Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWS DeepRacerで最適な行動・報酬関数を得る為の試行錯誤
Search
貞松政史
May 16, 2019
Technology
2.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWS DeepRacerで最適な行動・報酬関数を得る為の試行錯誤
2019/05/16 DeepRacer同好会 第二回オフライン勉強会@大阪 のセッションスライドです。
貞松政史
May 16, 2019
More Decks by 貞松政史
See All by 貞松政史
Amazon Forecast亡き今、我々がマネージドサービスに頼らず時系列予測を実行する方法
sadynitro
0
1.4k
今日のハイライトをシステマティックに
sadynitro
1
95
はじめてのレコメンド〜Amazon Personalizeを使った推薦システム超超超入門〜
sadynitro
2
2.7k
予知保全利用を目指した外観検査AIの開発 〜画像処理AIを用いた外観画像に対する異常検知〜
sadynitro
0
1.4k
20230904_GoogleCloudNext23_Recap_AI_ML
sadynitro
0
1k
Foundation Model全盛時代を生きるAI/MLエンジニアの生存戦略
sadynitro
0
1.1k
Amazon SageMakerが存在しない世界線 のAWS上で実現する機械学習基盤
sadynitro
0
330
Amazon SageMakerが存在しない世界線のAWS上で実現する機械学習基盤
sadynitro
0
2.2k
みんな大好き強化学習
sadynitro
0
1.4k
Other Decks in Technology
