A self-contained (& slightly updated) version of our Interspeech tutorial: https://speakerdeck.com/yoshipon/interspeech2023-t5-part4-bando
Demo pages:
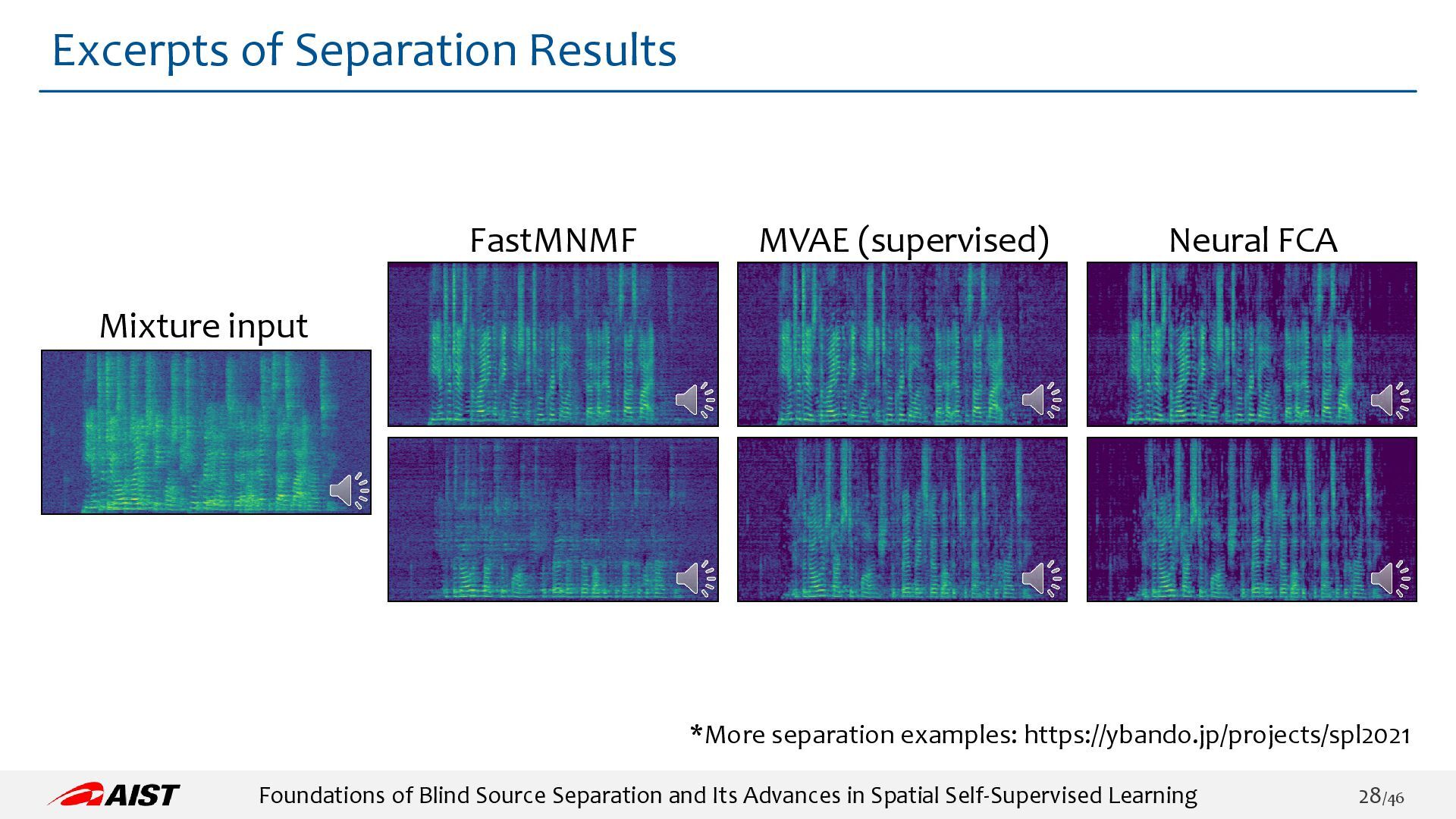
Neural FCA: https://ybando.jp/projects/spl2021/
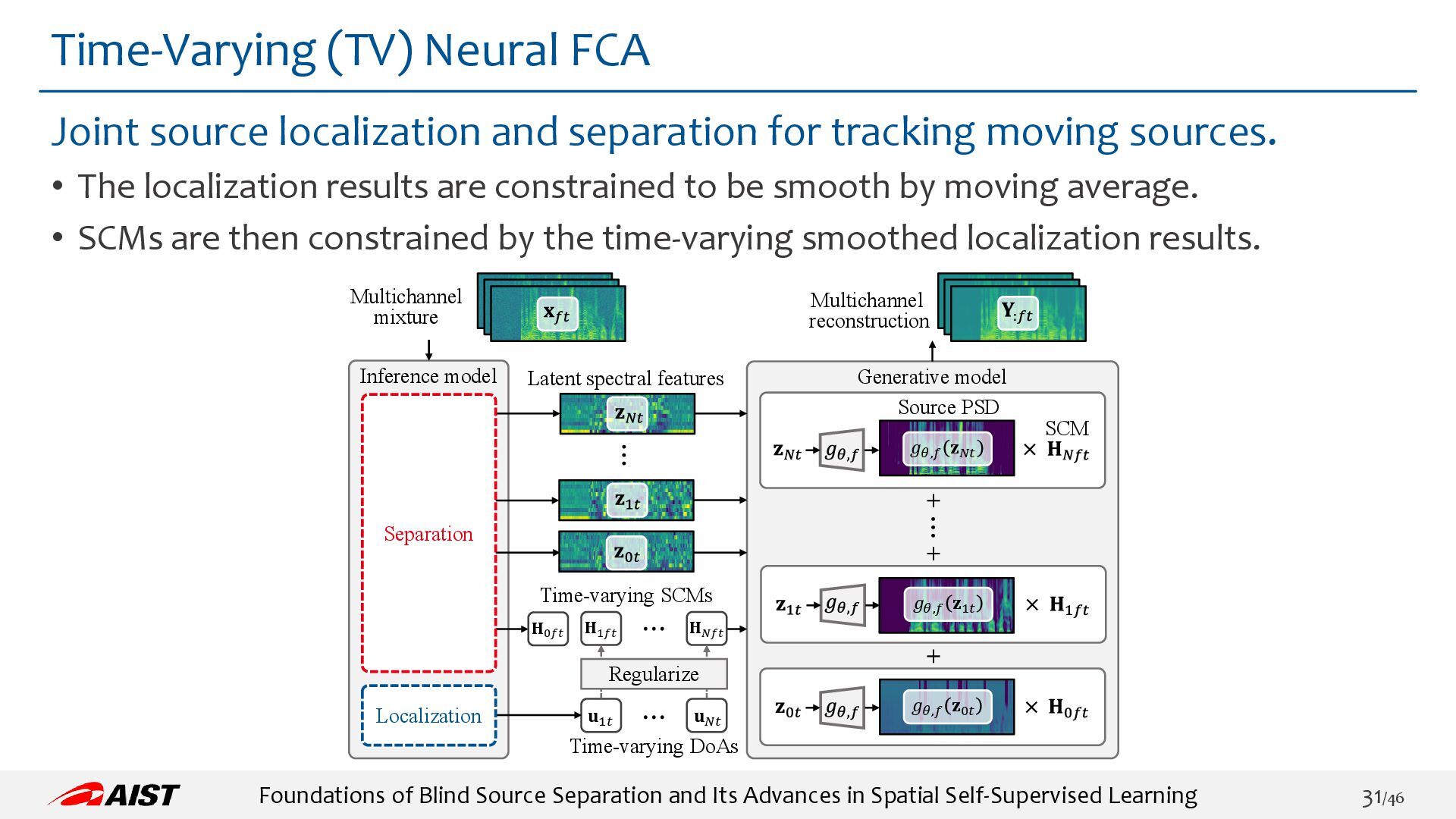
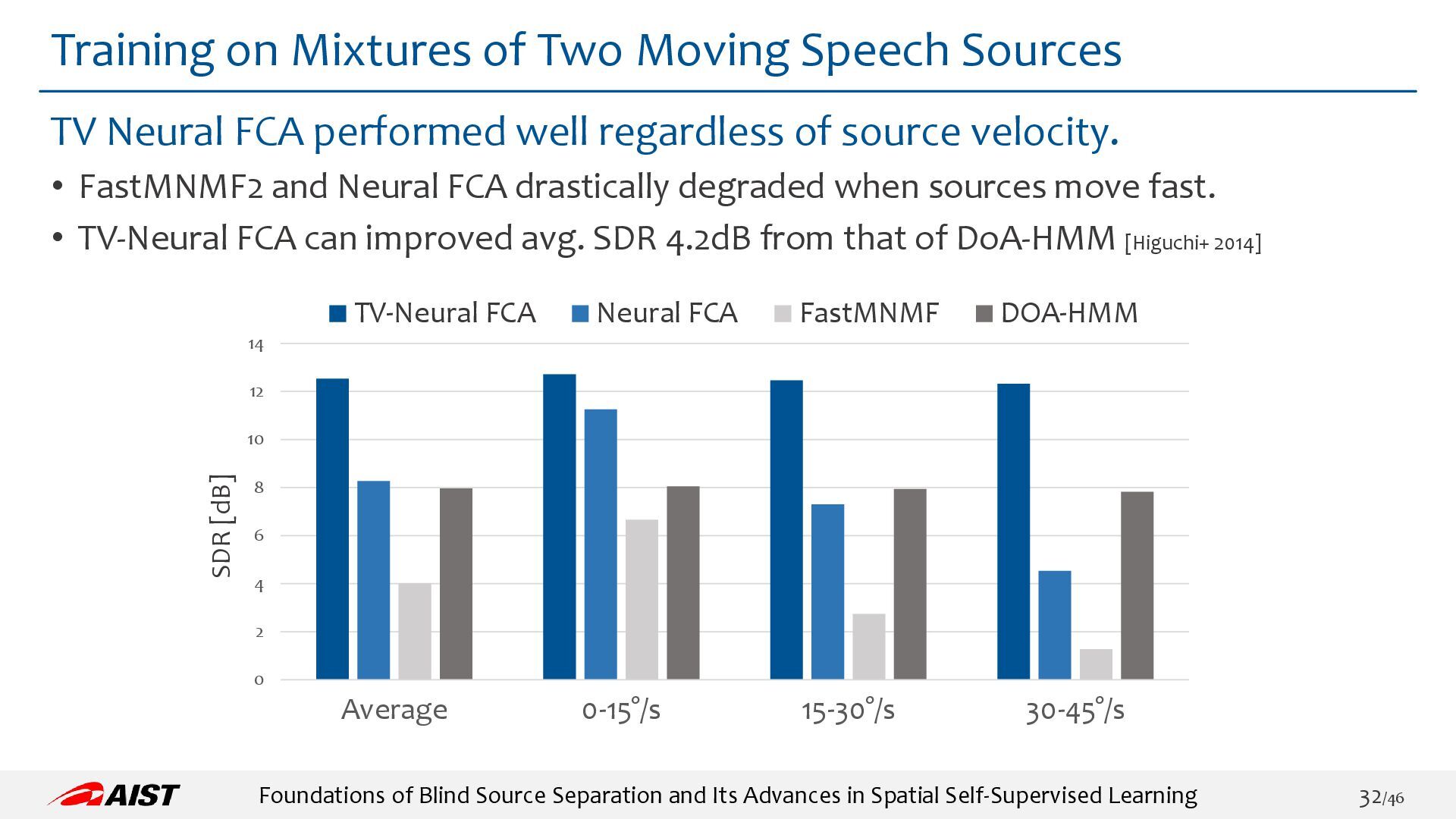
