20年で60万⼈ ⾏政の居住誘導も 広域避難の体制必要.⽇本経済新聞. 2023- 08-24, ⽇経電⼦版, https://www.nikkei.com/article/DGXZQOUE221DL0S3A520C2000000/, 参照2023-11-19 • 朝倉康夫. 利⽤者均衡を制約とする交通ネットワーク の最適計画モデル. ⼟⽊計画学研究・論⽂集, 6:1–19, 1988. • Cai, Z., Mo, D., Tang, W., Chen, Y., & Chen, X. (. (2023). A two-period game-theoretical model for heterogeneous ride-sourcing platforms with asymmetric competition and mixed fleets. Transportation Research Part E: Logistics and Transportation Review, 178, 103279. https://doi.org/10.1016/j.tre.2023.103279 • Li, D., Islam, D. M. Z., Robinson, M., Song, D., Dong, J., & Reimann, M. (2023). Network revenue management game in the railway industry: Stackelberg equilibrium, global optimality, and mechanism design. European Journal of Operational Research, 312(1), 240-254. https://doi.org/10.1016/j.ejor.2023.06.044 • Zheng, Y., Lin, Y., Zhao, L., Wu, T., Jin, D., & Li, Y. (2023). Spatial planning of urban communities via deep reinforcement learning. Nature Computational Science, 1-15. • Qian, K., Mao, L., Liang, X., Ding, Y., Gao, J., Wei, X., ... & Li, J. (2023). AI Agent as Urban Planner: Steering Stakeholder Dynamics in Urban Planning via Consensus-based Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