See All in Technology
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
310
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
490
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
620
AI時代の EM への処方箋
staka121
PRO
0
130
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
2.8k
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
240
Claude Code 珍プレー好プレー
shinyasaita
0
320
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.6k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
170
Featured
See All Featured
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Abbi's Birthday
coloredviolet
3
8.6k
The Curse of the Amulet
leimatthew05
2
13k
How STYLIGHT went responsive
nonsquared
100
6.2k
Leo the Paperboy
mayatellez
8
1.9k
Docker and Python
trallard
47
3.9k
The Pragmatic Product Professional
lauravandoore
37
7.4k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
First, design no harm
axbom
PRO
2
1.2k
Transcript
AWS DeepRacerで 最適な⾏動・報酬関数を得る為の試⾏錯誤 クラスメソッド株式会社 データインテグレーション部 2019.5.16 DeepRacer同好会 第⼆回オフライン勉強会@⼤阪 貞松 政史
1
2 本⽇のハッシュタグ #AWSDeepRacerJP
3 ⾃⼰紹介 貞松 政史 (サダマツ マサシ) @sady_nitro データインテグレーション部 (DI部) 開発チーム
岡⼭オフィス勤務 データ分析基盤開発 某コーヒー関連 SageMaker Lambda ⽒名 所属 近況 好きなAWS サービス
4 本セッションから得てほしいこと DeepRacer 楽しい︕
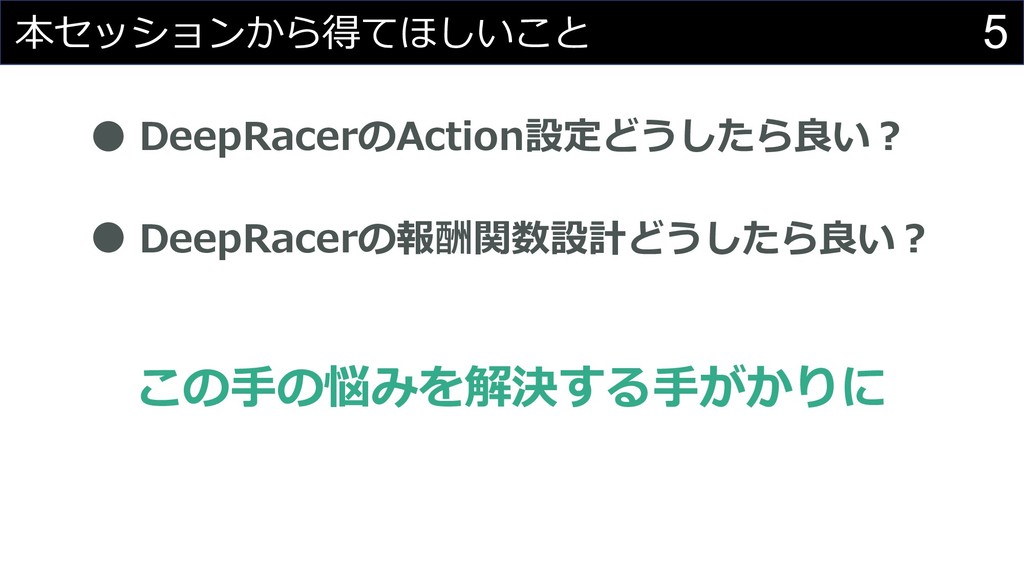
5 本セッションから得てほしいこと DeepRacerのAction設定どうしたら良い︖ DeepRacerの報酬関数設計どうしたら良い︖ この⼿の悩みを解決する⼿がかりに
6 本セッションで話さないこと 強化学習の⼿法(アルゴリズム)についての詳細 DeepRacerの実機を⽤いた開発
7 お品書き DeepRacerコンソールを⽤いた開発 DeepRacerのAction設定 DeepRacerの報酬関数設計 1 2 3
8 DeepRacerコンソールを⽤いた開発
9 DeepRacerコンソール
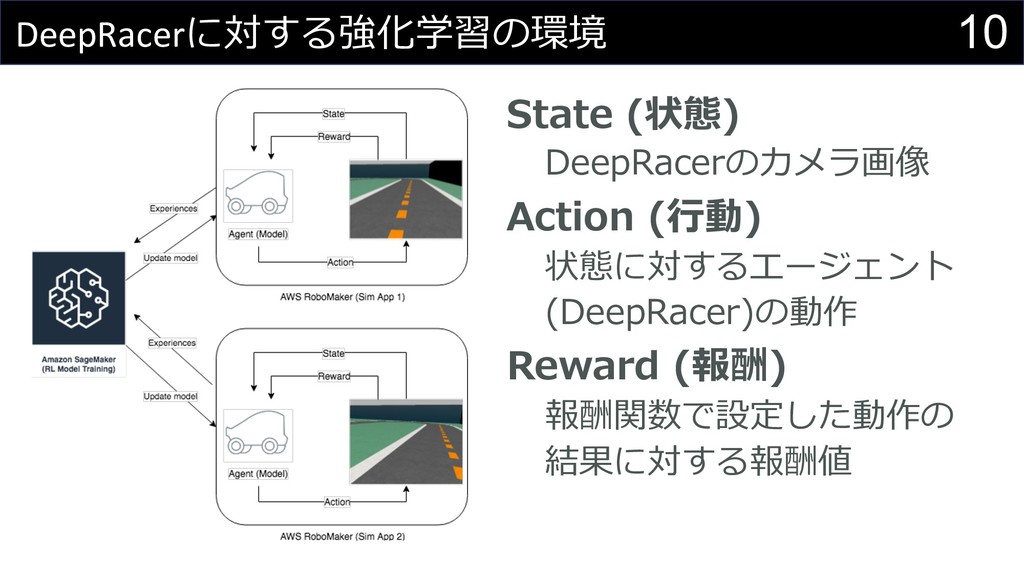
10 DeepRacerに対する強化学習の環境 State (状態) DeepRacerのカメラ画像 Action (⾏動) 状態に対するエージェント (DeepRacer)の動作 Reward
