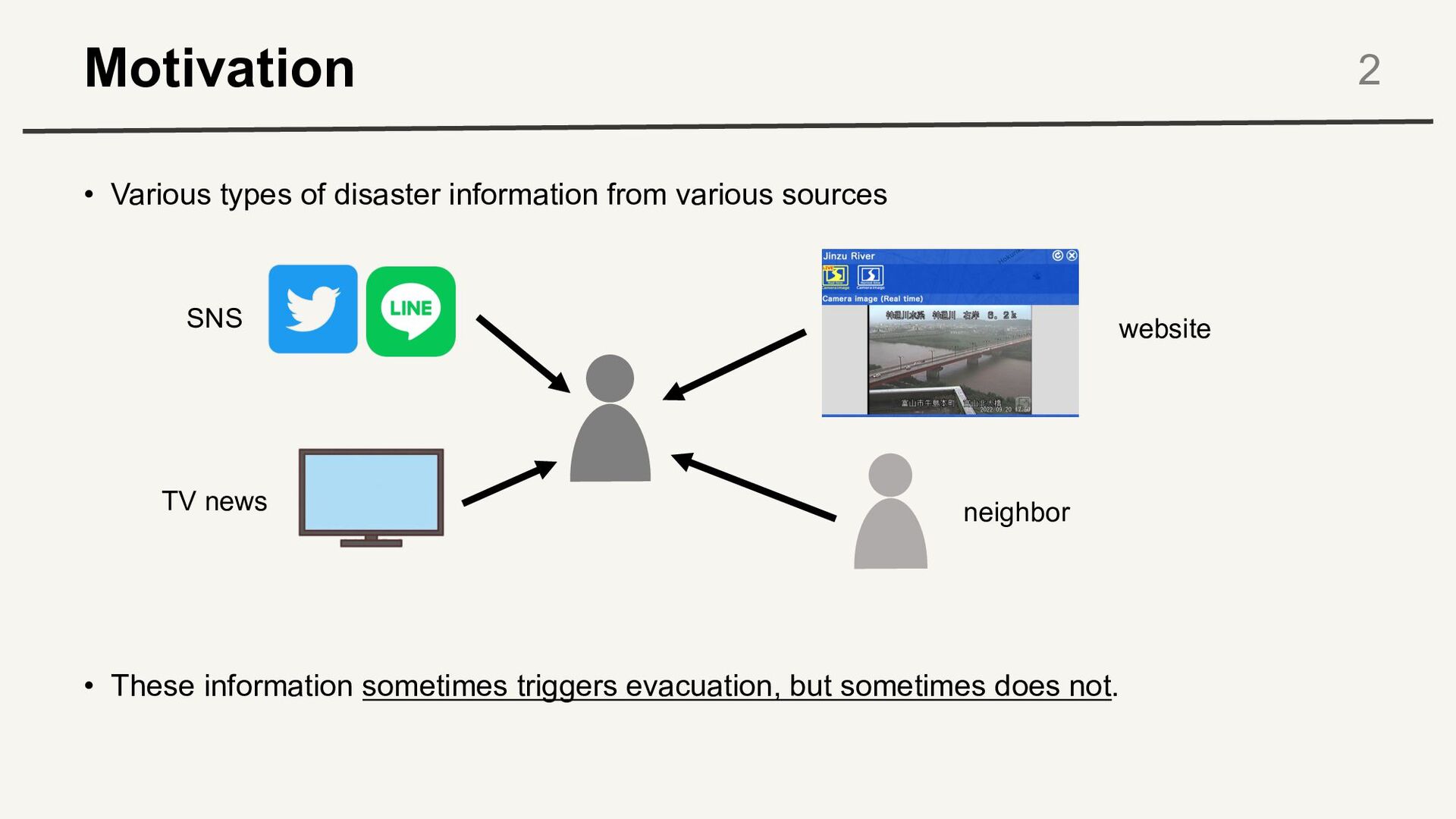
Presentation slides for the 12th International Conference of the International Society for the Integrated Disaster Risk Management (IDRiM), entitled "Evacuation choice modeling using reinforcement learning based on the multi-armed bandit problem."
bandit problem Satoki MASUDA, Eiji HATO Department of Civil Engineering, The University of Tokyo [email protected] At IDRiM2022, Thu. 22 September., Young Scientist Session Group I
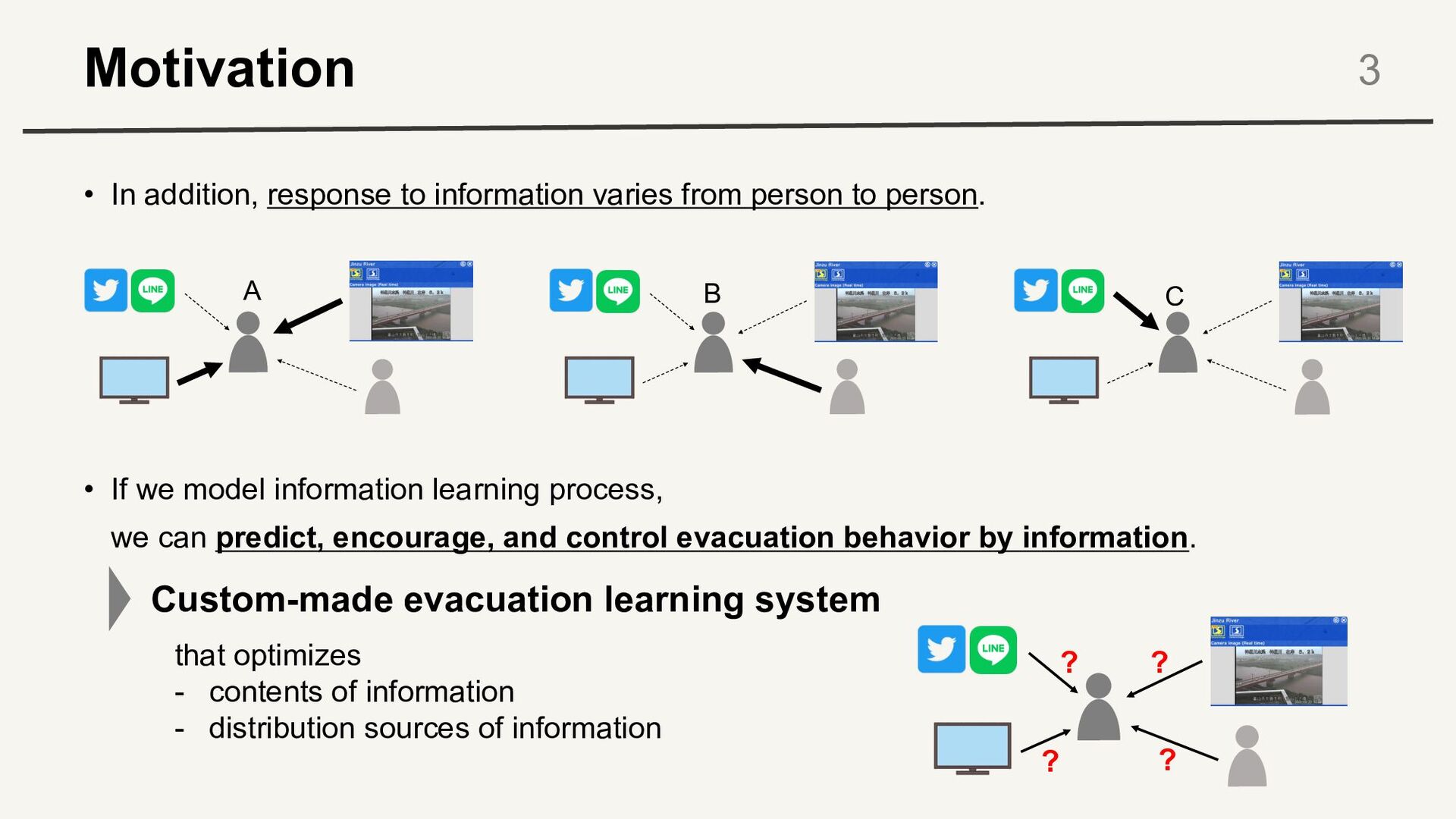