TV-Neural FCA: https://ybando.jp/projects/spl2023/
Neural FCASA: https://ybando.jp/projects/neural-fcasa/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
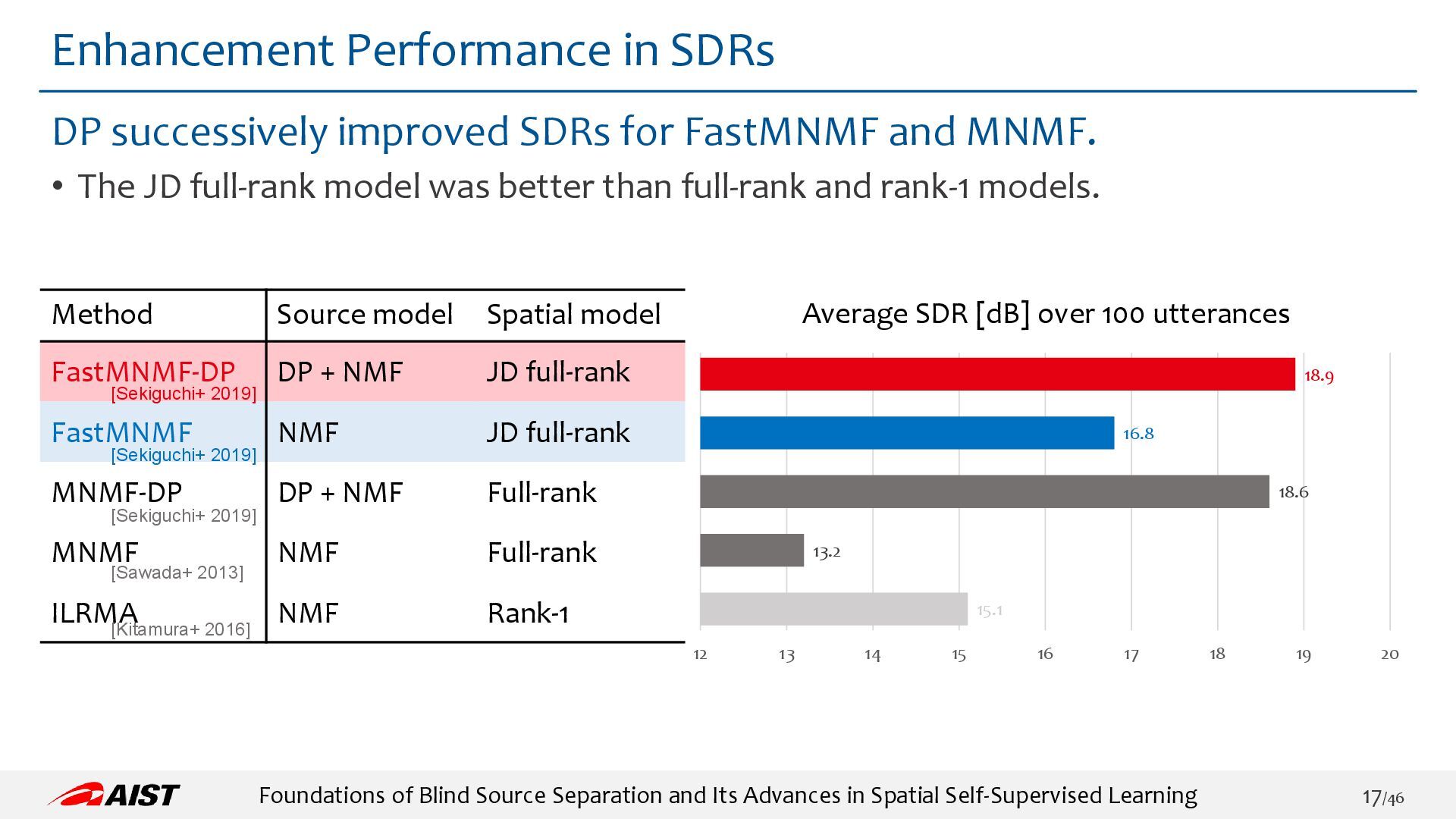{kind=link}
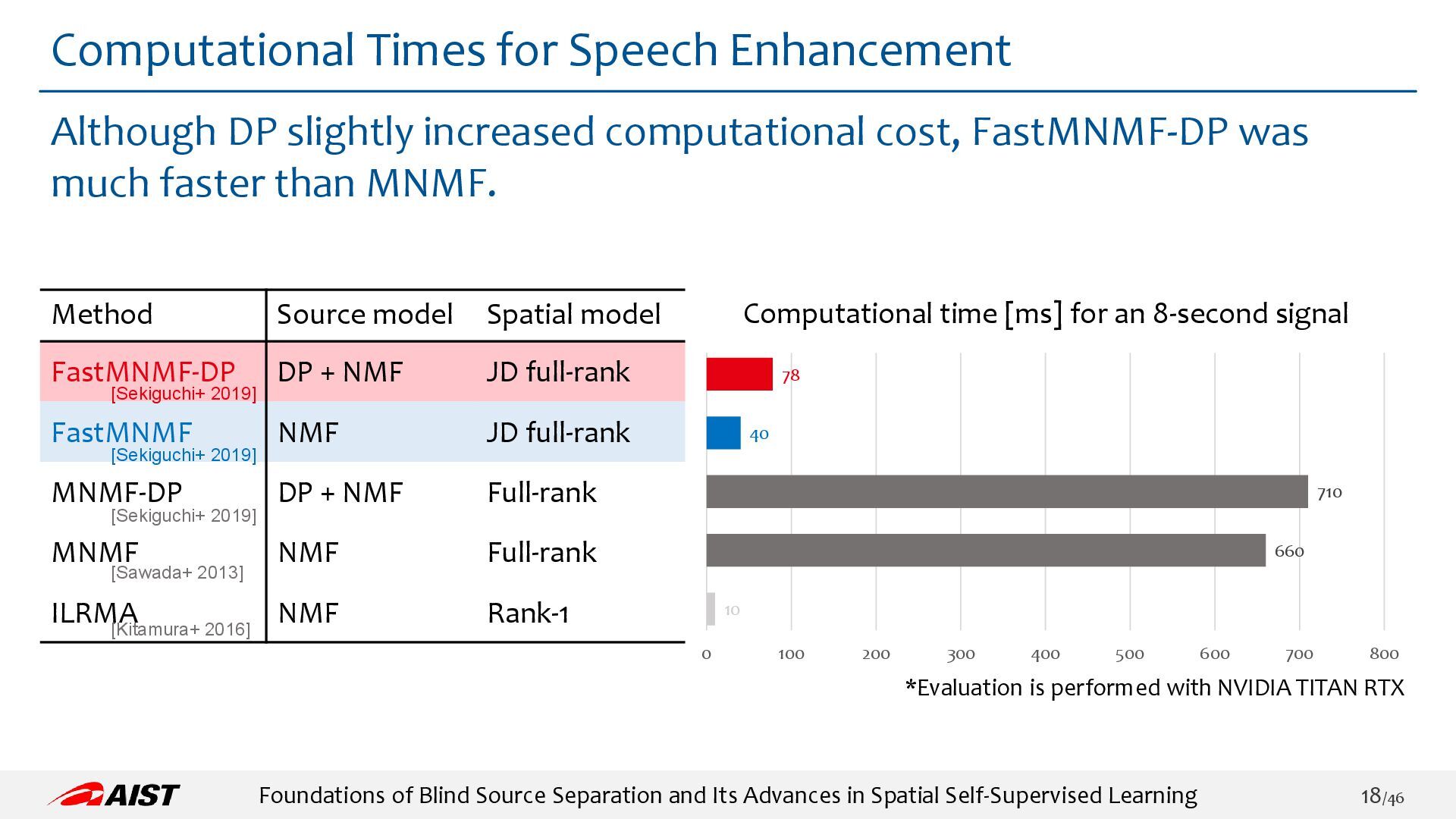{kind=link}
{kind=link}
{kind=link}