2310.16772. • Zheng, S., Trott, A., Srinivasa, S., Parkes, D. C., & Socher, R. (2022). The AI Economist: Taxation policy design via two-level deep multiagent reinforcement learning. Science Advances. https://doi.org/abk2607 • Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., & Hassabis, D. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science. https://doi.org/aar6404 16 参考⽂献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
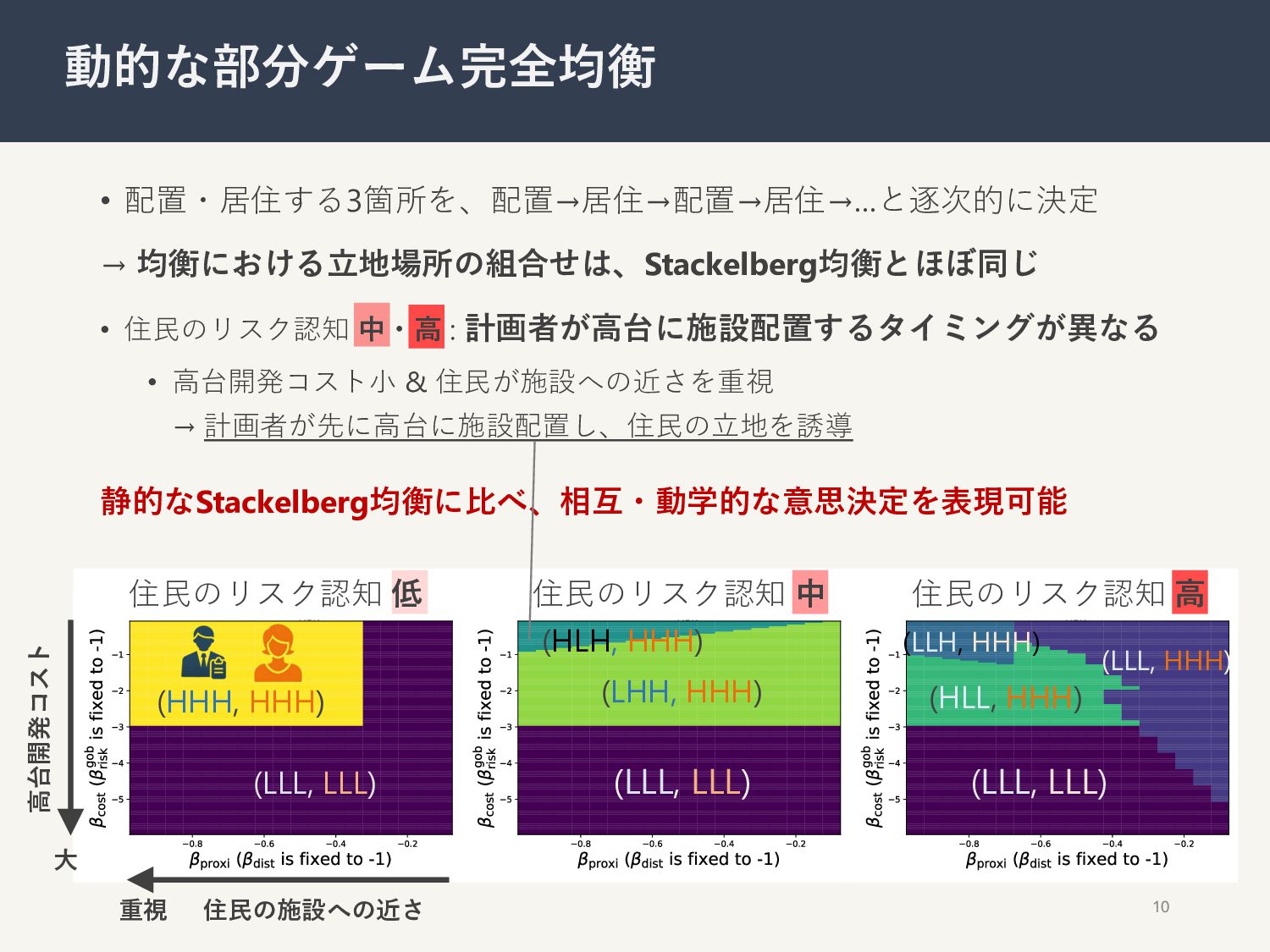{kind=link}
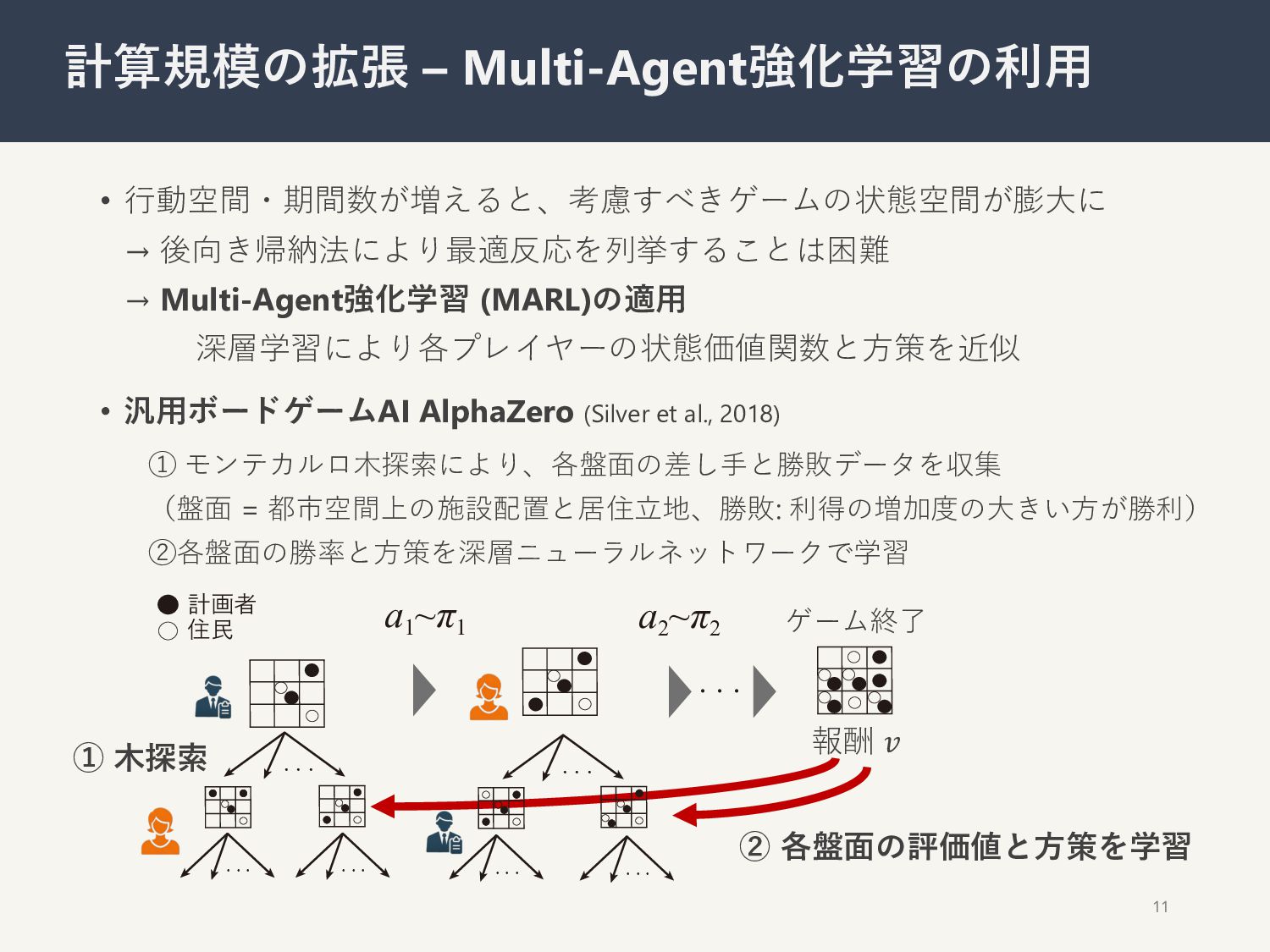{kind=link}
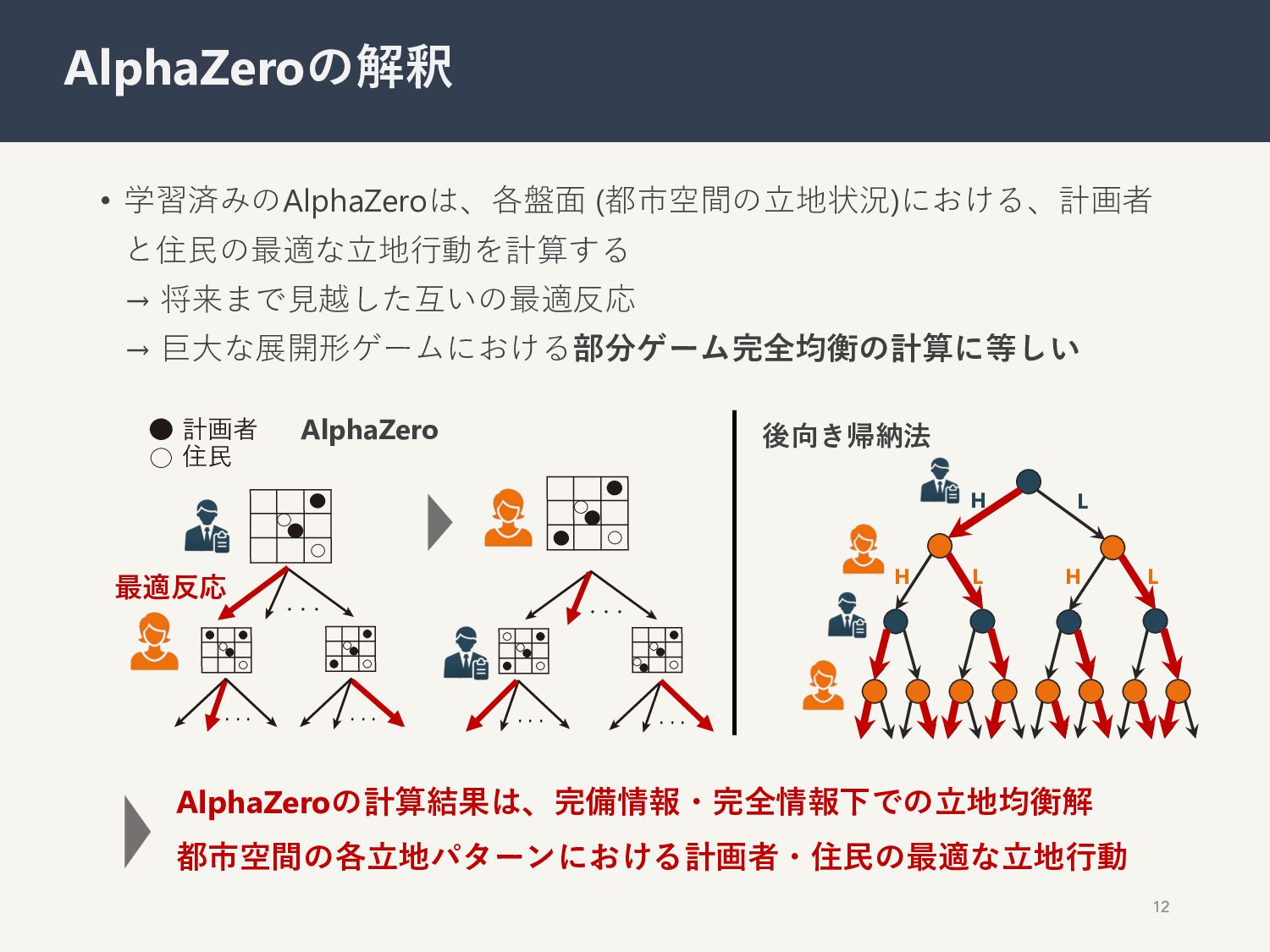{kind=link}