to person. 3 • If we model information learning process, we can predict, encourage, and control evacuation behavior by information. A B C Custom-made evacuation learning system ? ? ? ? that optimizes - contents of information - distribution sources of information
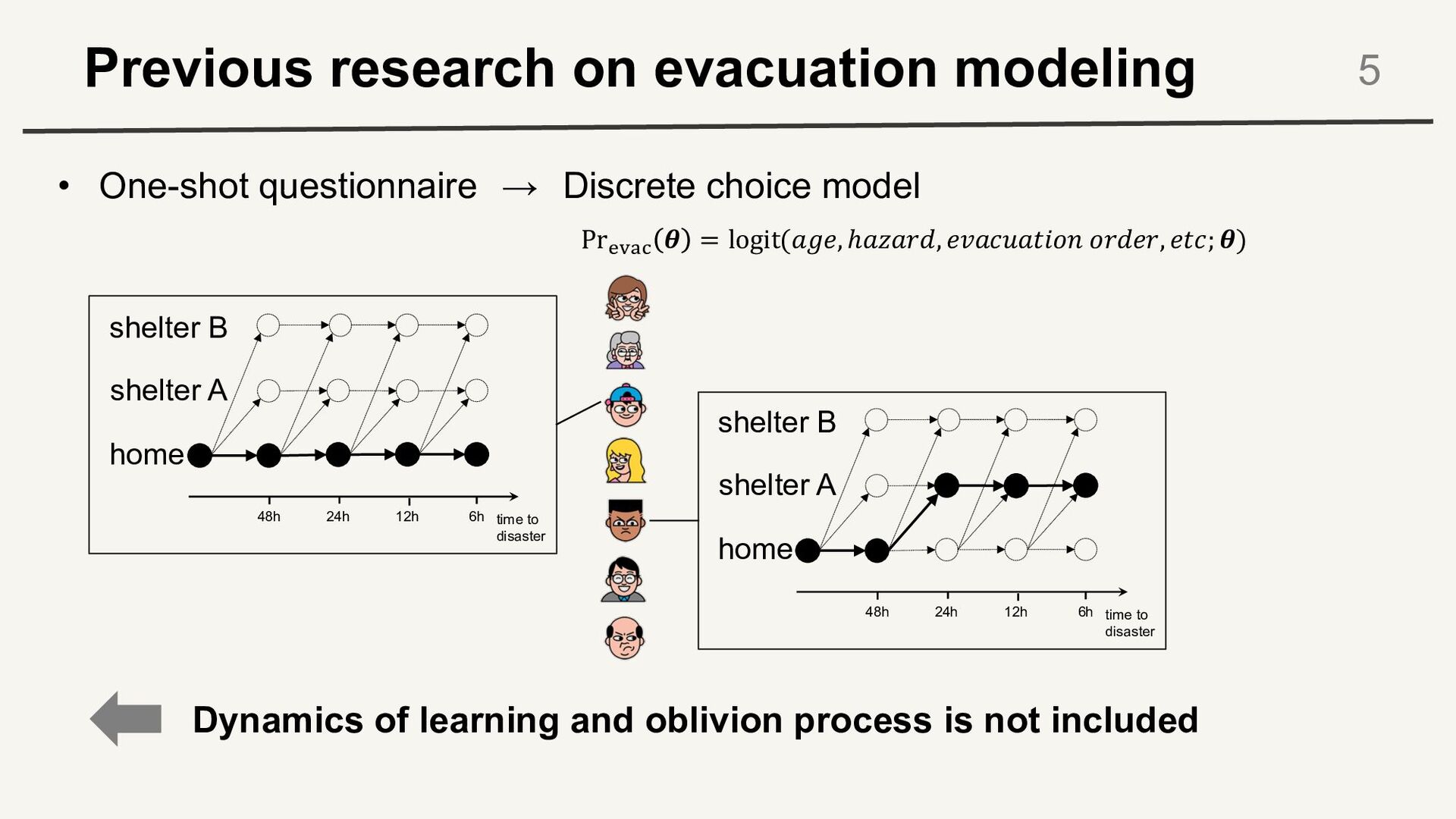
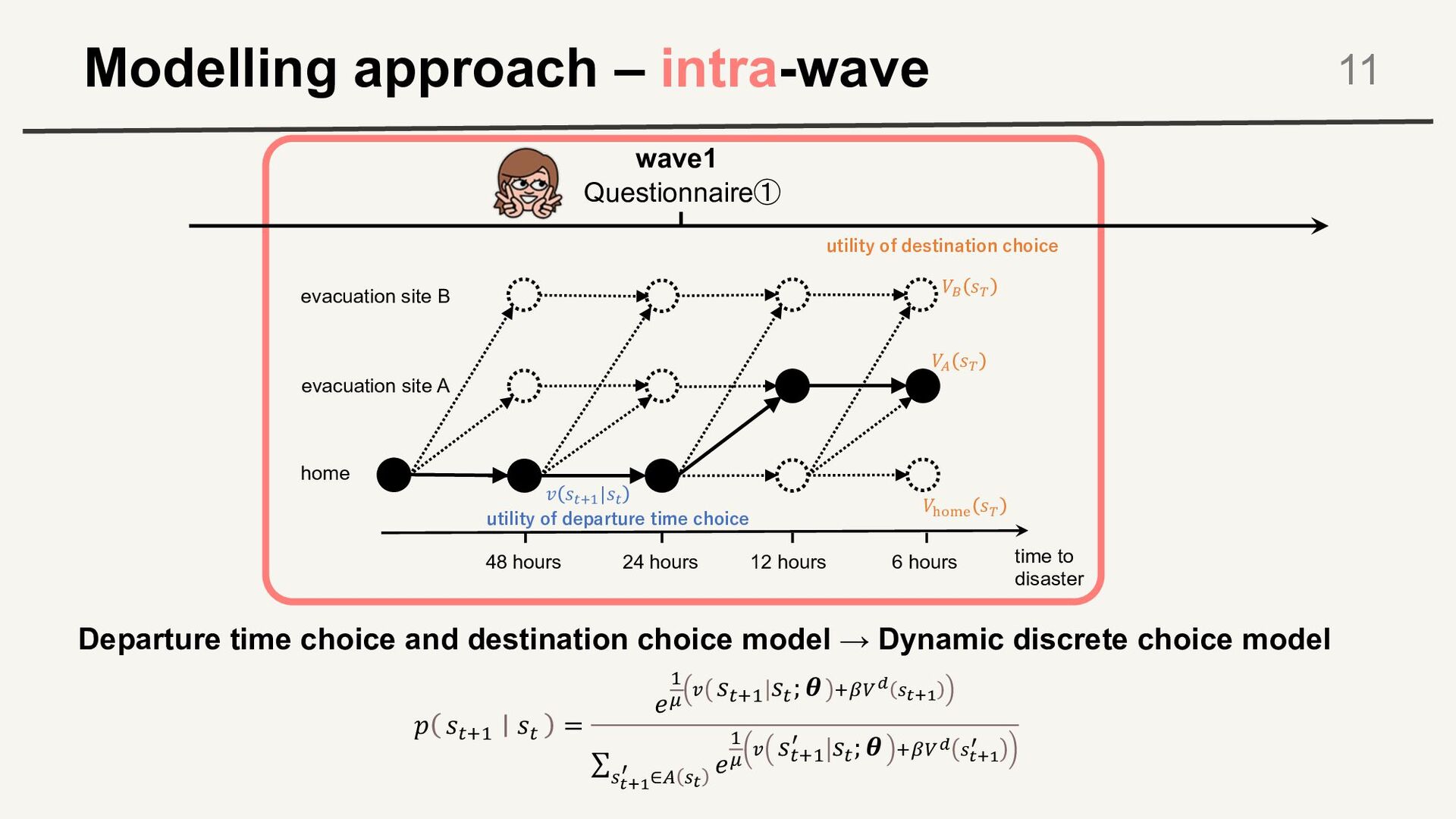
Discrete choice model time to disaster 48h 6h 24h 12h home shelter A shelter B time to disaster 48h 6h 24h 12h home shelter A shelter B Pr!"#$ 𝜽 = logit(𝑎𝑔𝑒, ℎ𝑎𝑧𝑎𝑟𝑑, 𝑒𝑣𝑎𝑐𝑢𝑎𝑡𝑖𝑜𝑛 𝑜𝑟𝑑𝑒𝑟, 𝑒𝑡𝑐; 𝜽) Dynamics of learning and oblivion process is not included