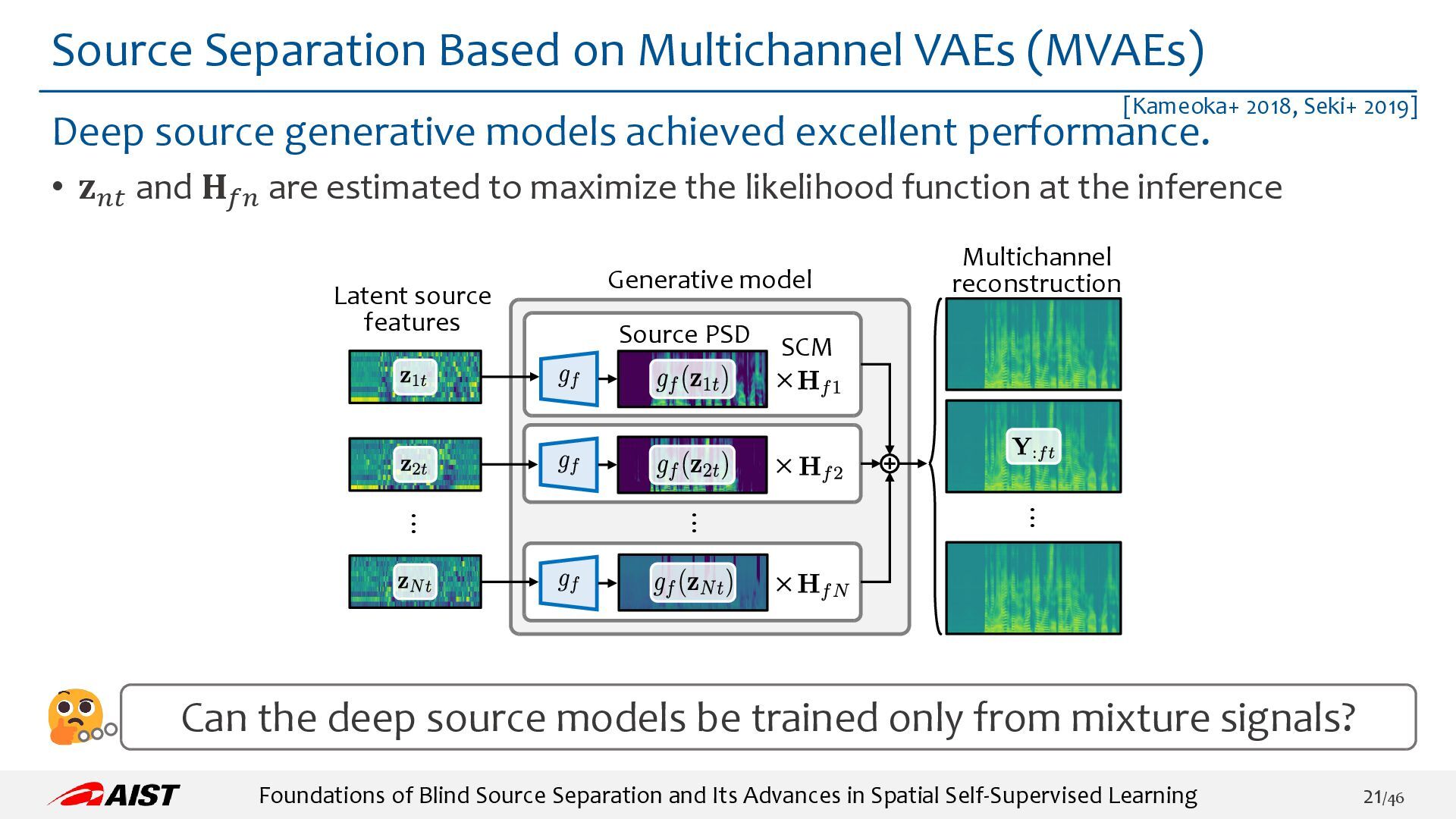{kind=link}
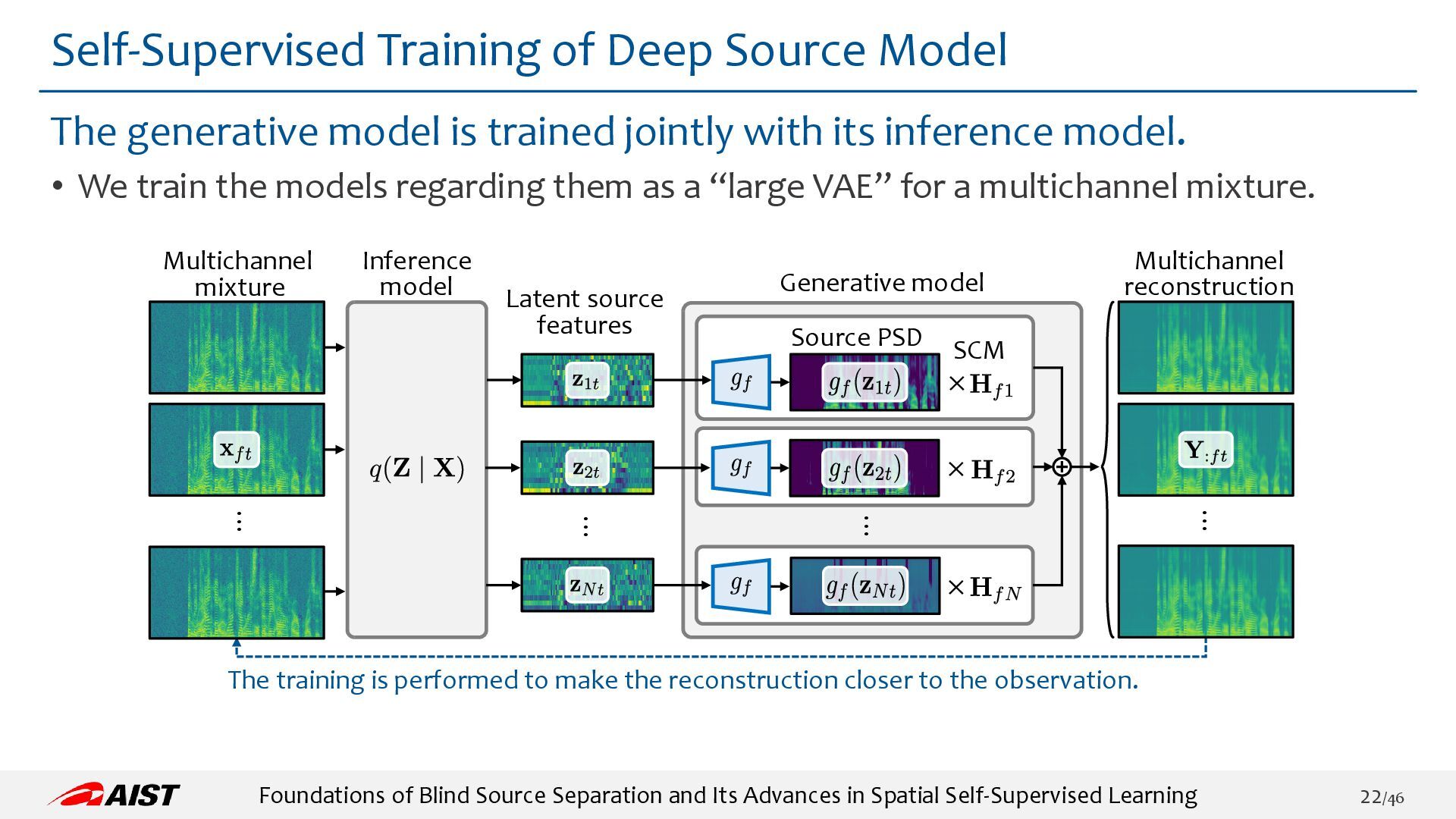{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