(報酬) 報酬関数で設定した動作の 結果に対する報酬値
11 DeepRacerコンソールを⽤いた開発の流れ 必要なAWSリソースを作成 学習モデルを作成・学習実⾏ 学習済みモデルの評価・デプロイ
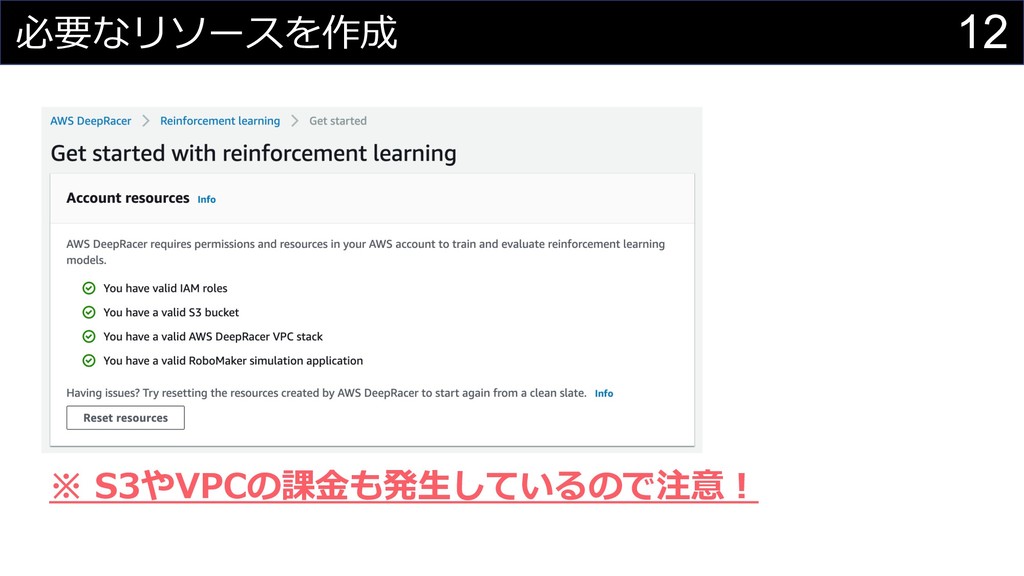
12 必要なリソースを作成 ※ S3やVPCの課⾦も発⽣しているので注意︕
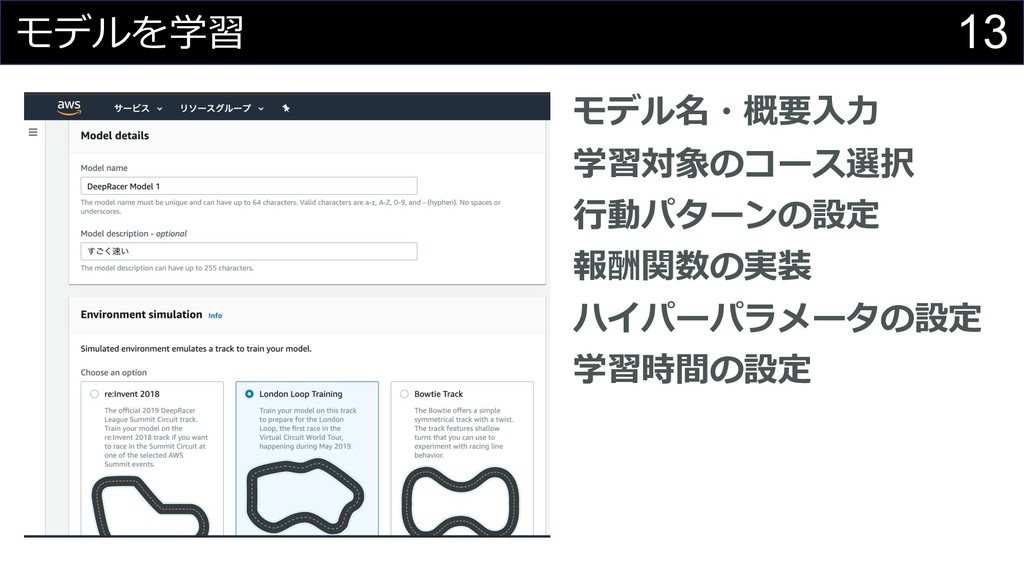
13 モデルを学習 モデル名・概要⼊⼒ 学習対象のコース選択 ⾏動パターンの設定 報酬関数の実装 ハイパーパラメータの設定 学習時間の設定
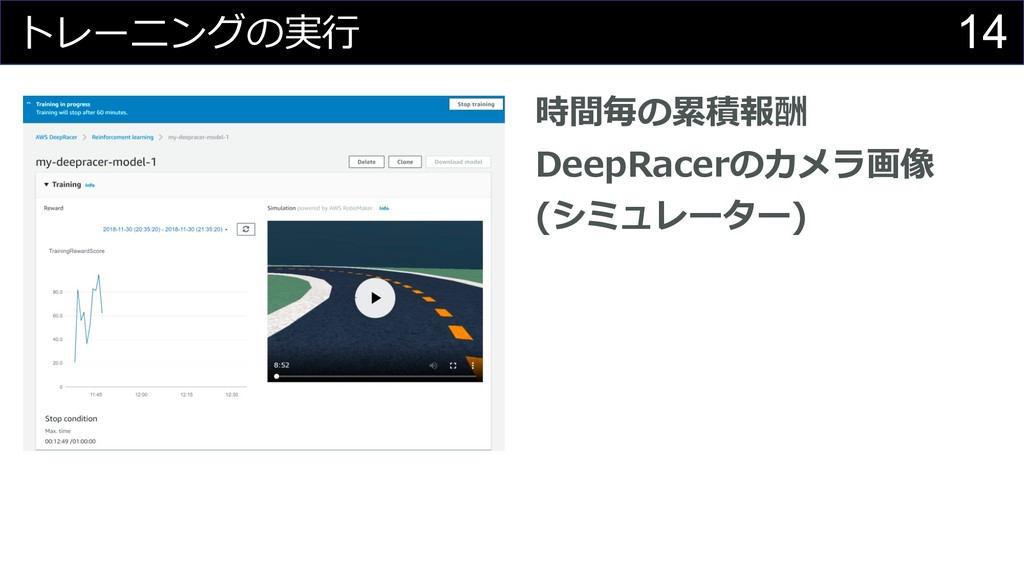
14 トレーニングの実⾏ 時間毎の累積報酬 DeepRacerのカメラ画像 (シミュレーター)
15 学習済みモデルを評価 学習済みモデルで3〜5回トライアルを⾏う ⁻ Time : 1回のトライアルでかかった時間 ⁻ Trial result
: 100%ならコース1周完⾛
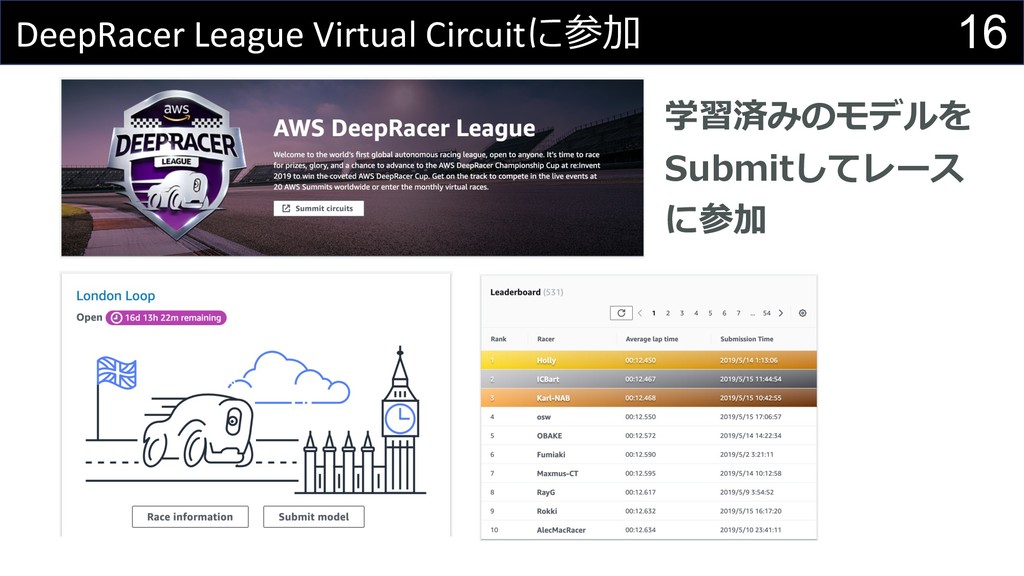
16 DeepRacer League Virtual Circuitに参加 学習済みのモデルを Submitしてレース に参加
17 参考ブログエントリー その1 https://dev.classmethod.jp/cloud/aws/aws-deepracer-virtual-circuit-join/
18 DeepRacerのAction設定
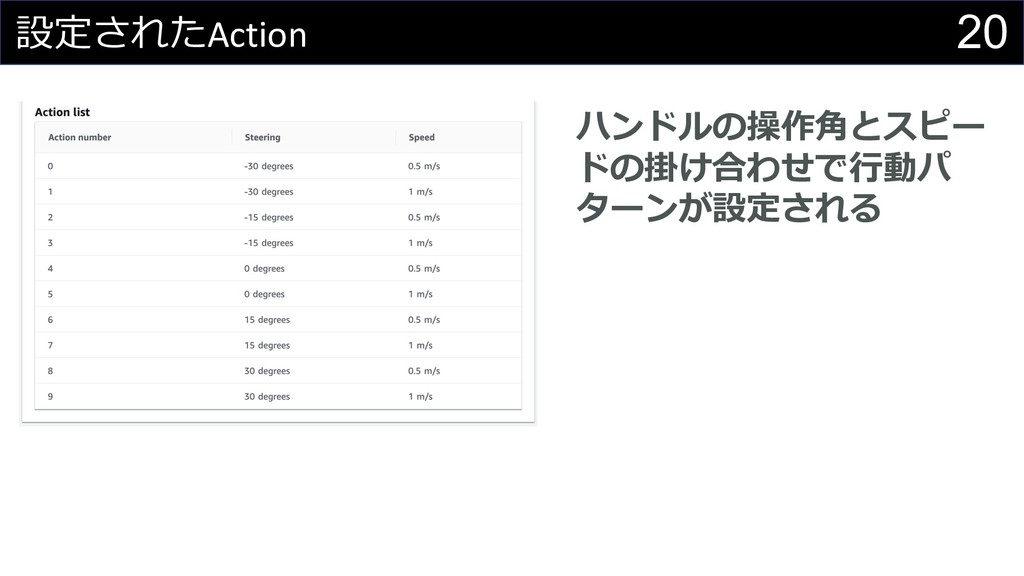
19 DeepRacerのAction設定⽅法 l ハンドルの操作⾓ l スピード(m/s) →最⼤値と⾏動数(刻み幅) で設定
20 設定されたAction ハンドルの操作⾓とスピー ドの掛け合わせで⾏動パ ターンが設定される