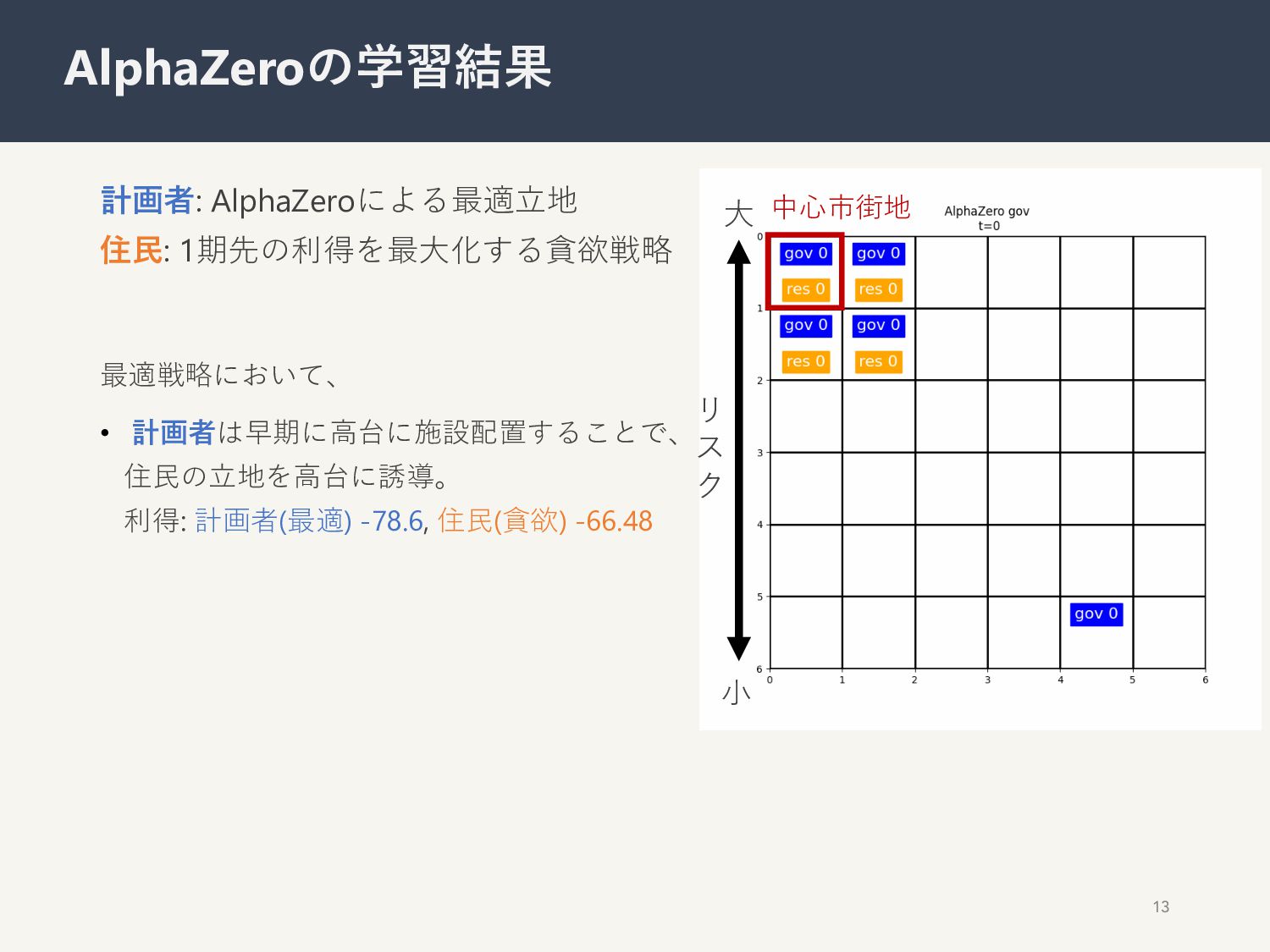{kind=link}
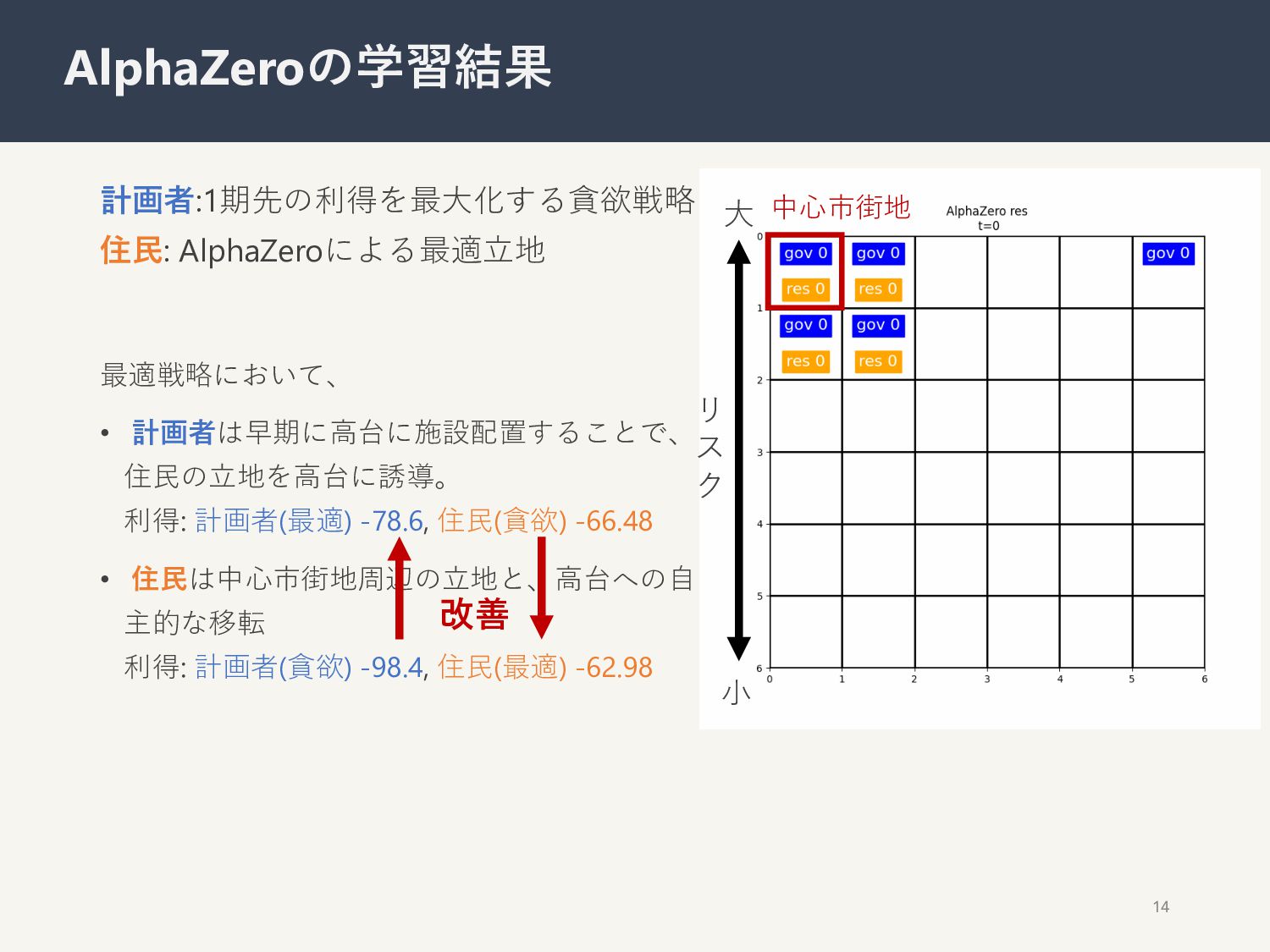{kind=link}
{kind=link}
{kind=link}
{kind=link}
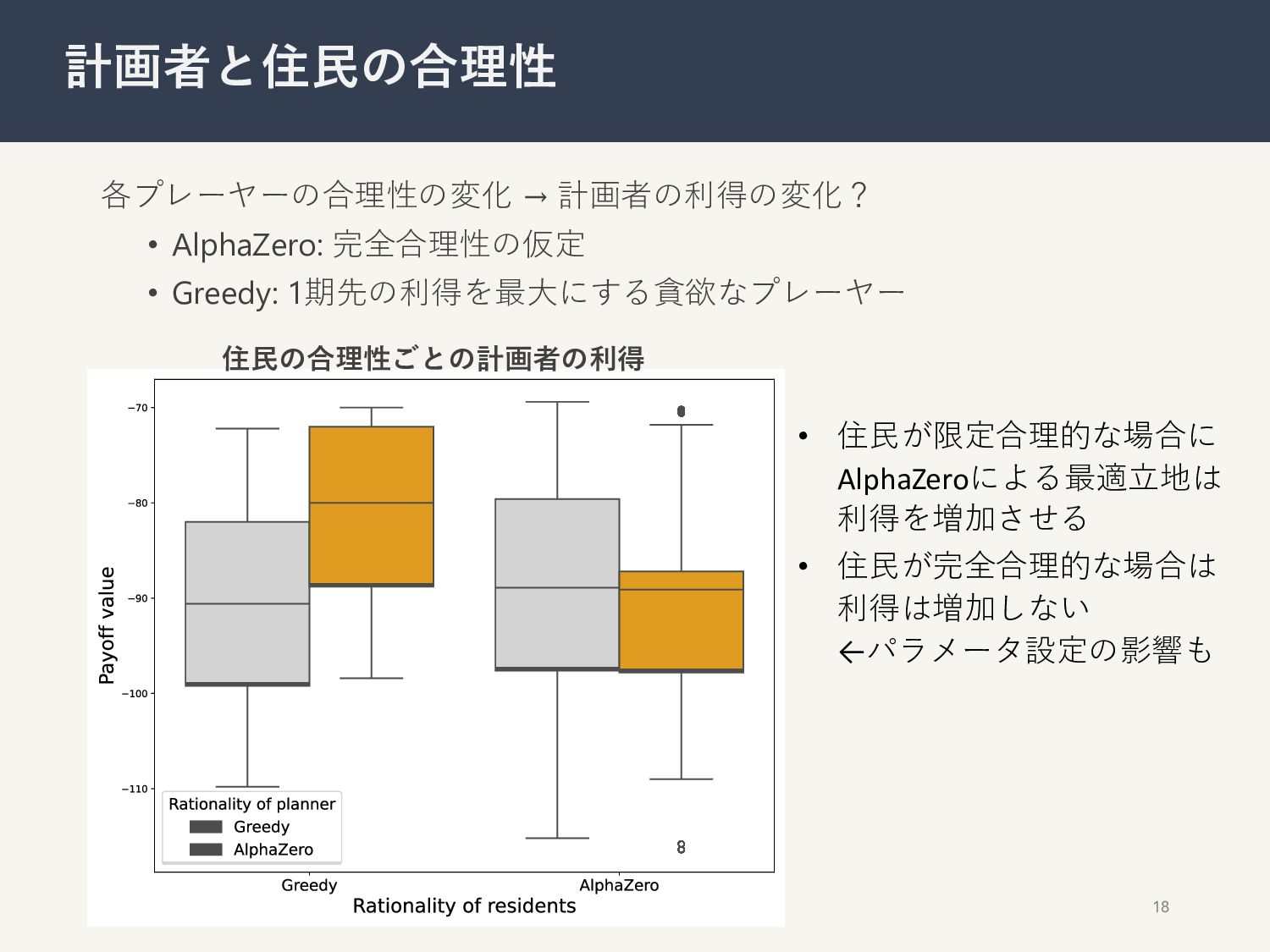{kind=link}
{kind=link}
{kind=link}
{kind=link}
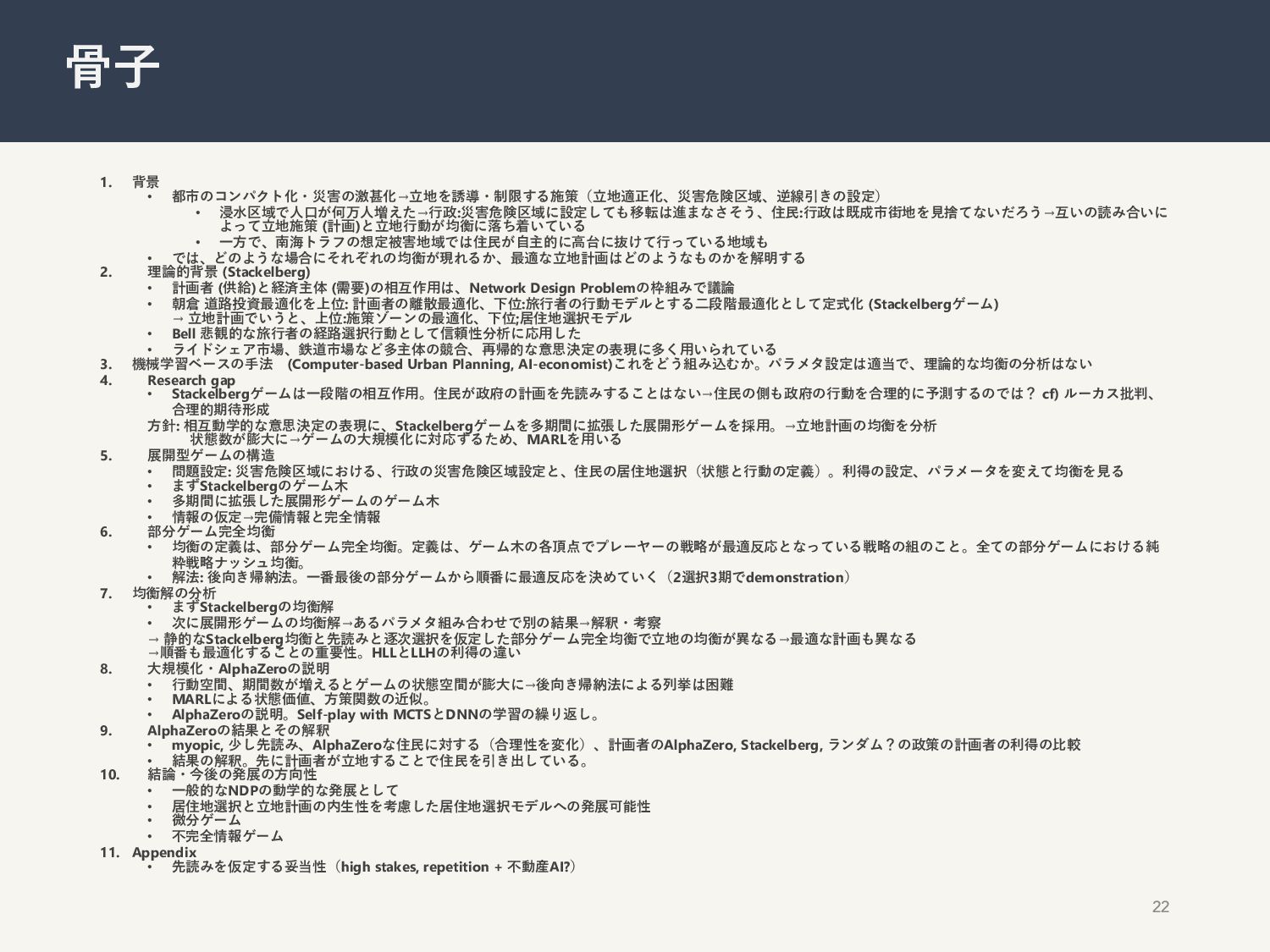{kind=link}