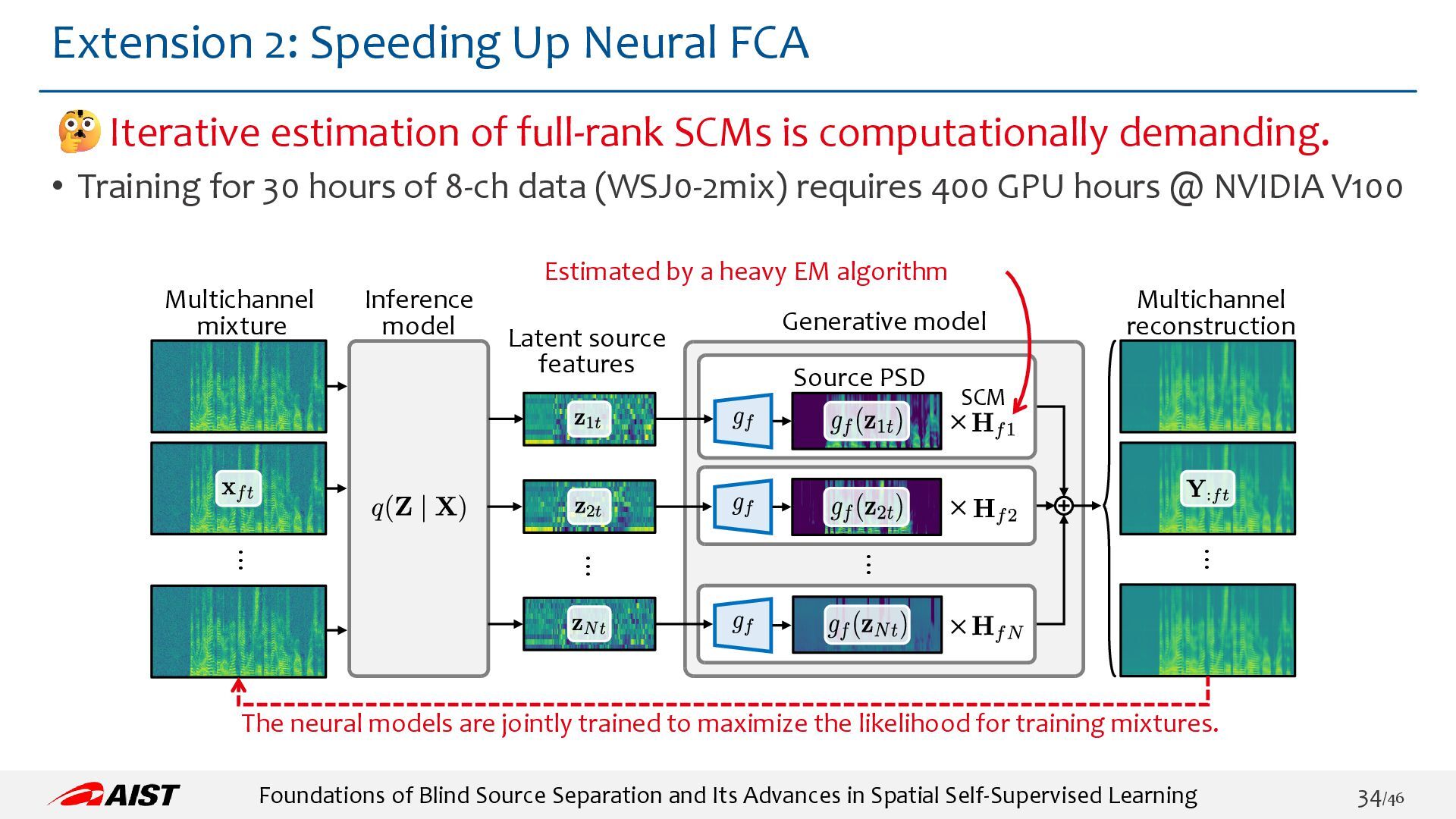{kind=link}
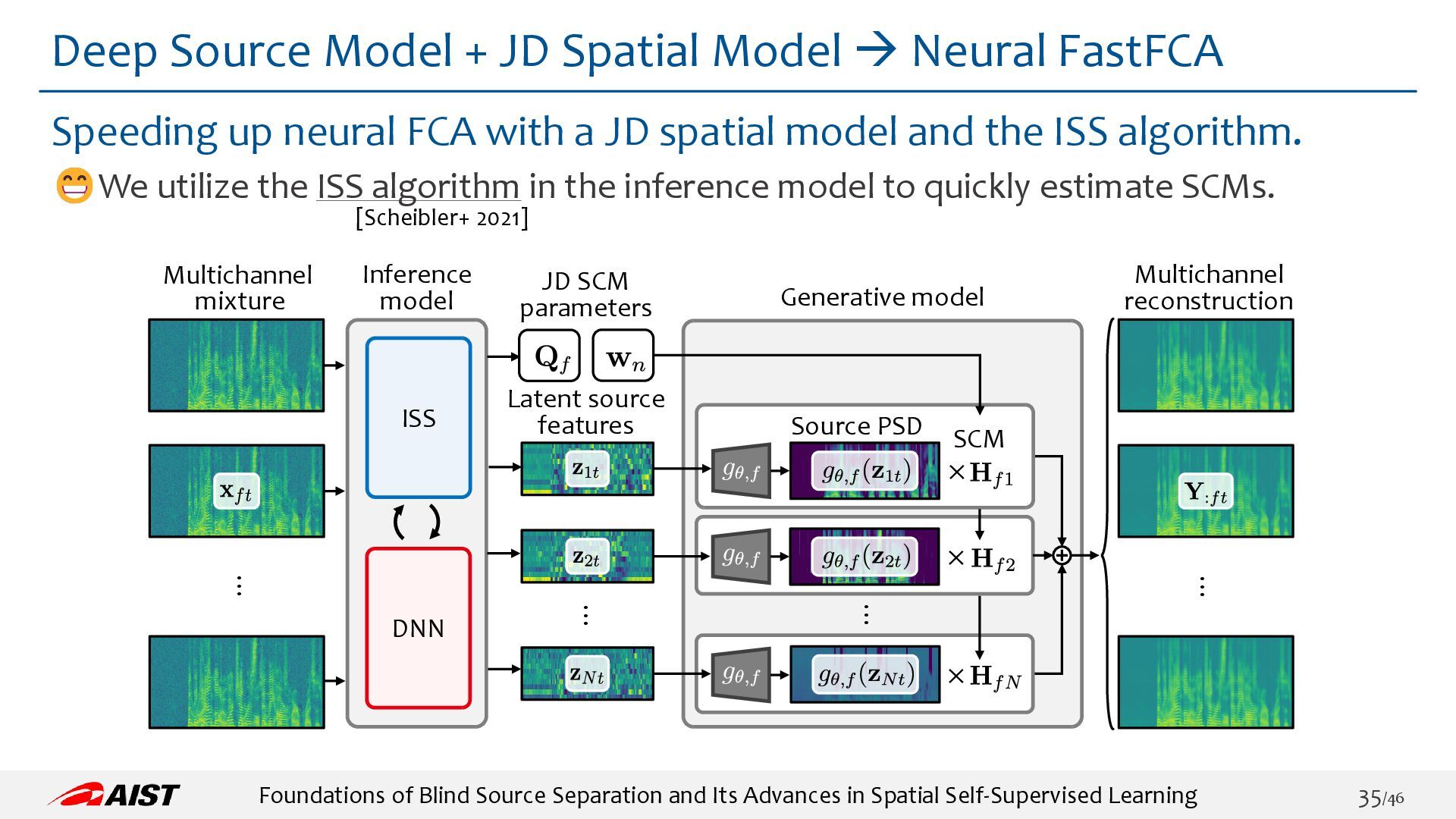{kind=link}
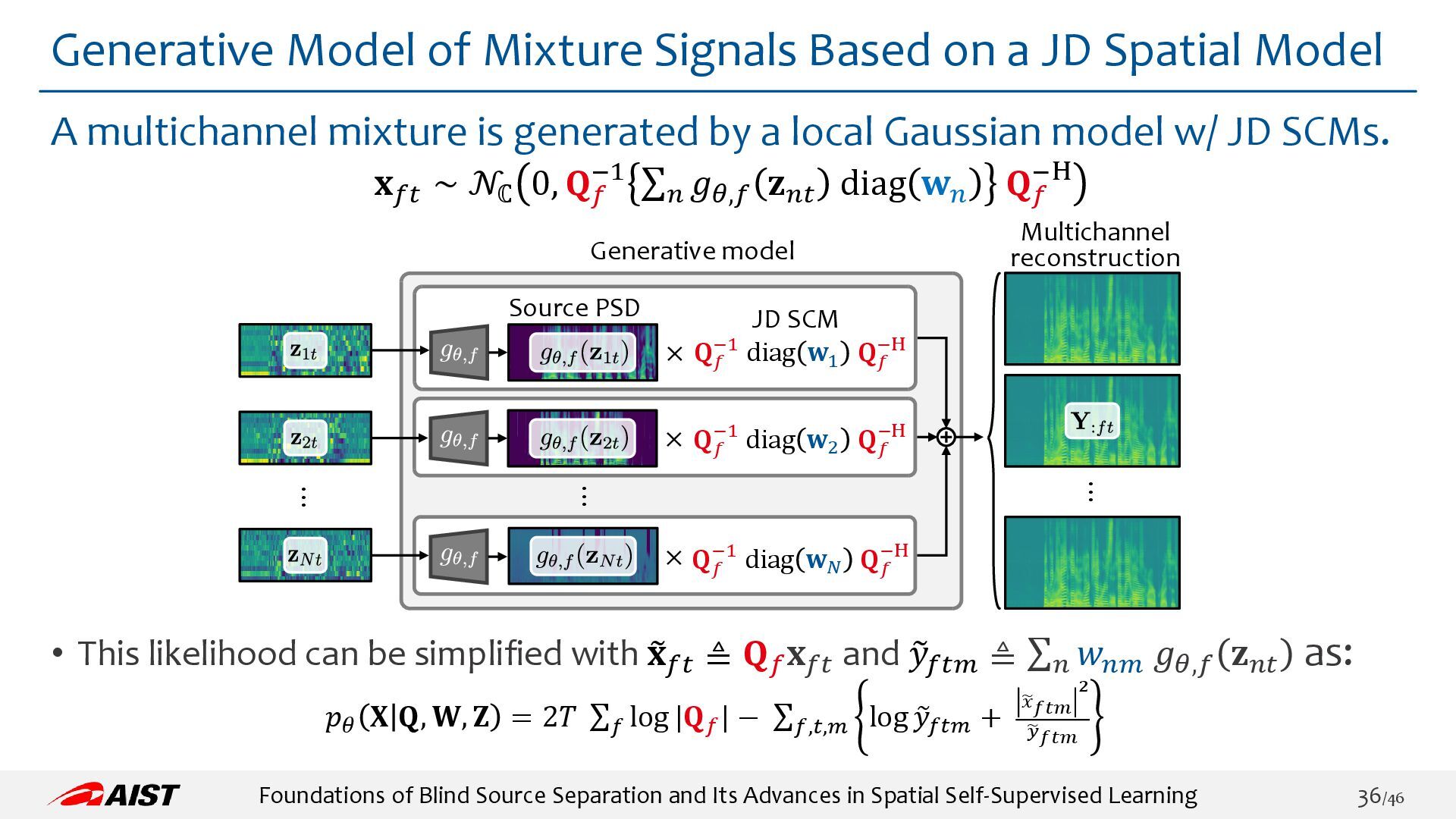{kind=link}