21 Actionを設定する上での注意点 ⾏動パターンを増やし過ぎると学習に時間が掛かる 学習ジョブのClone時は元のActionを変更できない コースの特性に合わせて設定が必要 報酬関数の設計とトータルで考える必要がある
22 DeepRacerの報酬関数設定
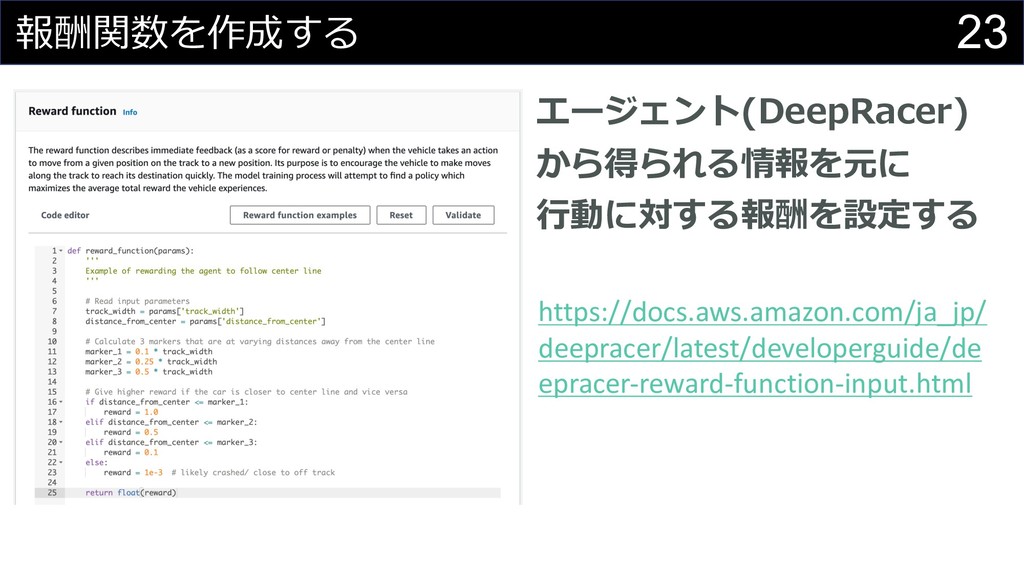
23 報酬関数を作成する エージェント(DeepRacer) から得られる情報を元に ⾏動に対する報酬を設定する https://docs.aws.amazon.com/ja_jp/ deepracer/latest/developerguide/de epracer-reward-function-input.html
24 報酬関数の例 パターン1 センターラインに沿って⾛⾏させる
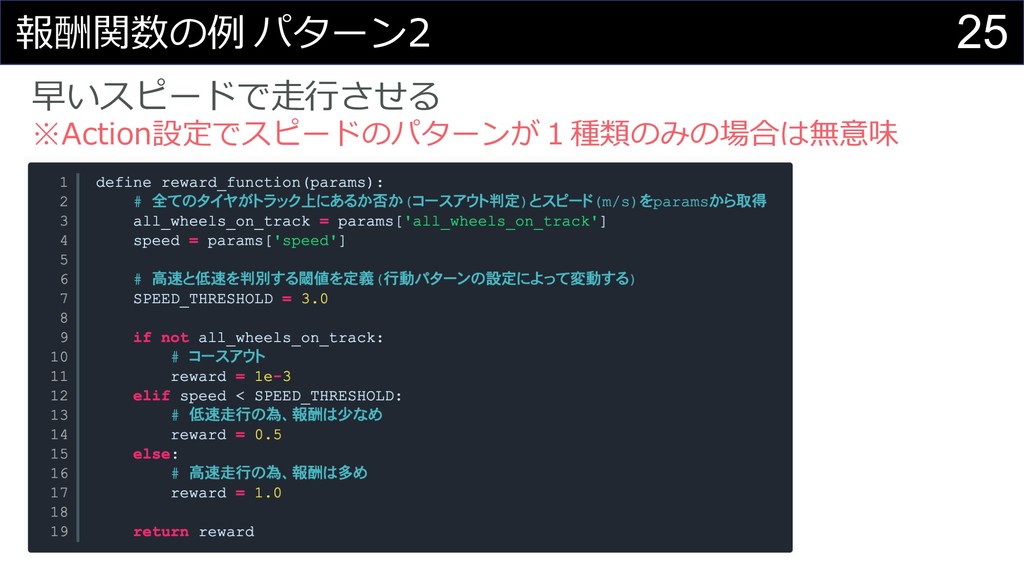
25 報酬関数の例 パターン2 早いスピードで⾛⾏させる ※Action設定でスピードのパターンが1種類のみの場合は無意味
26 報酬関数の例 パターン3 急ハンドルやジグザグ⾛⾏を抑制する
27 参考ブログエントリー その2 https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of- reward-function/
28 報酬関数を実装する際のポイント コースの特徴を捉える 適切なActionの設定を⾒極める まずは1周完⾛できるモデルになるように 報酬関数を設計する
29 コースの特徴を捉える センターラインに沿うと上⼿く いきそう キツめのカーブがいくつかある (スピードの調整が必要︖) re:Invent 2018
30 コースの特徴を捉える London Loop センターラインにびったり沿う と無駄が多そう 緩いカーブの連続で構成されて いる(速いスピードを維持する のが良さそう︖)
