「ウェブ・ソーシャルメディア論文読み会」第五回の発表資料です
https://sites.google.com/view/web-socialmedia-study/home
論文: Discovering and Categorising Language Biases in Reddit (ICWSM2021) by Ferrer, X., van Nuenen, T., Such, J. M., & Criado, N.
https://ojs.aaai.org/index.php/ICWSM/article/view/18048
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
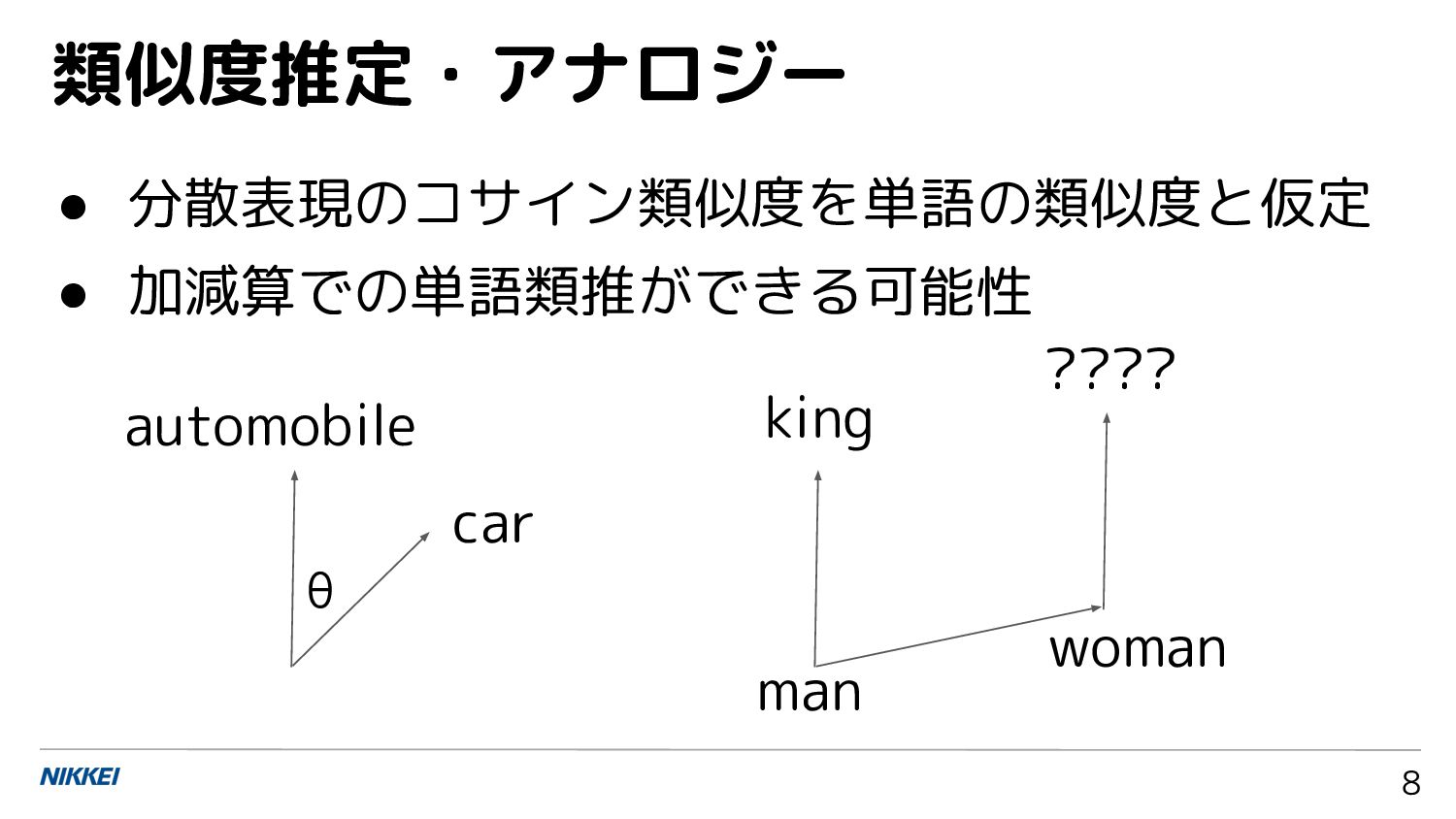