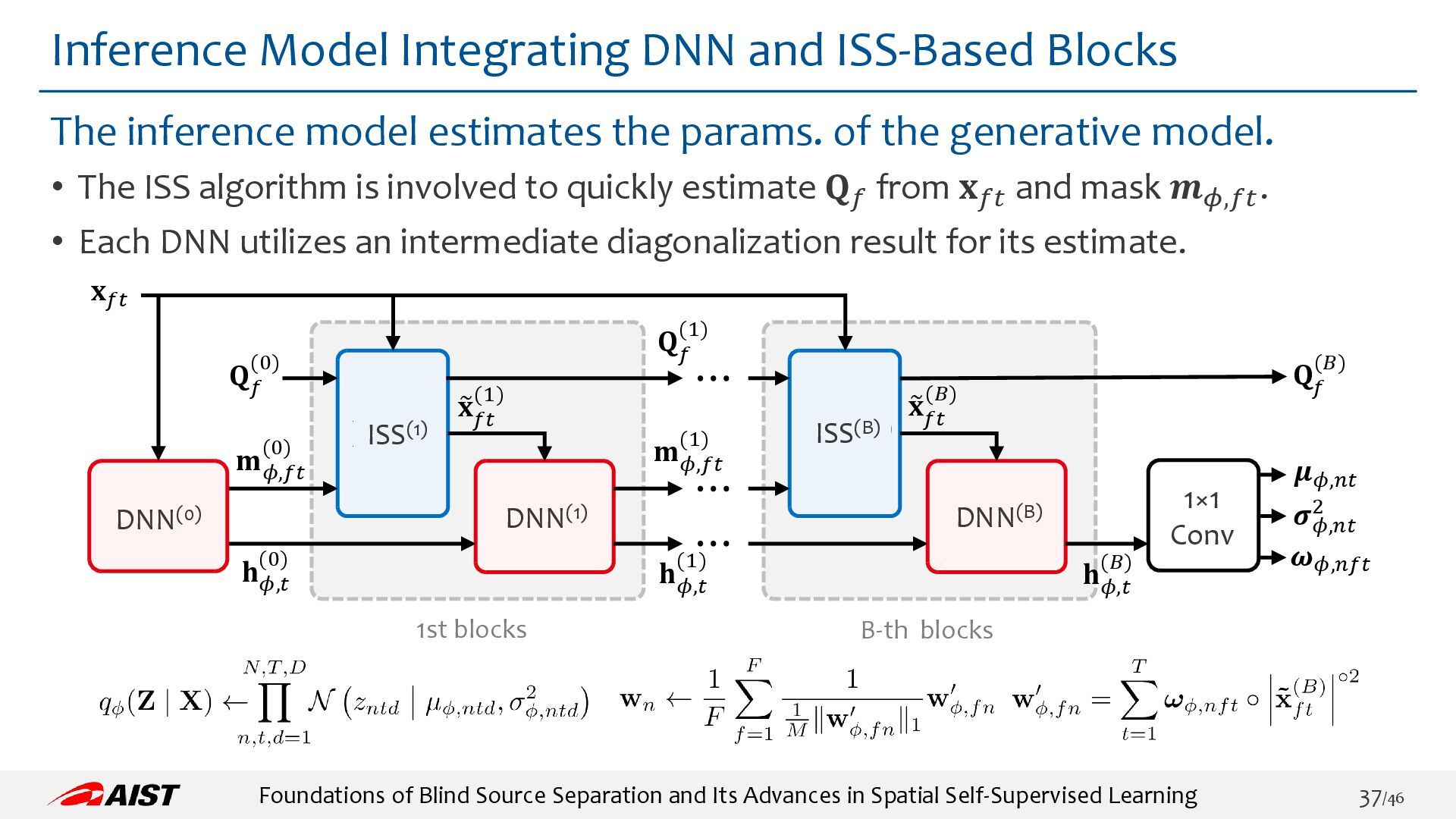{kind=link}
{kind=link}
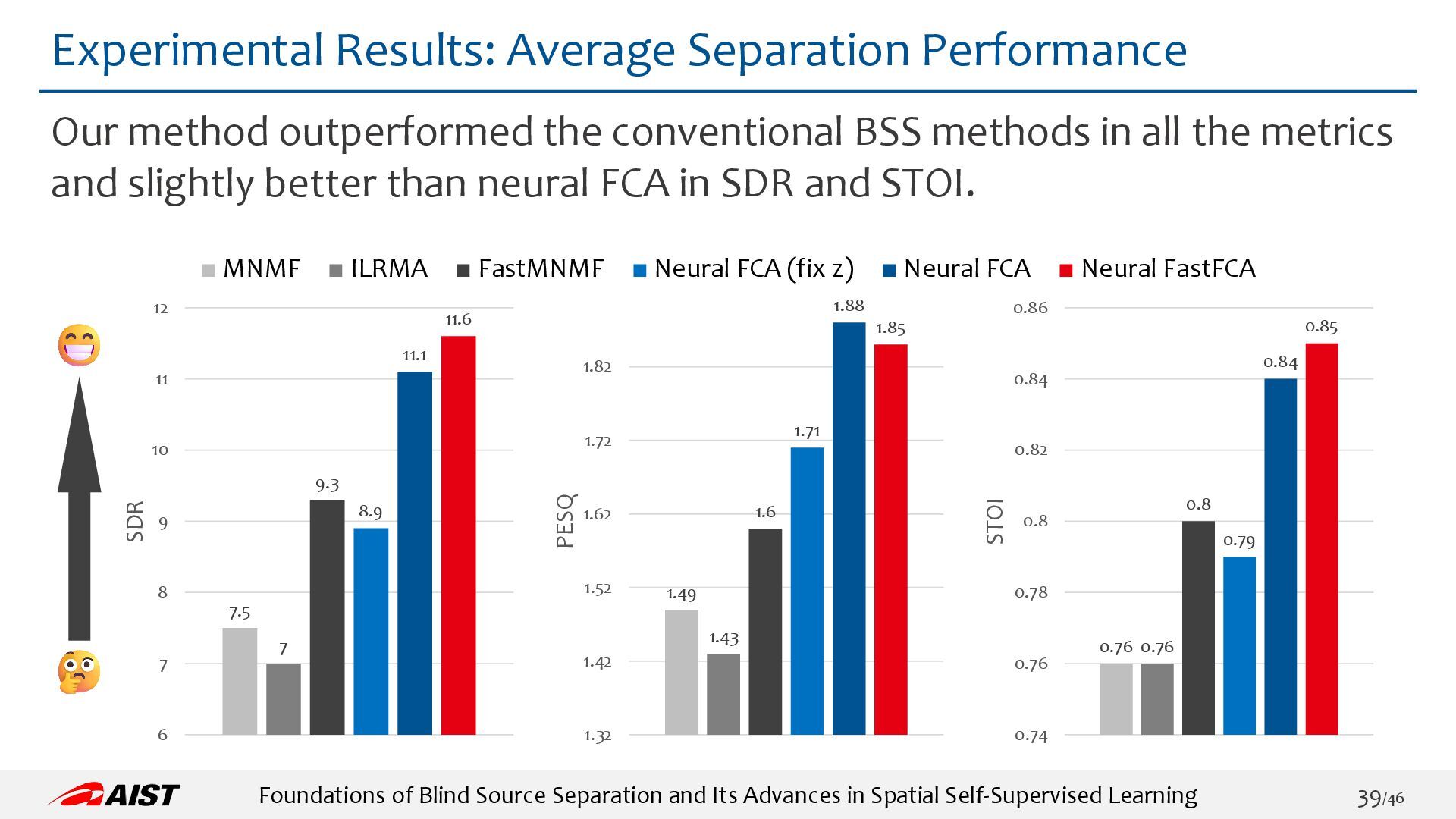{kind=link}
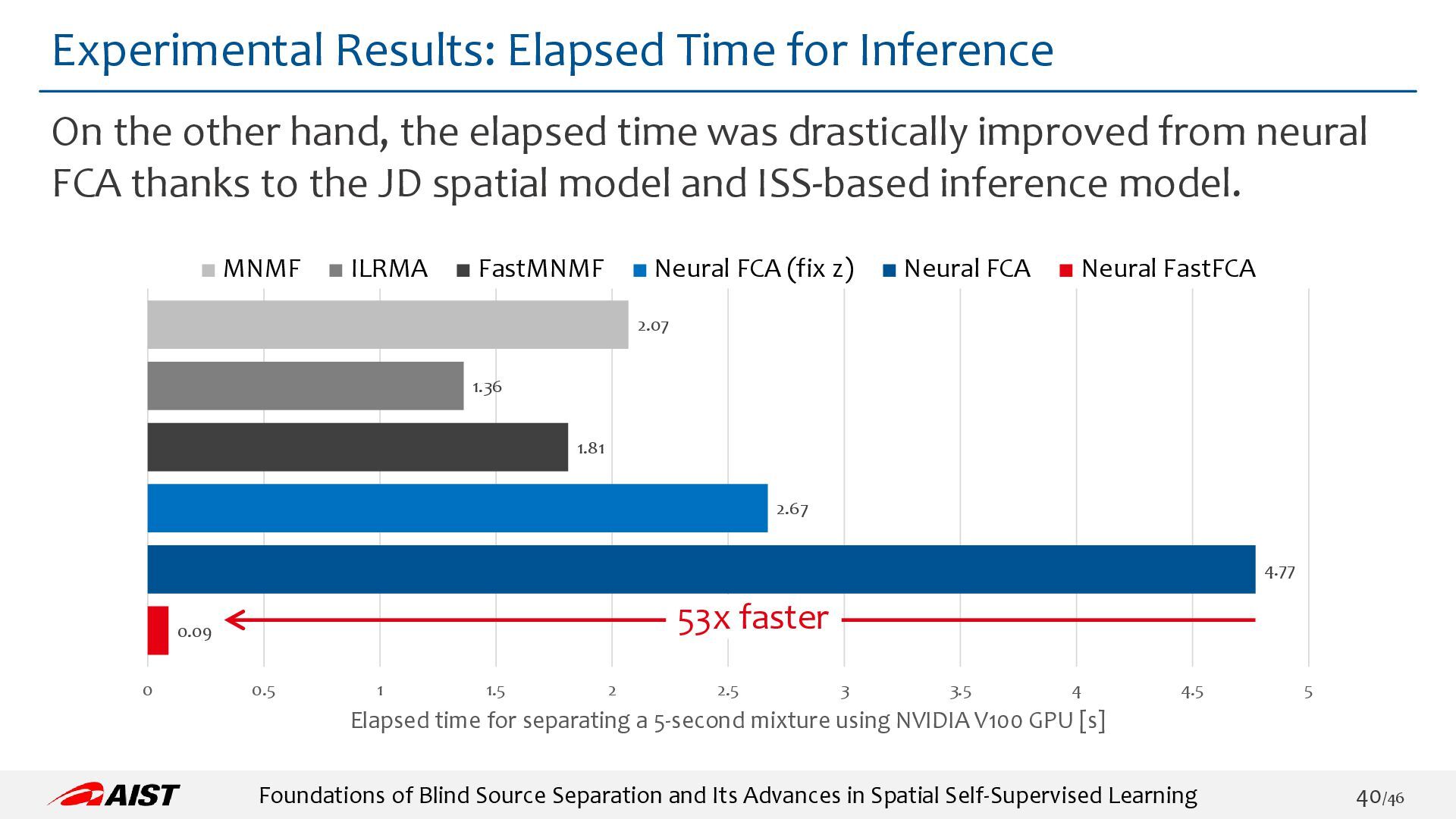{kind=link}