31 適切なAction設定を⾒極める コースの特徴や実際の動作・ログを⾒て Actionを設定する 例) スピードはトップスピード(5m/s)のみでOK ハンドル操作は-30°〜30°まで取らないと曲がりきれない etc…
32 まずは1周完⾛ 完⾛できなければ記録なしになる タイムを縮める以前の問題 all_wheels_on_track(コースアウト判定)や distance_from_center(中央線からの距離)など
33 さらなる⼯夫 取得したパラメータにする判定を厳しくする (もしくは緩くする) 条件を組み合わせる ハイパーパラメータを調整する(最後の⼿段) https://github.com/Unity-Technologies/ml- agents/blob/master/docs/best-practices-ppo.md
34 実際にモデルの学習を繰り返してわかったこと London loopをひたすら回した結果 • センターラインにびったり張り付いても速くない • 意外とフルスロットルでいける • 報酬関数は複雑なほど良いわけでは無い
• 最終的にカリッカリにタイム短縮を狙うならstepsや progressの考慮が必要…︖ • さらにカリッカリにチューニングする場合はハイパーパ ラメータの調整も⼊ってくる…︖
35 デモ的なもの
36 ⽣まれたてのDeepRacer
37 デフォルト設定で学習
38 デフォルト設定 vs ⾏動・報酬関数を調整
39 まとめ
40 まとめ DeepRacerコンソールを⽤いた開発 ⾏動パターンの設定⽅法と注意点 報酬関数の設計 実装パターンの例 実装する際のポイント 実践してわかったこと
41 DeepRacer 楽しい︕
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}