{kind=link}
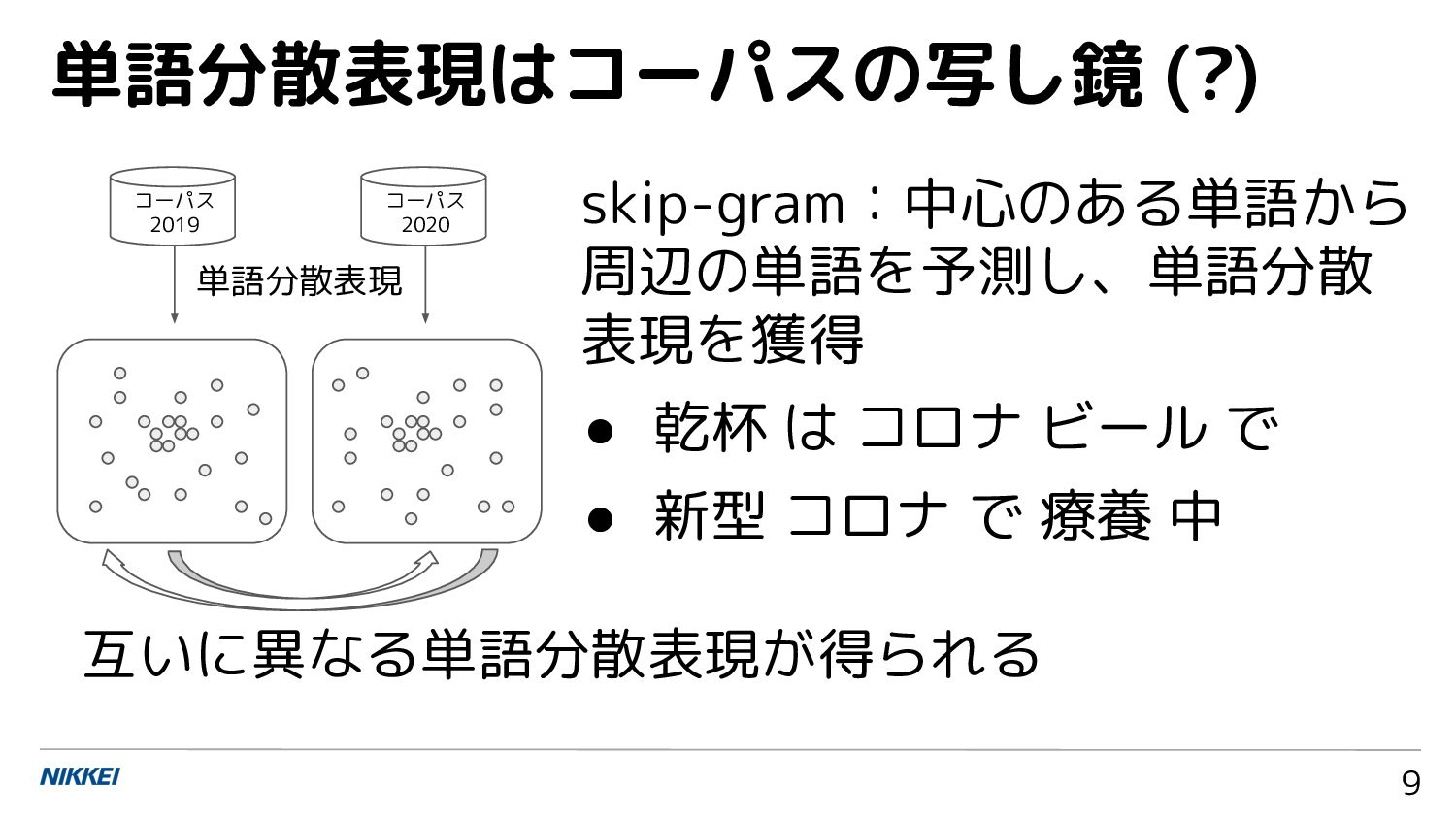{kind=link}
{kind=link}
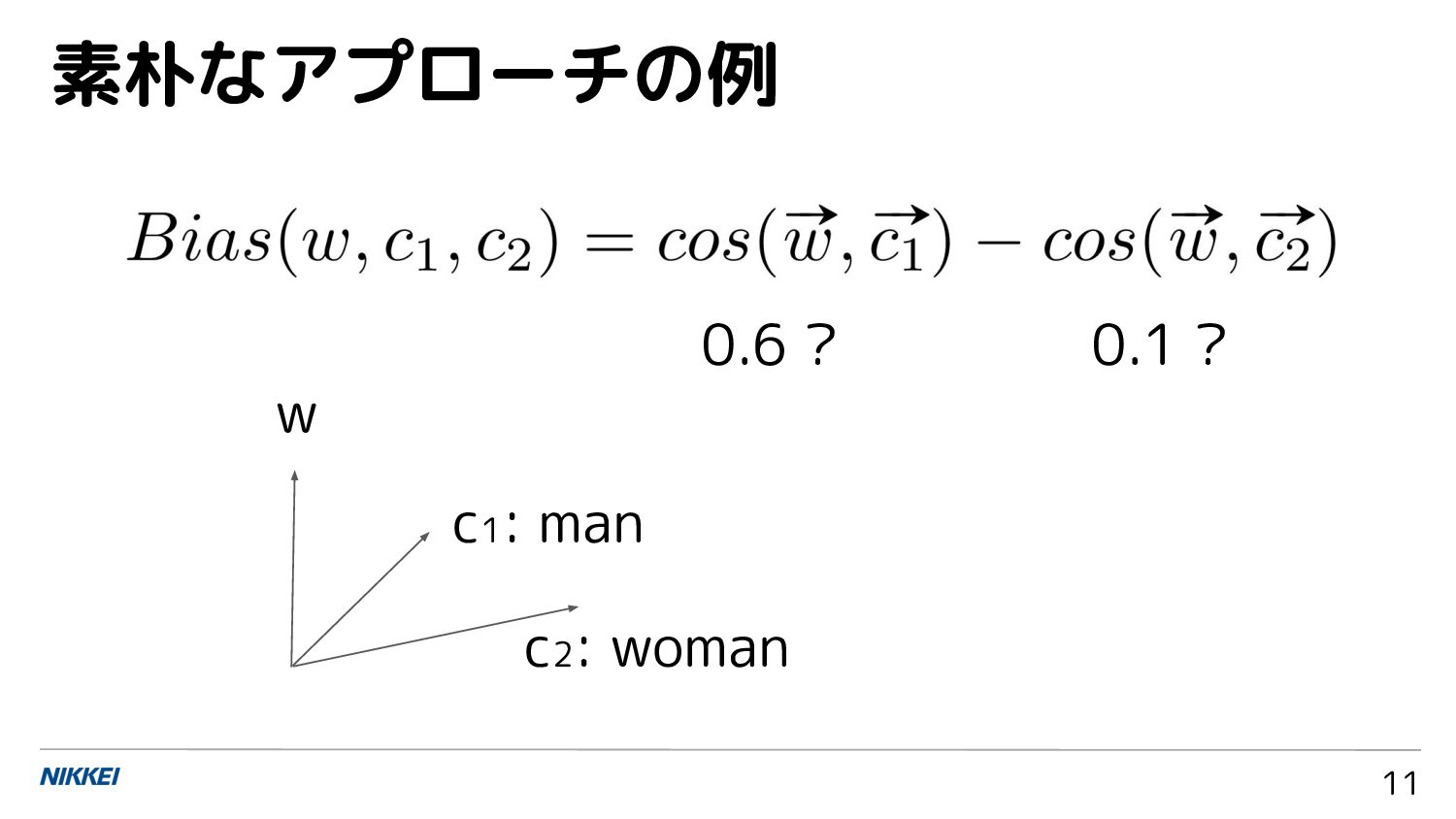