Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MixPoet
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Zhang Yixiao
April 30, 2020
Research
450
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MixPoet
Zhang Yixiao
April 30, 2020
More Decks by Zhang Yixiao
See All by Zhang Yixiao
CoCon
ldzhangyx
0
400
vq-cpc
ldzhangyx
0
390
diora
ldzhangyx
0
290
drummernet
ldzhangyx
0
260
ON-LSTM
ldzhangyx
0
220
Other Decks in Research
See All in Research
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
130
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
410
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
440
Language and AI
ayaniwa
0
170
コーディングエージェントとABNを再考
hf149
2
760
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
350
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
Featured
See All Featured
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
WCS-LA-2024
lcolladotor
0
680
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Optimizing for Happiness
mojombo
378
71k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Marketing to machines
jonoalderson
1
5.6k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Transcript
MixPoet: Diverse Poetry Generation via Learning Controllable Mixed Latent Space
ArXiv: 2003.06094v1 Presenter: Yixiao Zhang
Overview • Idea: 诗人经历、历史背景等 => 诗歌风格多样化 • Methods: • semi-supervised
VAE • disentangling latent space to sub-spaces • each sub-space corresponds to one factor conditioning • adversarial training
Introduction • 近年的研究,主要考虑语义连贯、主题相关 • 存在diversity的困扰 • diversity: • 主题间多样性:给定两个topic words,生成不同的诗歌