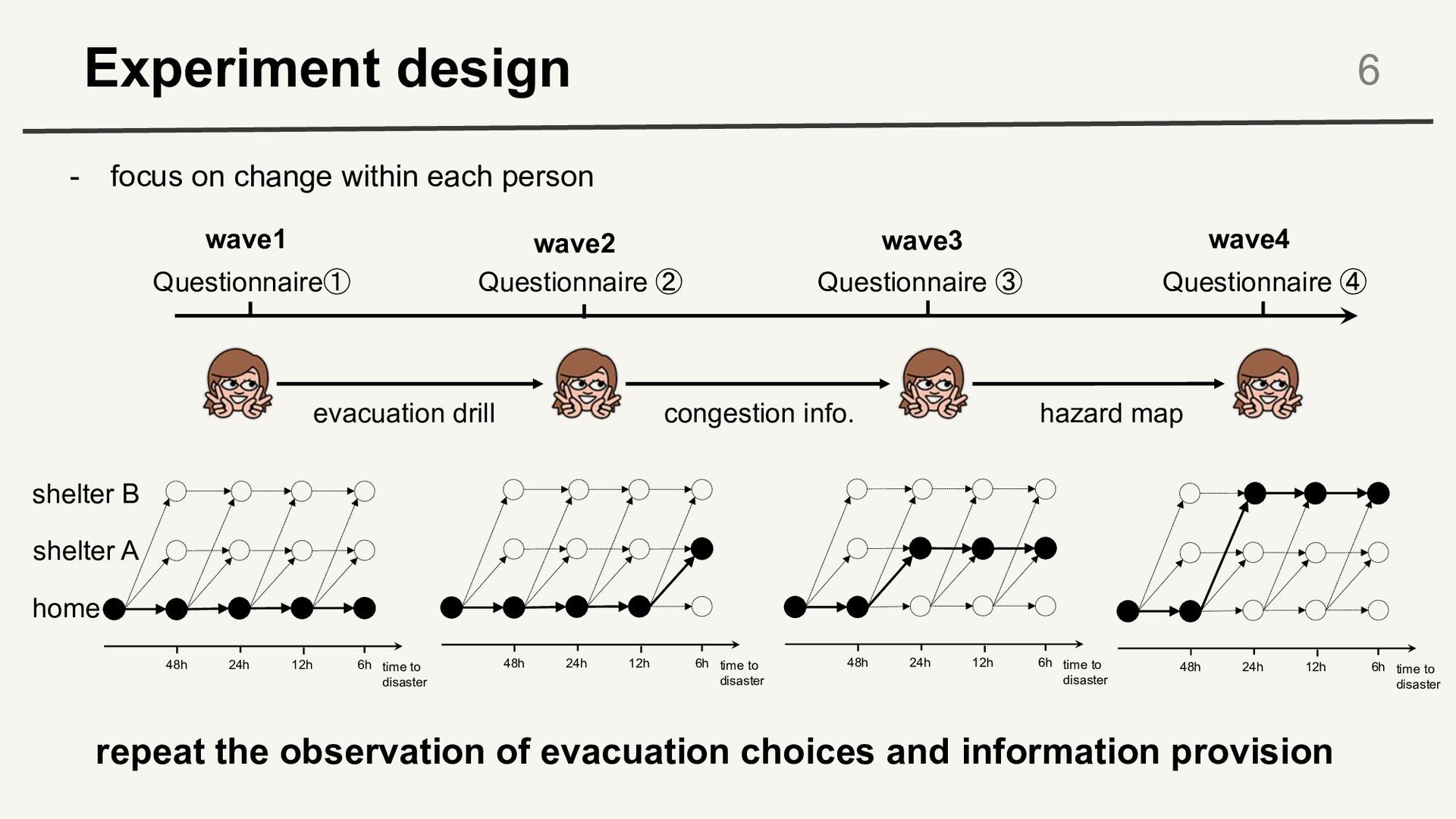
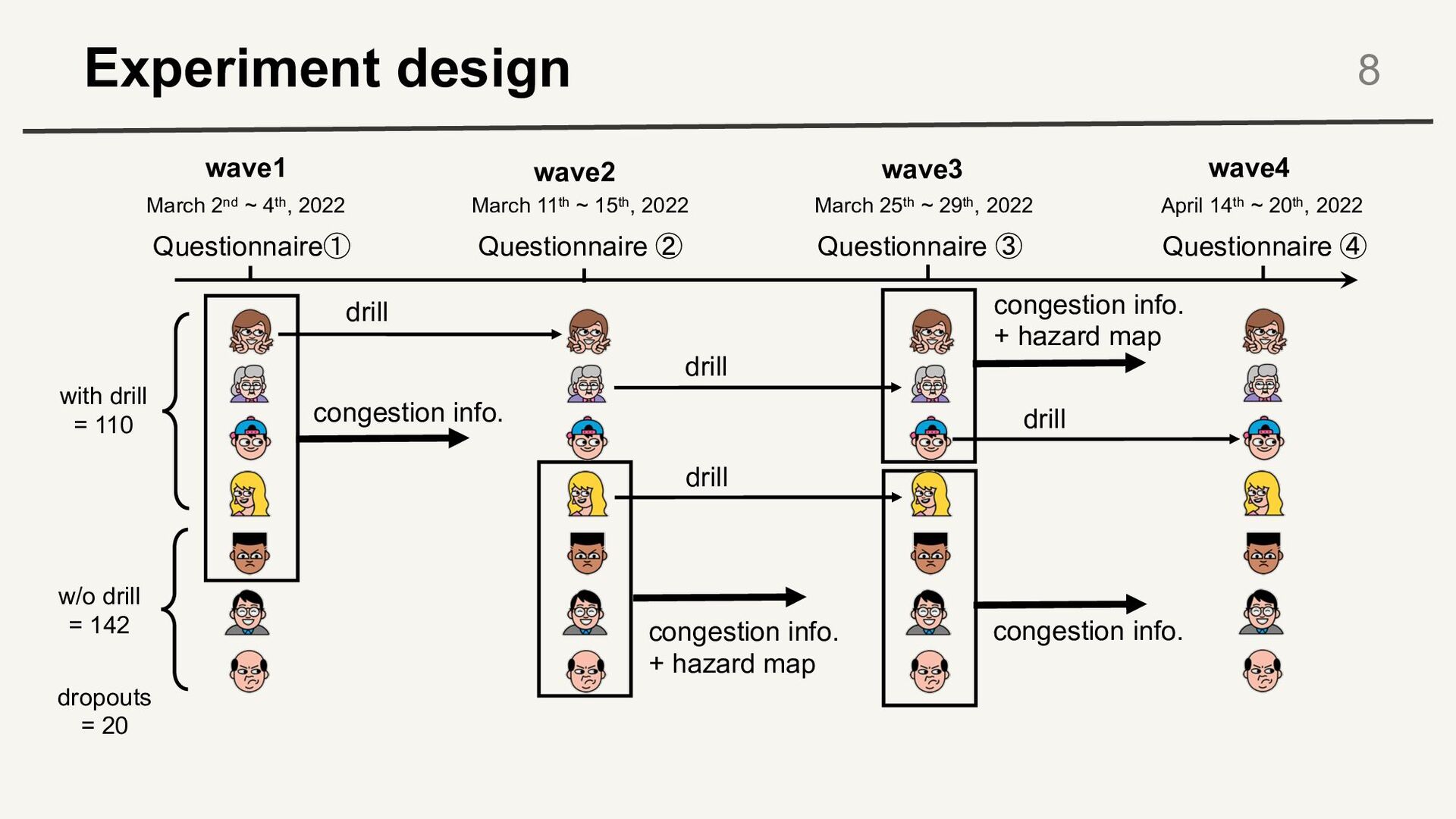
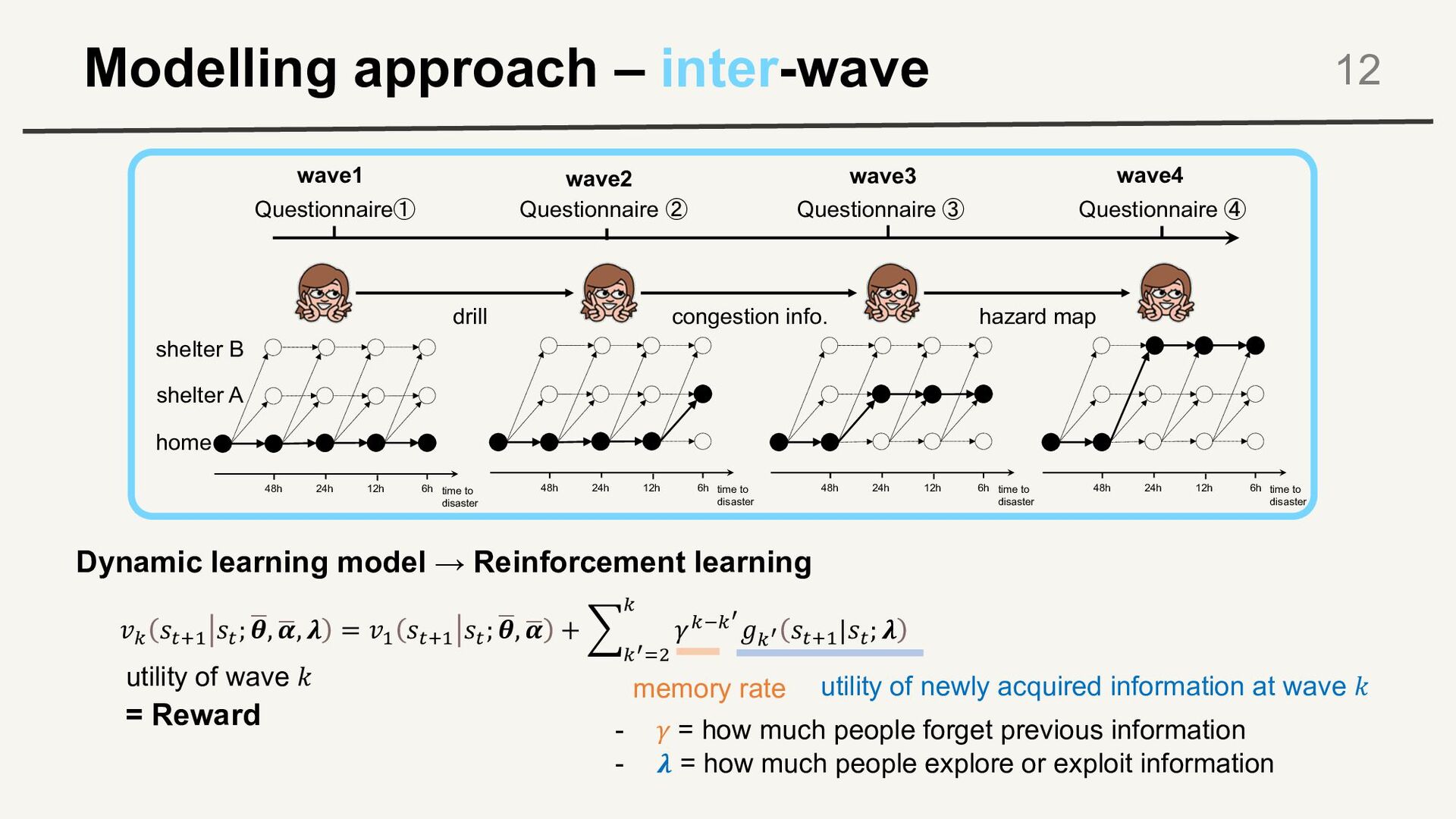
48h 6h 24h 12h time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h home shelter A shelter B congestion info. Questionnaire① Questionnaire ④ Questionnaire ② Questionnaire ③ wave1 wave2 wave3 wave4 repeat the observation of evacuation choices and information provision - focus on change within each person
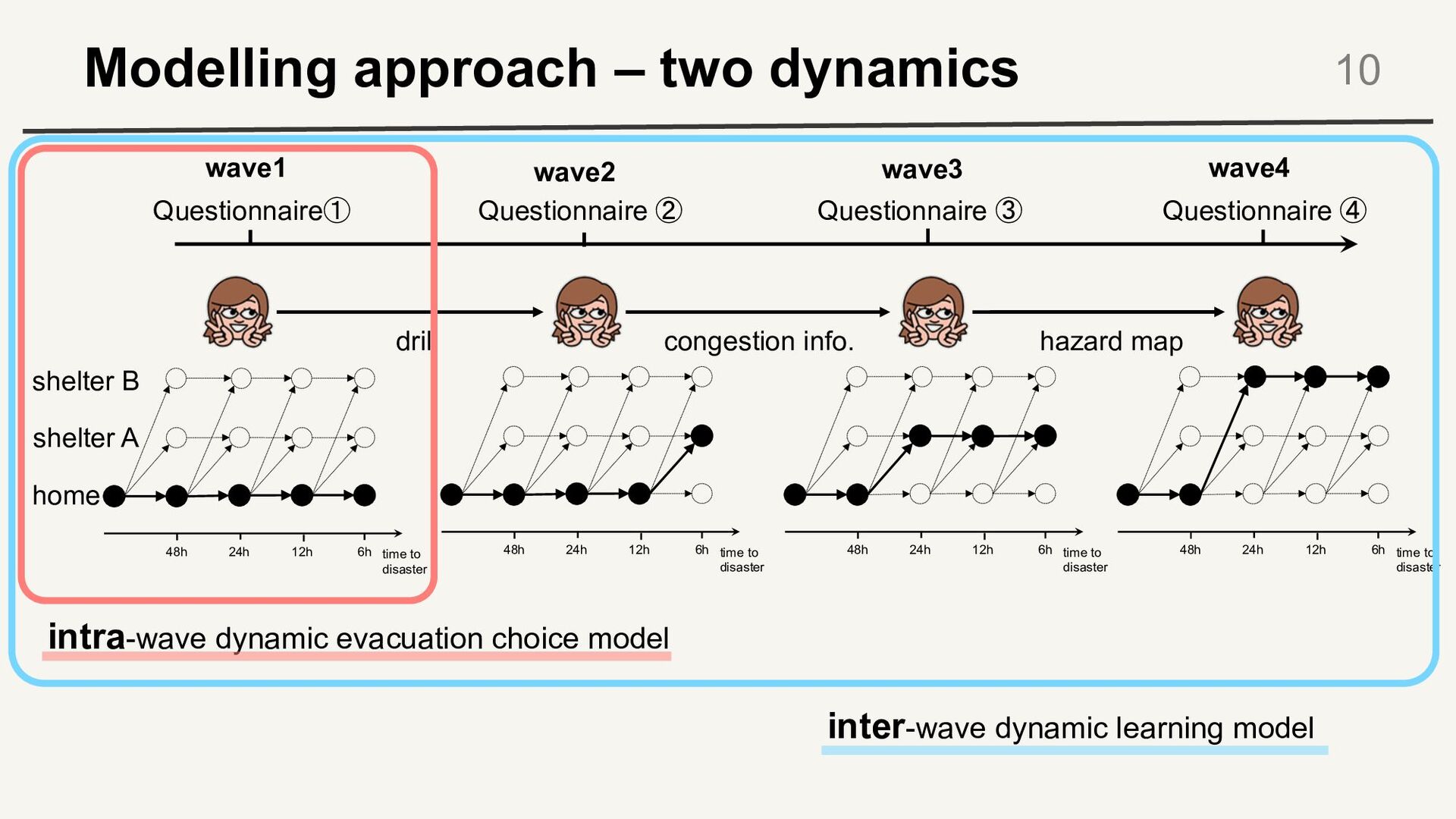