{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
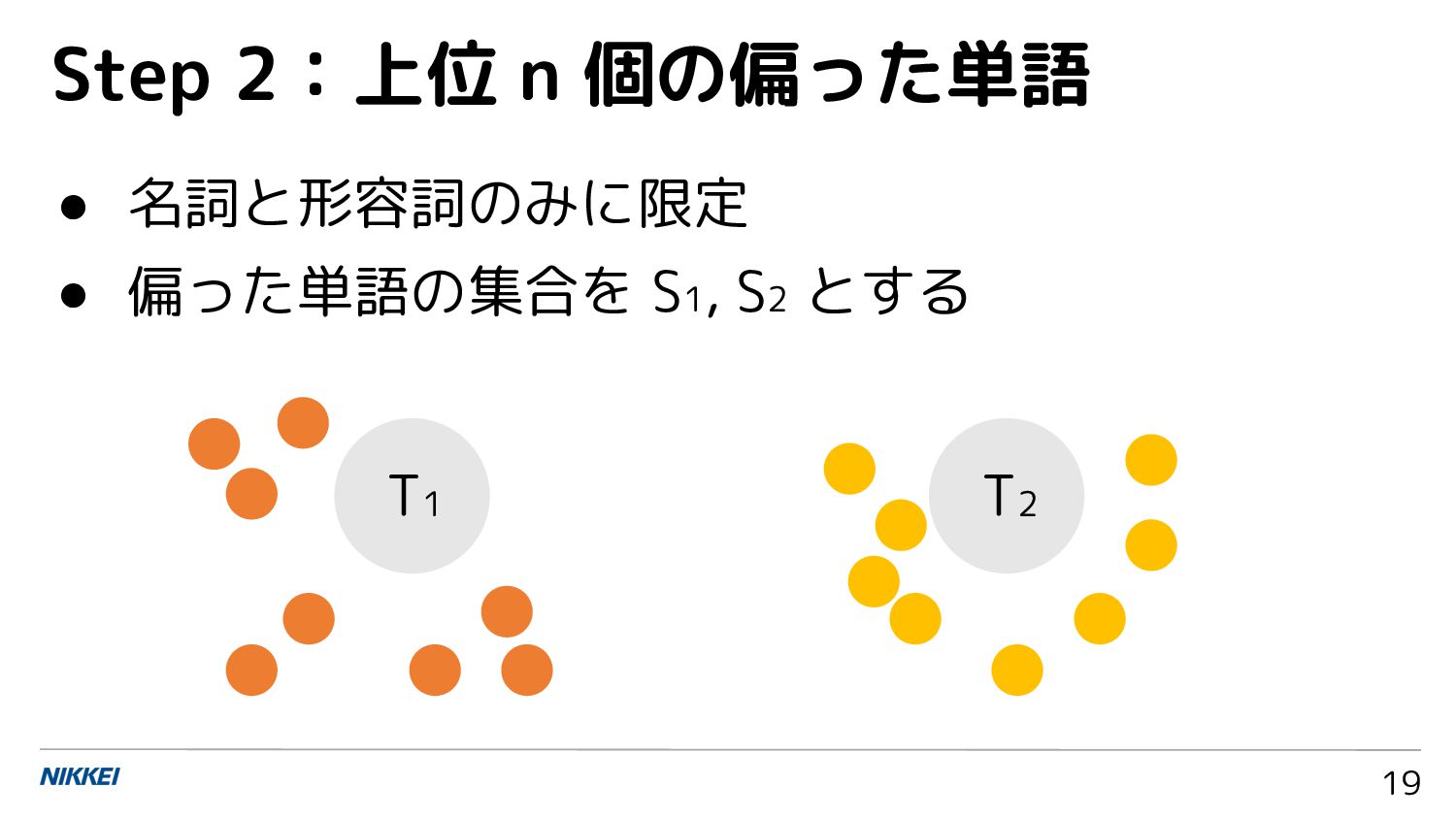{kind=link}