{kind=link}
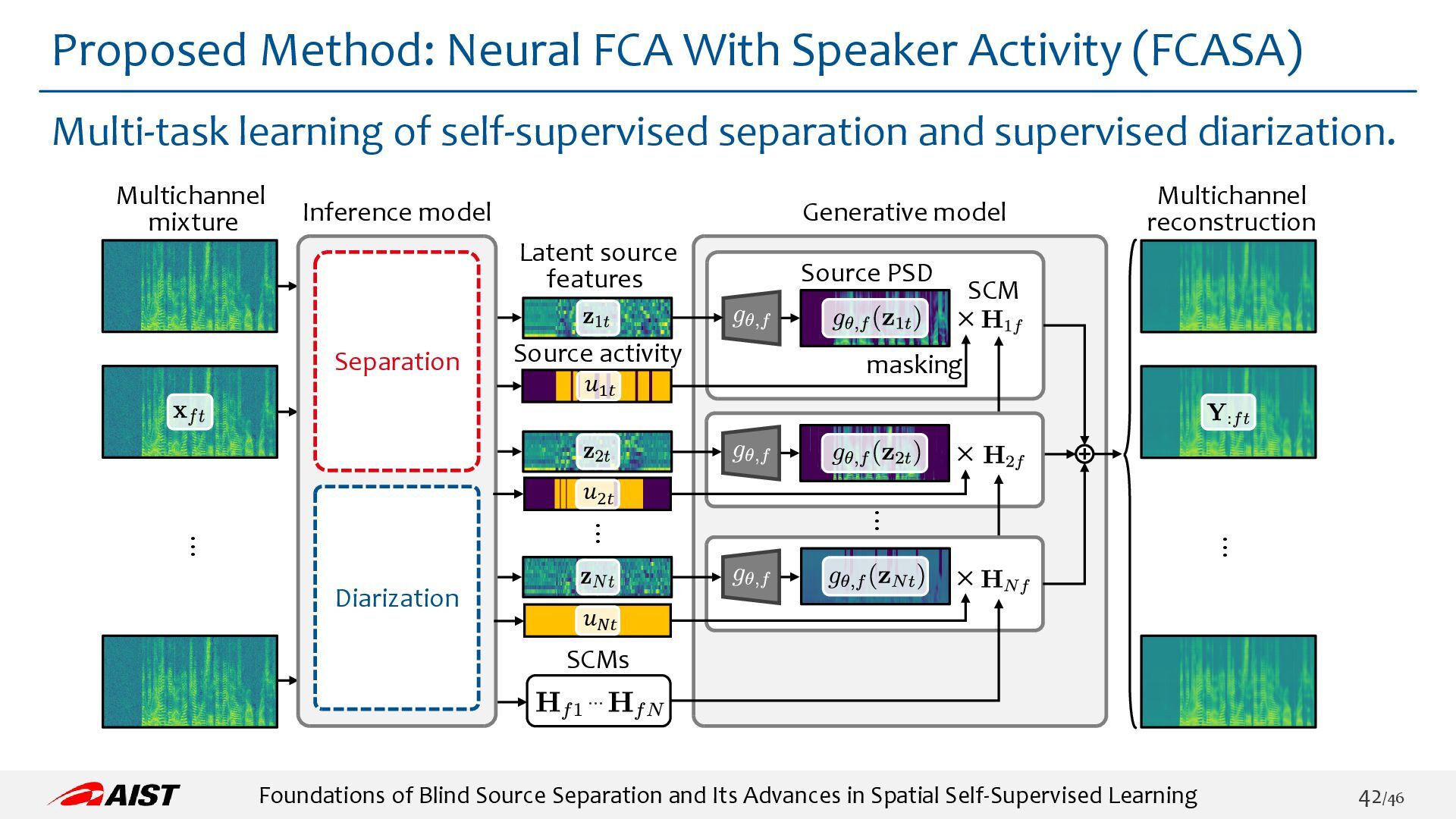{kind=link}
{kind=link}
{kind=link}
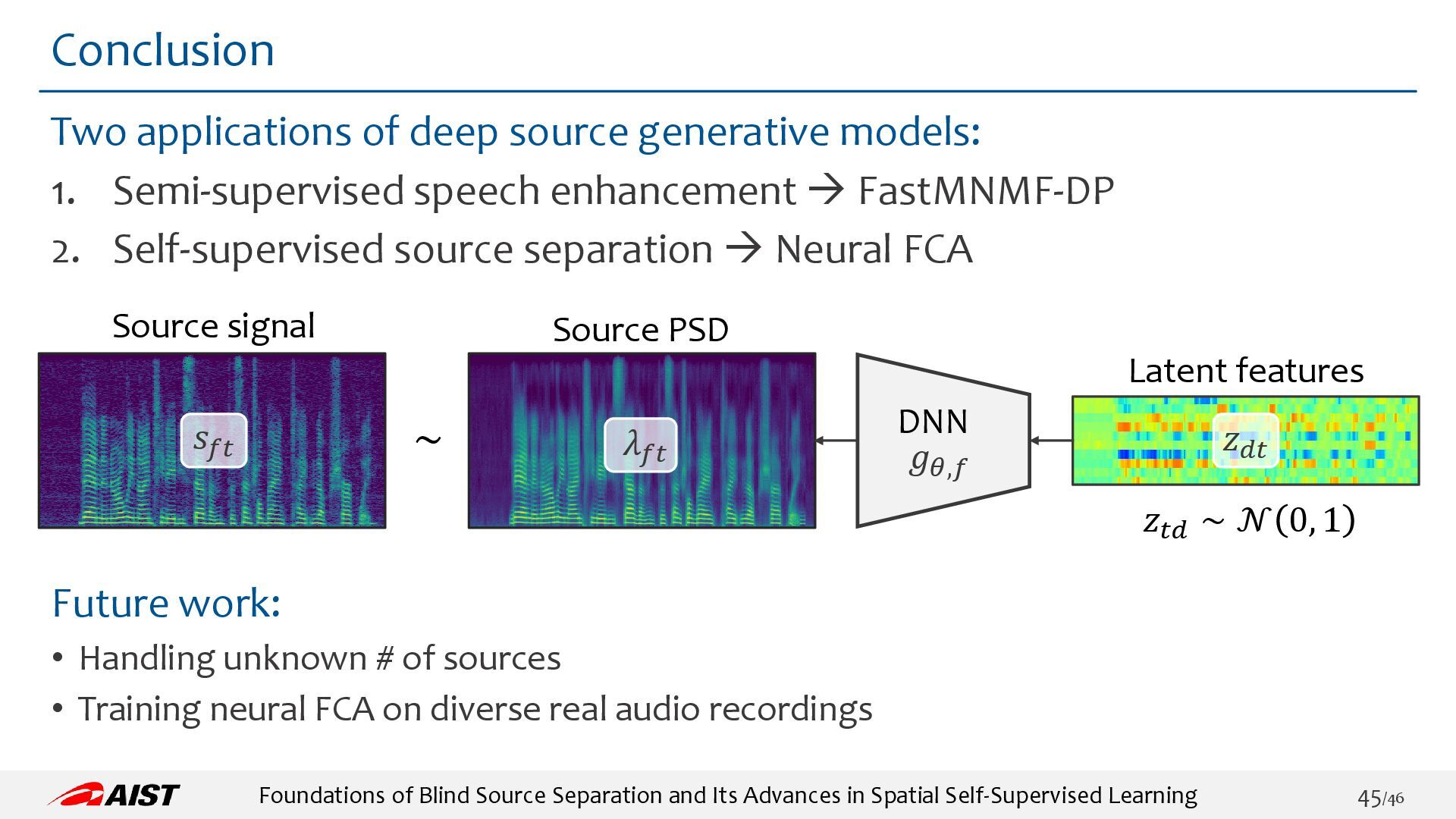{kind=link}