to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h home shelter A shelter B congestion info. Questionnaire① Questionnaire ④ Questionnaire ② Questionnaire ③ wave1 wave2 wave3 wave4 intra-wave dynamic evacuation choice model inter-wave dynamic learning model
𝜽, ? 𝜶, 𝝀 = 𝑣' 𝑠%&' 𝑠% ; ? 𝜽, ? 𝜶 + C 0%12 0 𝛾030% 𝑔0% 𝑠%&' |𝑠% ; 𝝀 Dynamic learning model → Reinforcement learning utility of wave 𝑘 memory rate utility of newly acquired information at wave 𝑘 drill hazard map time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h time to disaster 48h 6h 24h 12h home shelter A shelter B congestion info. Questionnaire① Questionnaire ④ Questionnaire ② Questionnaire ③ wave1 wave2 wave3 wave4 - 𝛾 = how much people forget previous information - 𝝀 = how much people explore or exploit information = Reward
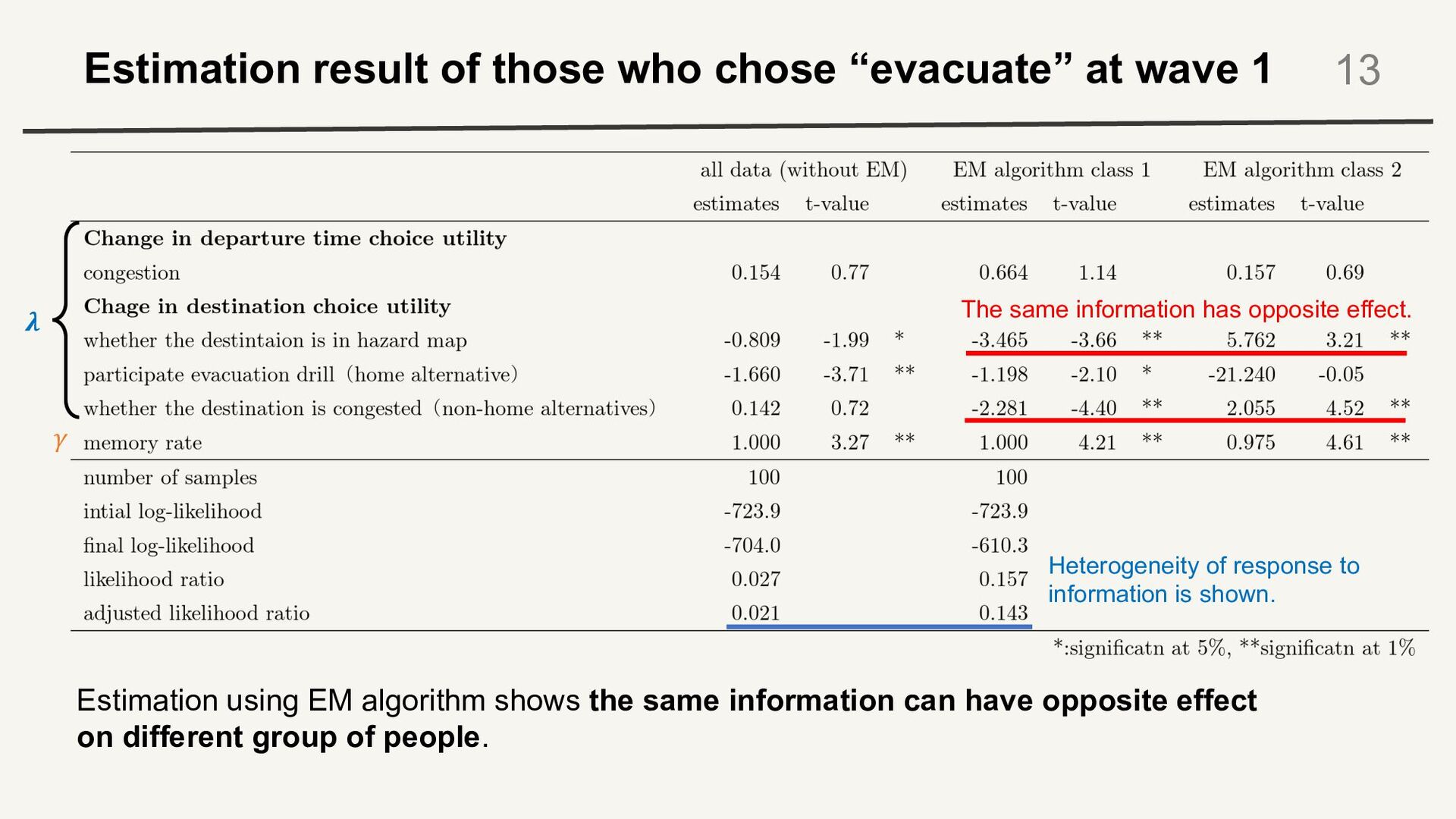
13 𝝀 𝛾 The same information has opposite effect. Heterogeneity of response to information is shown. Estimation using EM algorithm shows the same information can have opposite effect on different group of people.
relation between information learning and behavioral change. ü We modeled dynamics of information learning process using the idea of reinforcement learning. ü Parameter estimation using EM algorithm shows the heterogeneity of learning process. ü The dynamic learning model will lead to predicting, encouraging, and controlling evacuation behavior by information. ★Point to discuss - What kind of application can we design if we understand and predict effect of DRR education on each person?