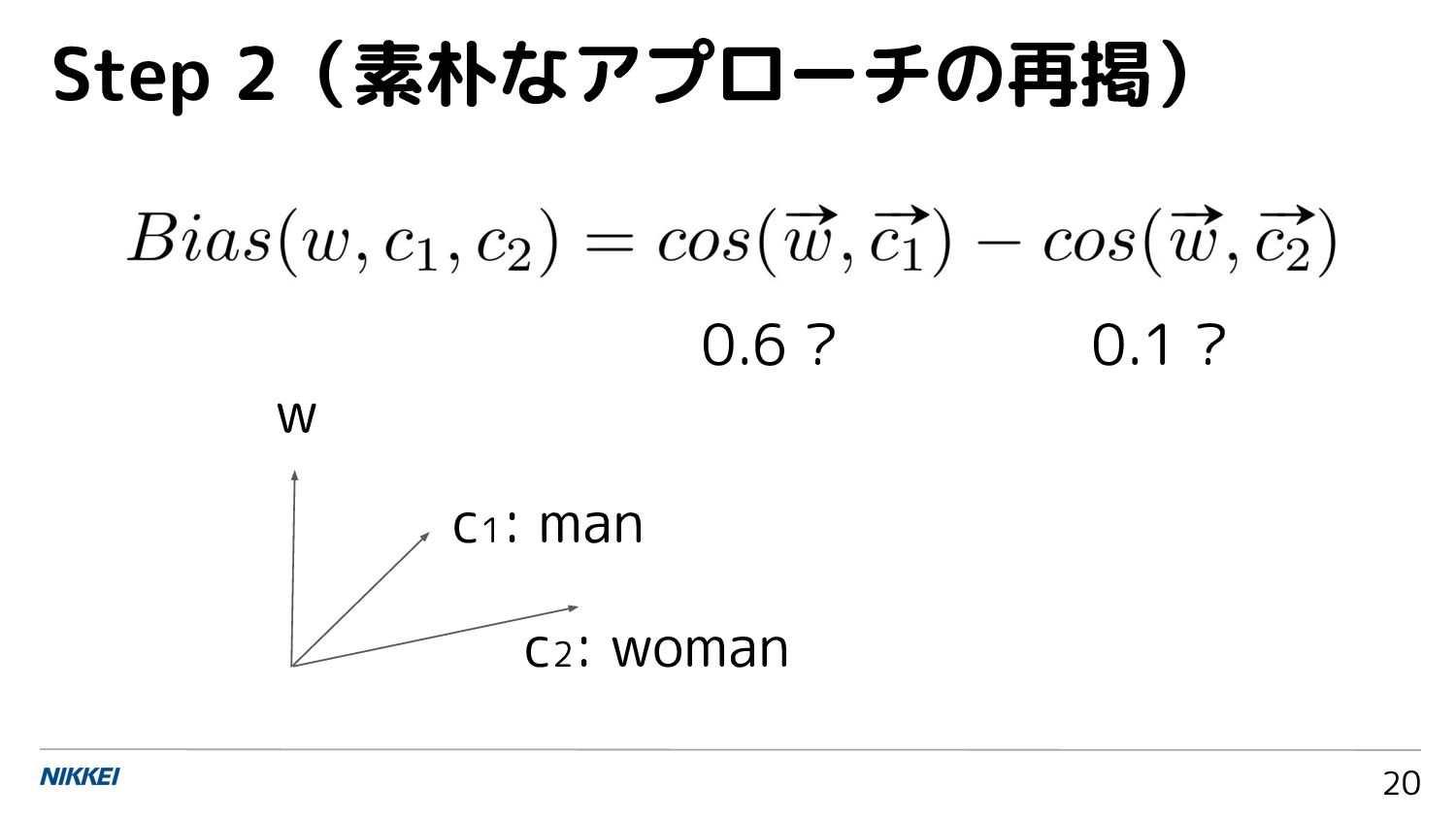{kind=link}
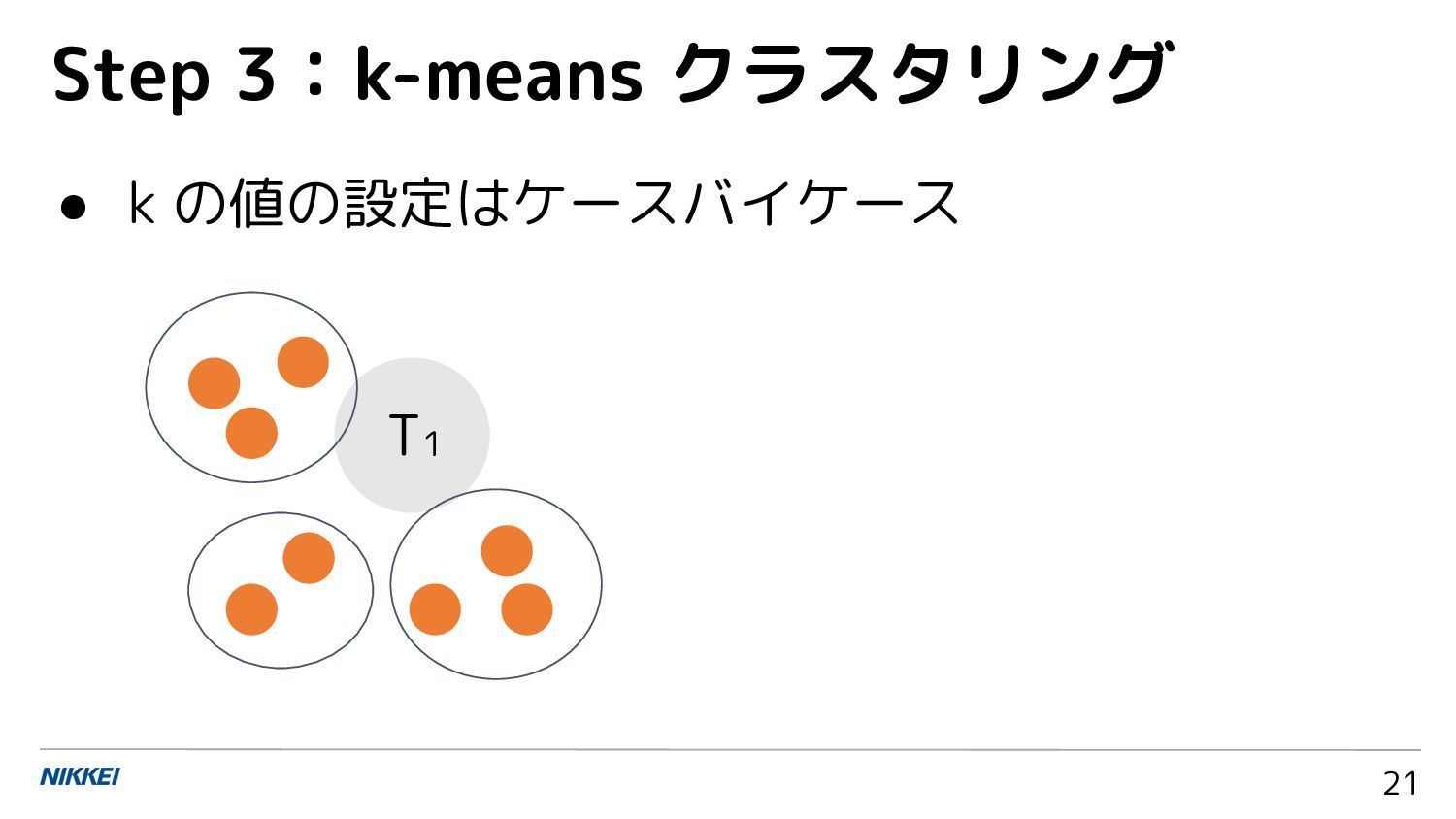{