Presented at The College Art Association 2017 annual conference.
In his 1962 book "The Shape of Time", George Kubler wrote, "it is disturbing to those who value the individuality of a thing to have that individuality diminished by classifications and generalizations." (36) This suspicion is as relevant as ever, as specialists in machine learning make ever-more boisterous claims about their ability to mine insights from artistic databases, such as a recent project that claimed to identify "the most creative paintings of all time." (Elgammal and Saleh 2015, http://arxiv.org/abs/1506.00711) Art historians have rightly challenged the implicit impartiality of these researchers' data sources and methods, and contested the intellectual coherence of their stated goals.
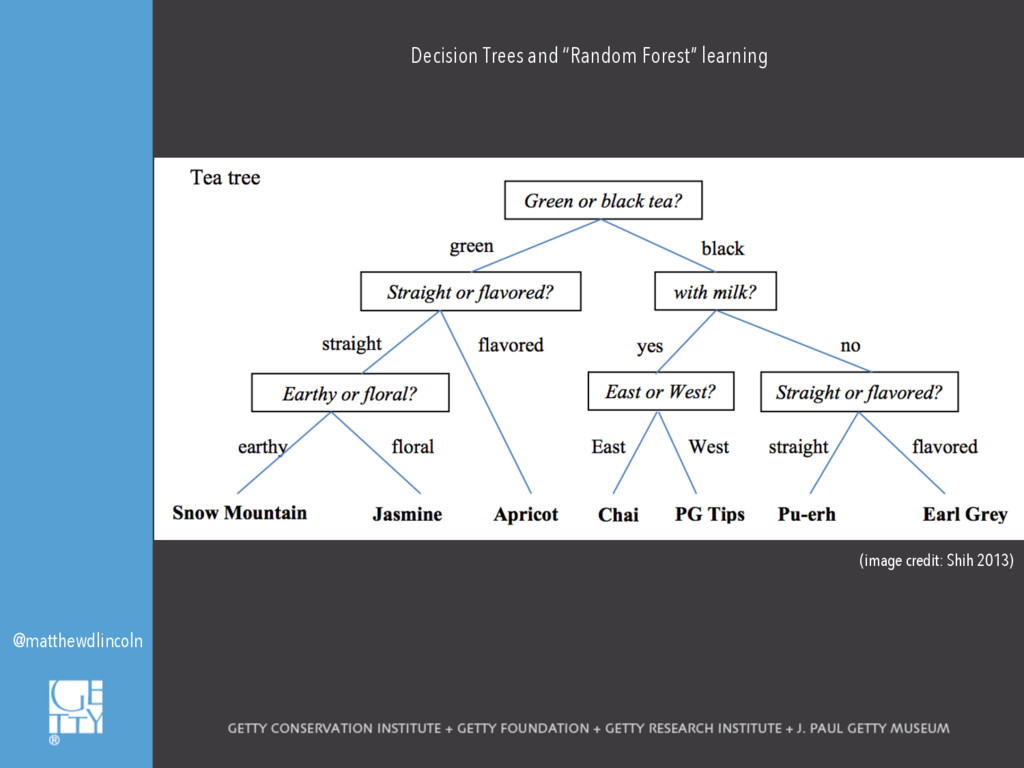
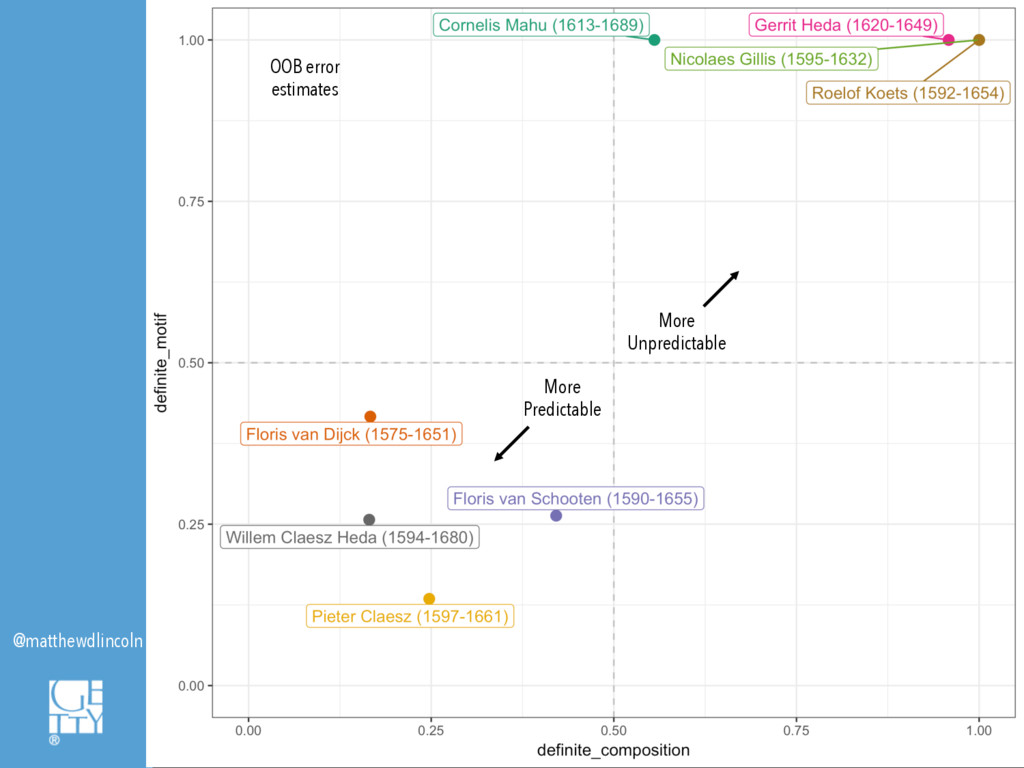
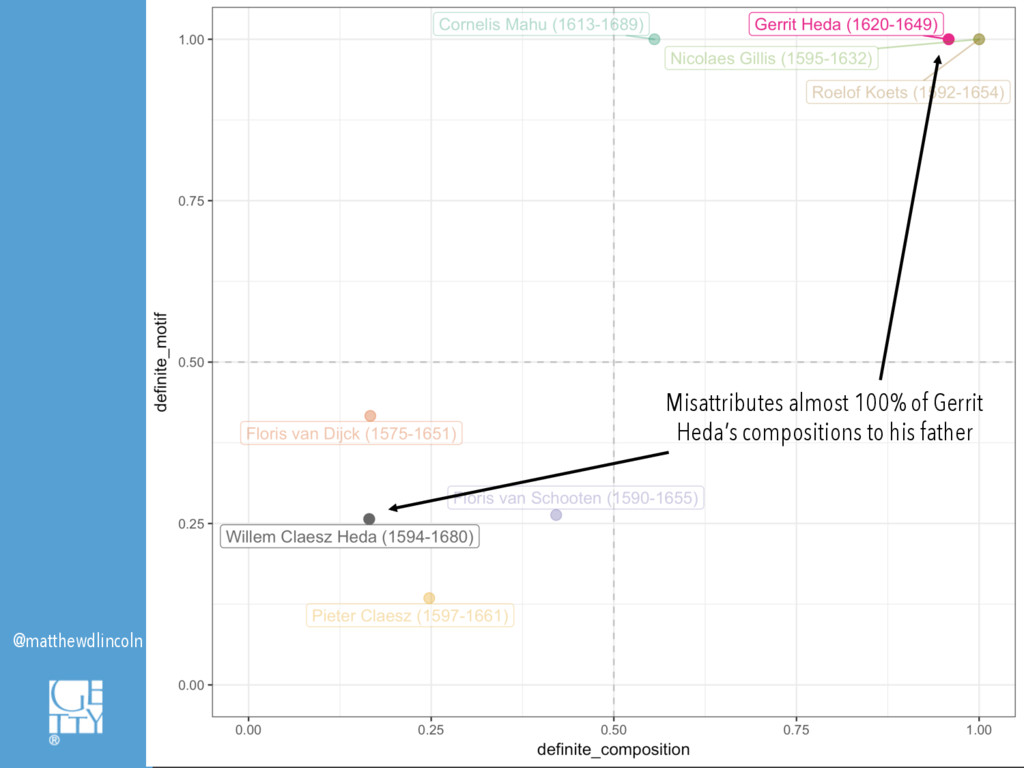
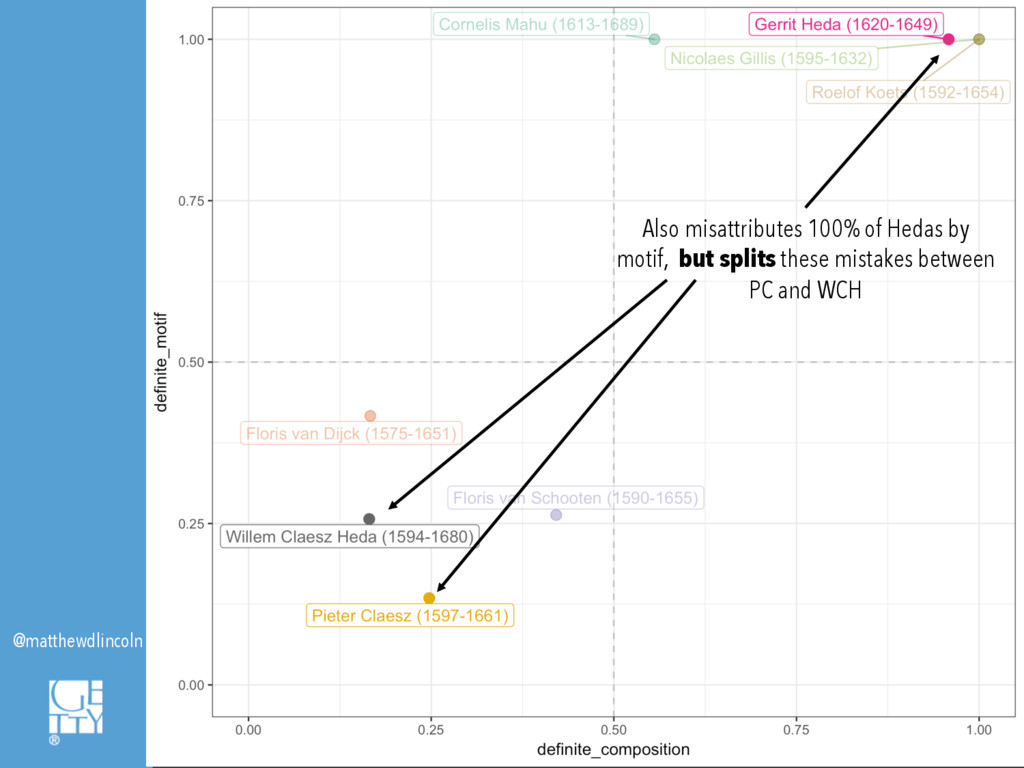
However, what might a digital art history look like that deploys machine learning precisely in order to see where the machine breaks? This paper will explore the conditions in which computational models fail to predict or classify, demonstrating how these instances can provoke new questions or analytical approaches. I will discuss a case study in which supervised machine classification was used to analyze a database of seventeenth-century Haarlem still life paintings. The computer's comparative ability, or inability, to discern the shape of different artists' oeuvres based on limited information about composition or subject matter suggested how these painters, as well as those who imitated them, defined their artistic personae. Where the machine breaks, and where it succeeds, also help to surface how decisions as fundamental as one's chosen framework for visual description can fundamentally alter the synthetic historical narratives that one ultimately composes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}