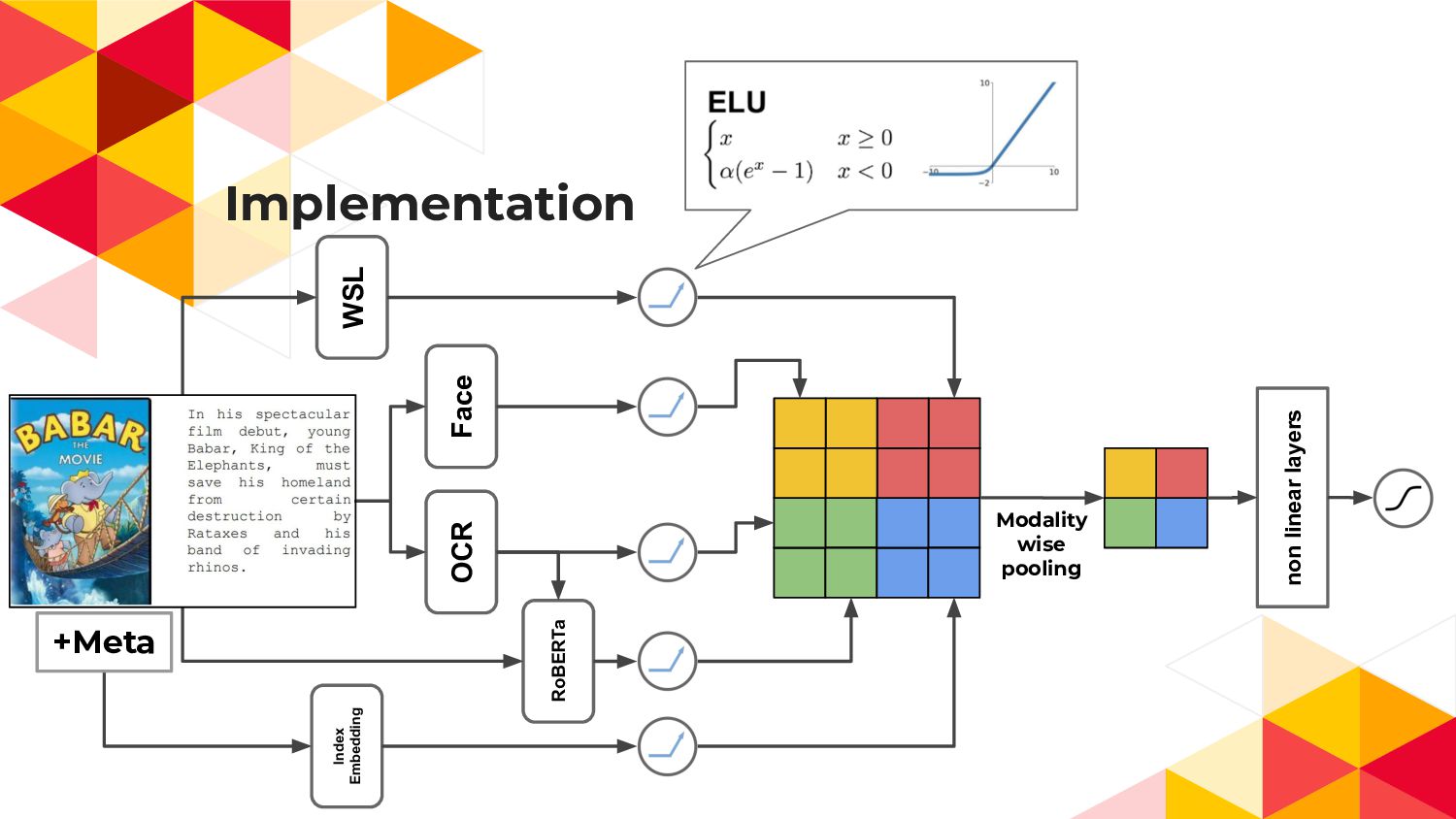
Implementation non linear layers Modality wise pooling WSL Face OCR
RoBERTa Index Embedding +Meta
Results: Ads-Parallelity 28
None
Results: MM-IMDb 30
None
Conclusion 37
Conclusion and Future Work ◂ DynamicなModalityをうまくモデリングできる Multi-Modal Architectureを提案 ◂ PoolingがDown
Samplingのように働く ◂ Max-Poolingを用いた重要度の可視化 ◂ エラー分析が容易に ◂ Videoへの拡張が今後の課題 38
Comment - Pooling自体はシンプルで直感的なので実装しやすい - 特徴抽出器まではfreezeなので計算コストも低そう - Pooling Encoderの出力次元Dがハイパラで肝 - Adsは32次元,
MM-IMDbは1024次元らしい - 説明文(RoBERTa)だけでそこそこ精度が出ている気がする - タスクによるが説明文があればOCRテキストはそこまで要らない? - OCR自体の検出性能が絡んでいそう 39
References - Permutation-equivariant neural networks applied to dynamics prediction -
Graph Neural Networks and Permutation invariance - Connections between Neural Networks and Pure Mathematics - Deep Sets 40
41 Thanks! Any questions? You can find me at ◂
@chck ◂ #times_chck ◂
[email protected]
Feedback - 特徴抽出器もコミコミのe2e? - GPUも1枚なのでおそらく抽出後が入力 - それはそれで実装が重いですね - pooling type結局どれがいいのか
- 精度大差ないのでFeature Importanceとの兼ね合いで Maxでいいのでは
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Deep Sets [Zaheer, 17] CNN(Pooling)の位置不変性を利用して Scalableな埋め込み表現を学習するモデル CNNでいう画像サイズが変わろうが、GCNでいうユー ザに対するアイテムの順番が変わろうが、 各要素、特徴自体の位置はPoolingのおかげで 大きく変わらない](https://files.speakerdeck.com/presentations/7272a151c9e0464ebc4428569c3edb93/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}