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
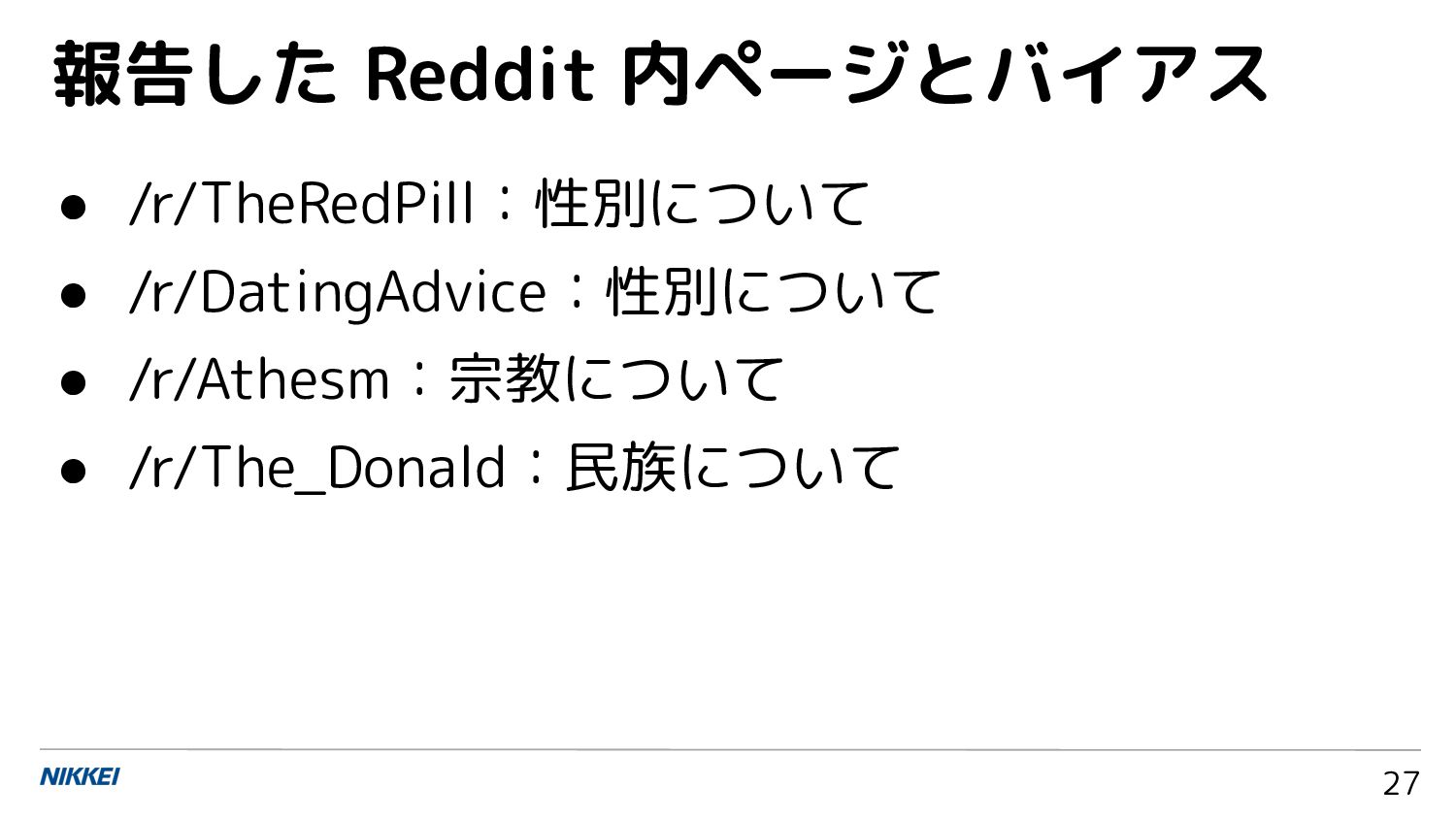{kind=link}
{kind=link}
{kind=link}
{kind=link}