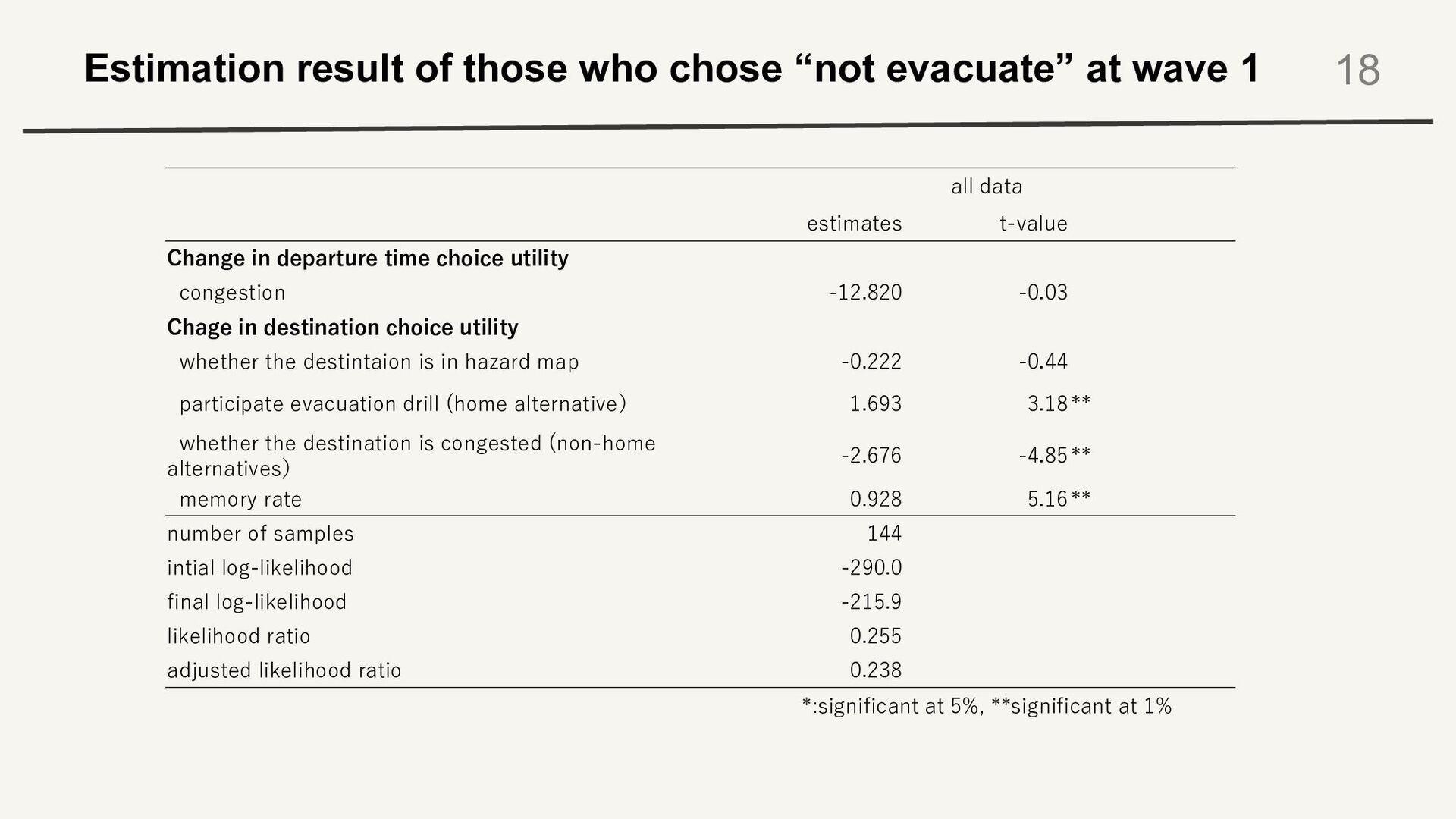
1 18 all data estimates t-value Change in departure time choice utility congestion -12.820 -0.03 Chage in destination choice utility whether the destintaion is in hazard map -0.222 -0.44 participate evacuation drill (home alternative) 1.693 3.18** whether the destination is congested (non-home alternatives) -2.676 -4.85** memory rate 0.928 5.16** number of samples 144 intial log-likelihood -290.0 final log-likelihood -215.9 likelihood ratio 0.255 adjusted likelihood ratio 0.238 *:significant at 5%, **significant at 1%
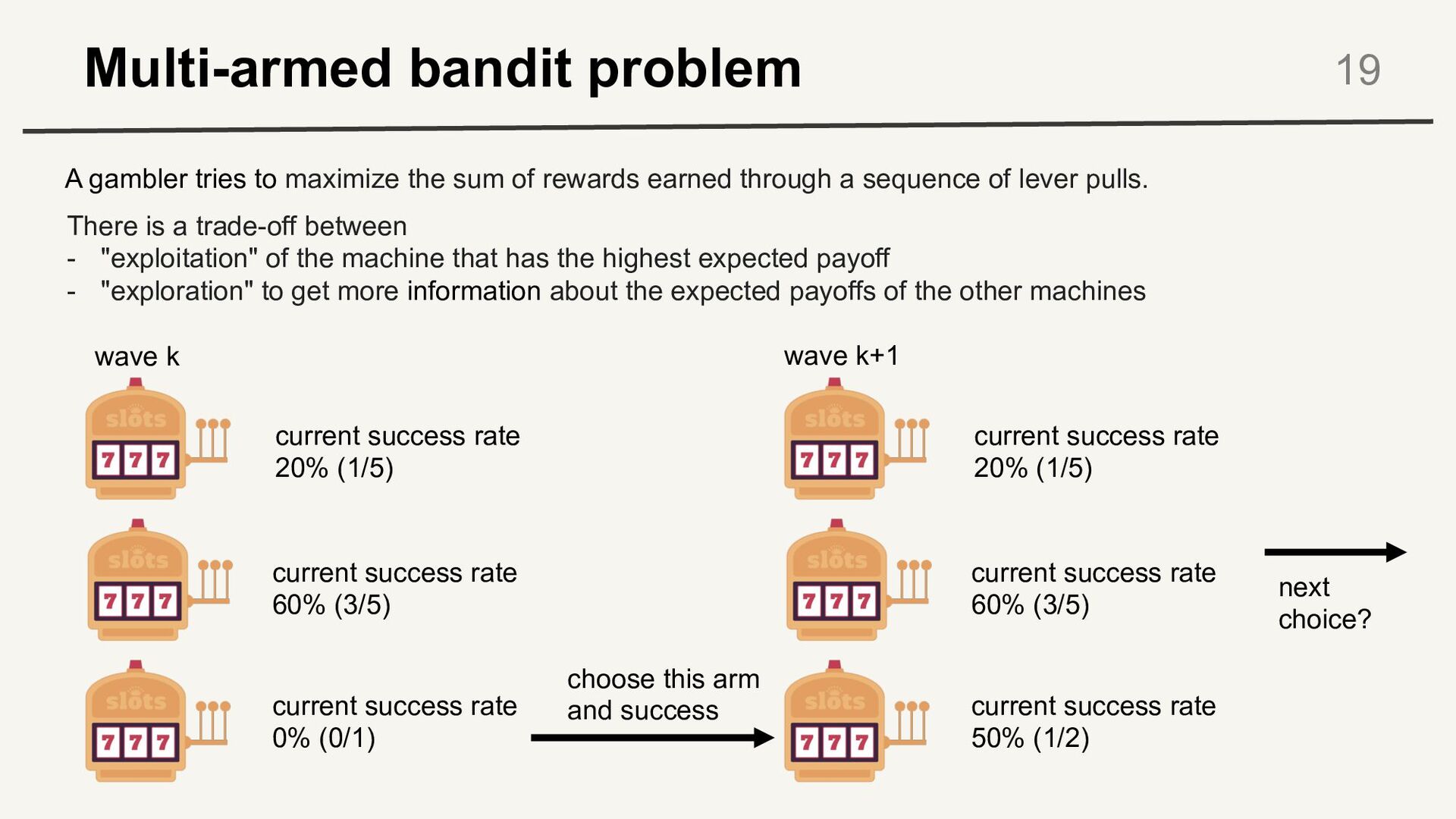
success rate 60% (3/5) current success rate 0% (0/1) current success rate 20% (1/5) current success rate 60% (3/5) current success rate 50% (1/2) wave k wave k+1 choose this arm and success next choice? A gambler tries to maximize the sum of rewards earned through a sequence of lever pulls. There is a trade-off between - "exploitation" of the machine that has the highest expected payoff - "exploration" to get more information about the expected payoffs of the other machines
(trial times) must be allocated between competing choices (slot machines) in a way that maximizes their expected gain (money), when each choice's properties are only partially known at the time of allocation, and may become better understood as time passes or by allocating resources to the choice. • In evacuation learning, - trial times = learning cost - slot machines = evacuation choices (departure time, destination…) - money = utility 20