• 主题内多样性:给定一个topic word,生成不同的诗歌 • * 现有的模型倾向于记住常见pattern
Introduction • 生活经历、历史背景、文学流派 => 影响风格
Introduction • MixPoet: semi-supervised VAE • 将latent space分解为sub-spaces,与影响因子一一对应 • 训练阶段:模型预测无label诗歌的factors
• 测试阶段:指定factor的值,生成风格化的诗歌
Related Work • 诗歌生成模型 (RNNs, Memory Models, etc. ) •
多样性的先前研究: • MRL system: 强化学习,鼓励选用高TF-IDF的词汇 • USPG: 无监督最大化style vector和诗歌的mutual information
Related Work • VAE文本生成/诗歌生成 • Yang et. al, 2018b: 学习context-conditioned
latent variable • Hu et al. 2017: 对生成的诗歌进行对抗训练,增强topic相关性 • CVAE 对话多样性: Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders, ACL 2017 • 本文的对抗:在latent space上做对抗训练
Method • topic keyword: mixture empirical distributions: labeled/ unlabeled
Method: Generator • GRU based model • 是length embedding
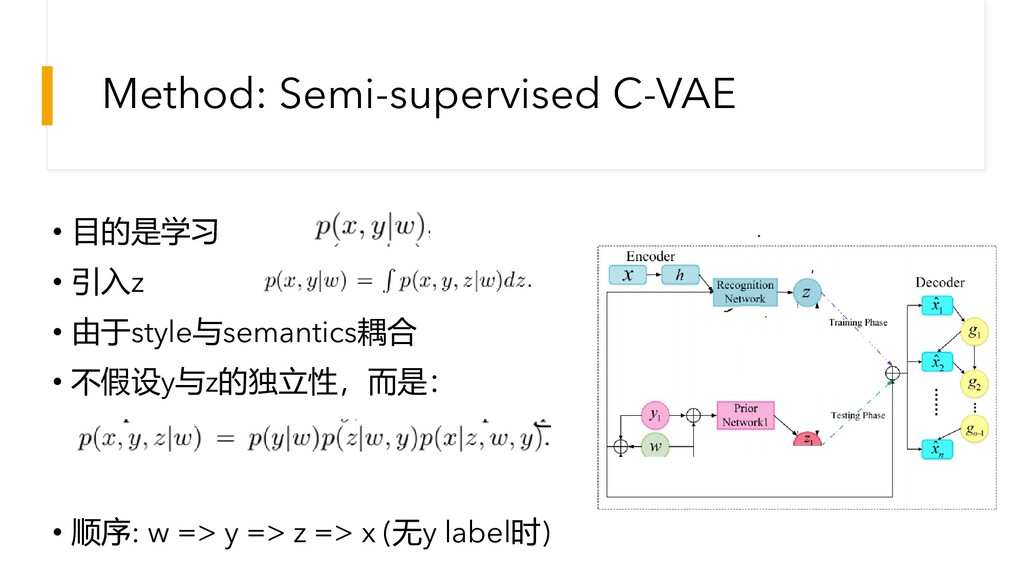
Method: Semi-supervised C-VAE • 目的是学习 • 引入z • 由于style与semantics耦合 •
不假设y与z的独立性,而是: • 顺序: w => y => z => x (无y label时)
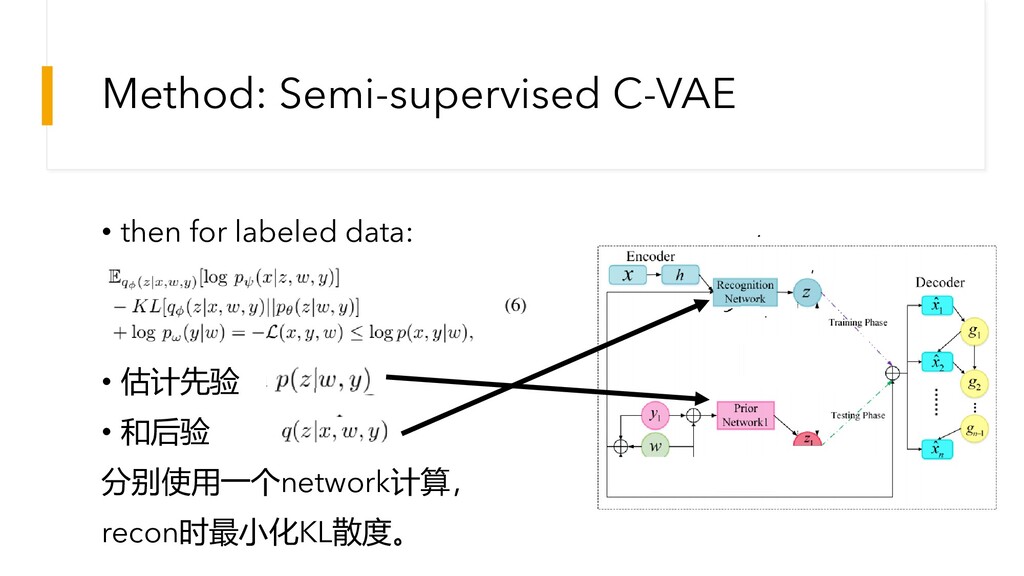
Method: Semi-supervised C-VAE • then for labeled data: • 估计先验
• 和后验 分别使用一个network计算, recon时最小化KL散度。
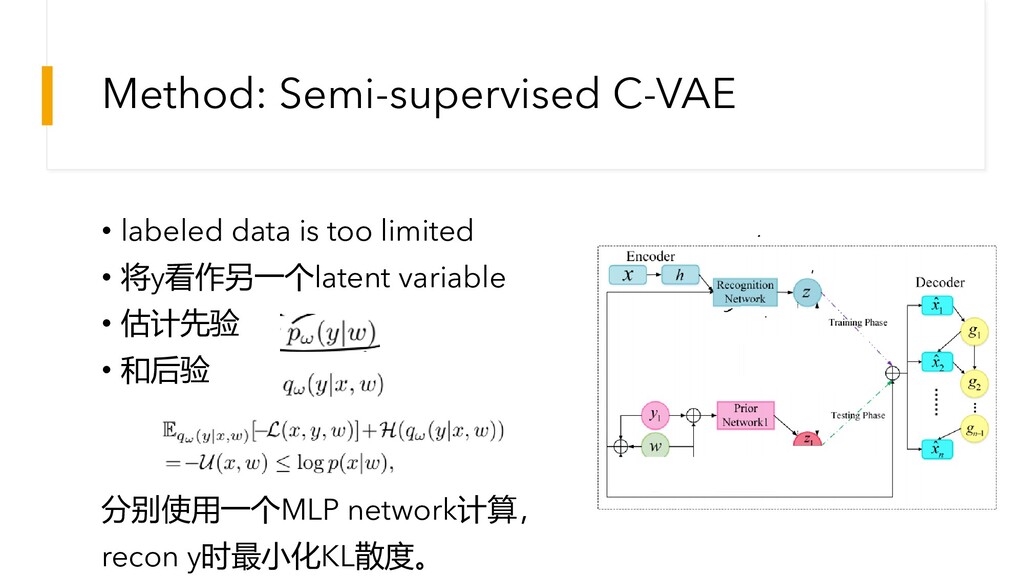
Method: Semi-supervised C-VAE • labeled data is too limited •
将y看作另一个latent variable • 估计先验 • 和后验 分别使用一个MLP network计算, recon y时最小化KL散度。
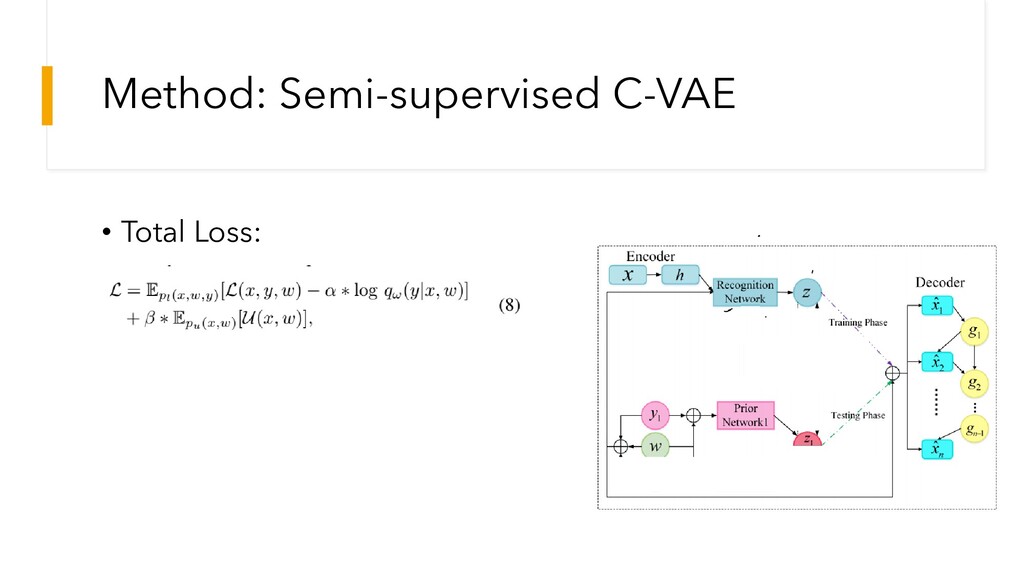
Method: Semi-supervised C-VAE • Total Loss:
Method: Latent Space Mixture • 多个factor时的情形: • 独立性假设:
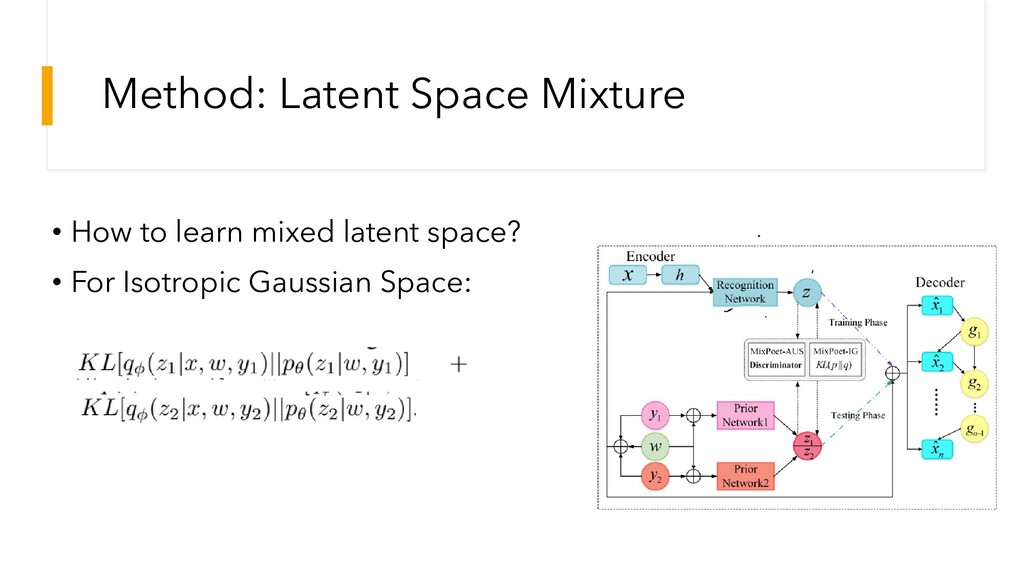
Method: Latent Space Mixture • How to learn mixed latent
space? • For Isotropic Gaussian Space:
Method: Latent Space Mixture • How to learn mixed latent
space? • For Universal Space: 对于condition: ita是噪声,delta是脉冲函数,c是w, y => 从分布中sample出一个值
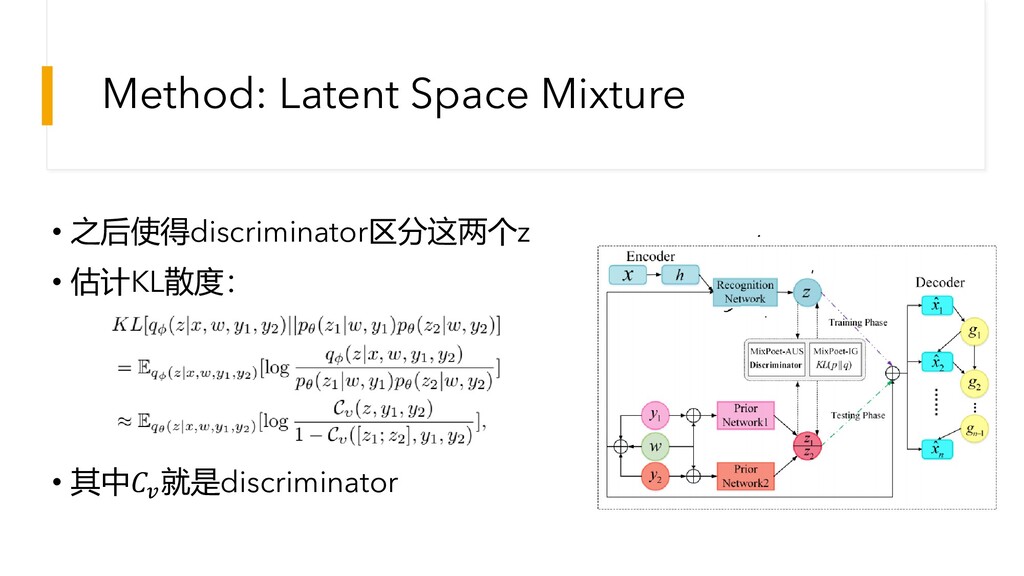
Method: Latent Space Mixture • 之后使得discriminator区分这两个z • 估计KL散度: • 其中
就是discriminator
Experiments • factors: • 军旅生涯, 乡村生活, 其他 • 时代繁荣, 时代衰落
• => 6种style
Experiments • Baseline: • Ground Truth • C-VAE • USPG
• MRL: SOTA • fBasic, 监督学习模型
Experiments • 多样性,使用Jaccard Similarity指数评价,越低越好 • 诗歌质量:使用Language Model Score(LMS)评价 • 观察:
• 大多数模型倾向生成重复的短语 • MRL与Basic在intra部分只能生成极其相似的诗歌 • C-VAE情况类似
Experiments • Factor Control Results: • 测试生成的诗歌是否与给定因子类别一致
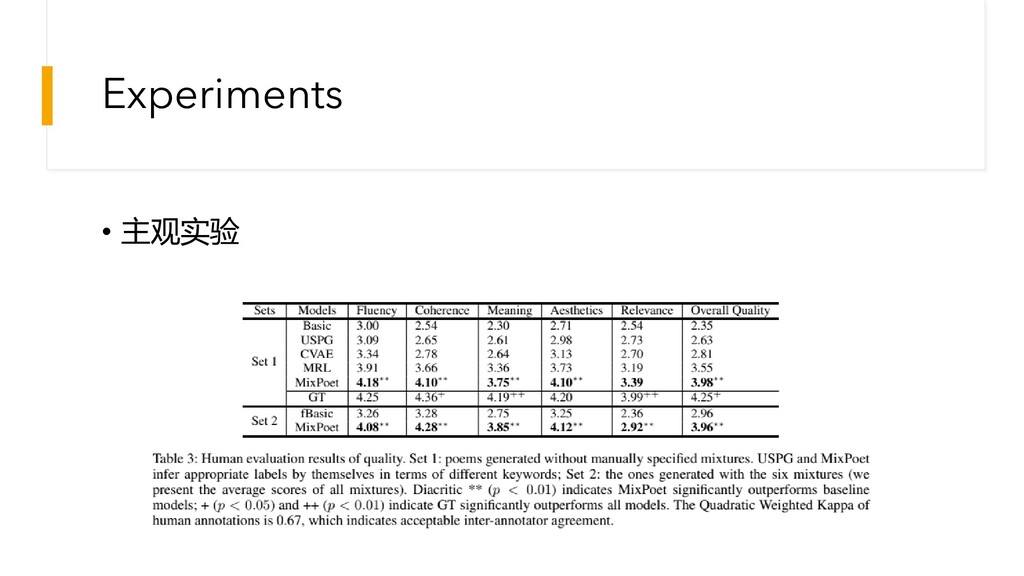
Experiments • 主观实验
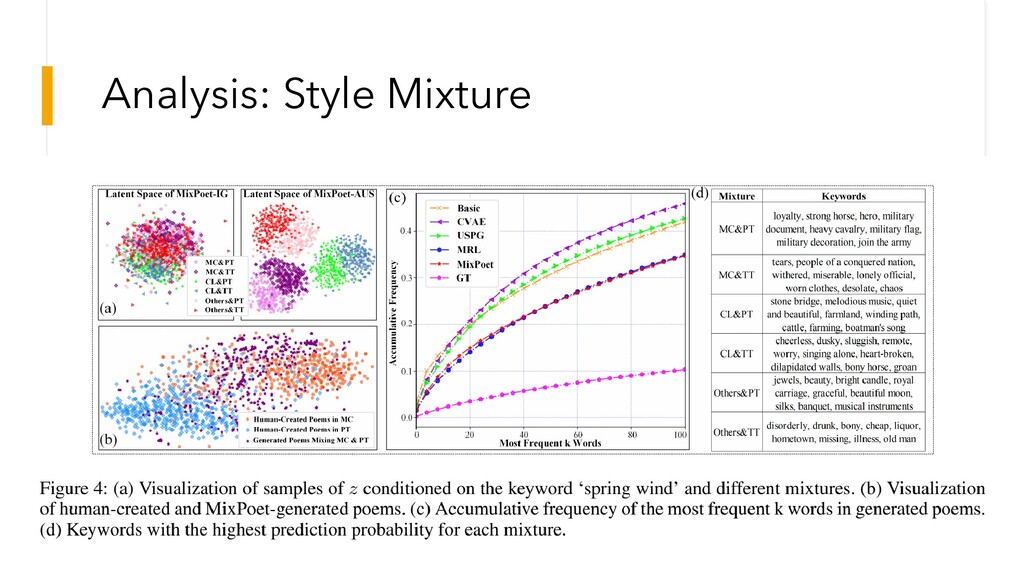
Analysis: Style Mixture
Analysis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}