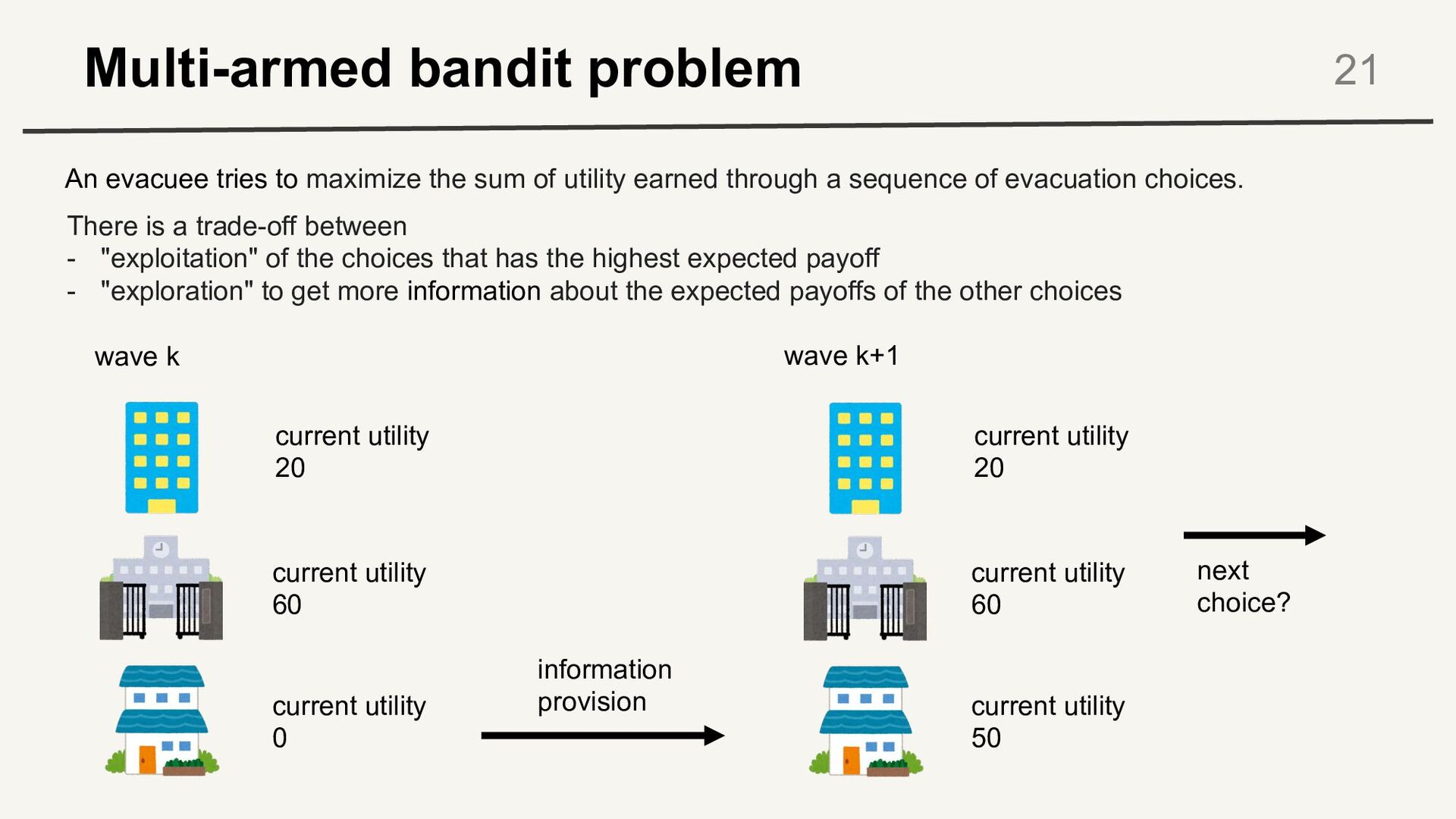
tries to maximize the sum of utility earned through a sequence of evacuation choices. There is a trade-off between - "exploitation" of the choices that has the highest expected payoff - "exploration" to get more information about the expected payoffs of the other choices current utility 20 current utility 60 current utility 0 wave k current utility 20 current utility 60 current utility 50 wave k+1
under the partial knowledge about reward • Our study exploring reward system under the policy of utility maximization (inverse reinforcement learning) 22
𝜽, ? 𝜶, 𝝀 = 𝑣' 𝑠%&' 𝑠% ; ? 𝜽, ? 𝜶 + C 0%12 0 𝛾030% 𝑔0% 𝑠%&' |𝑠% ; 𝝀 • Update utility function (Reward) 𝑣0 𝑠%&' 𝑠% ; ? 𝜽, ? 𝜶, 𝝀 : utility of wave k 𝛾030% : memory rate 𝑔0% 𝑠%&' |𝑠% ; 𝝀 : utility of newly acquired information at wave k • risk of residence area • socio-demographic variables • congestion • hazard map • The utility of evacuation choice is updated when one gets disaster information • But the information is forgotten by the memory rate 𝜸
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15 Thank you for listening! Contact: [email protected]](https://files.speakerdeck.com/presentations/d33e1b1796cb4830b58b1c3fa7512d6f/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}