Keichi Takahashi, Tomonori Hayami, Yu Mukaizono, Yuki Teramae, Susumu Date, "Performance analysis of mdx II: A next-generation cloud platform for cross-disciplinary data science research," 15th International Conference on Cloud Computing and Services Science (CLOSER 2025), Apr. 2025.
{kind=link}
{kind=link}
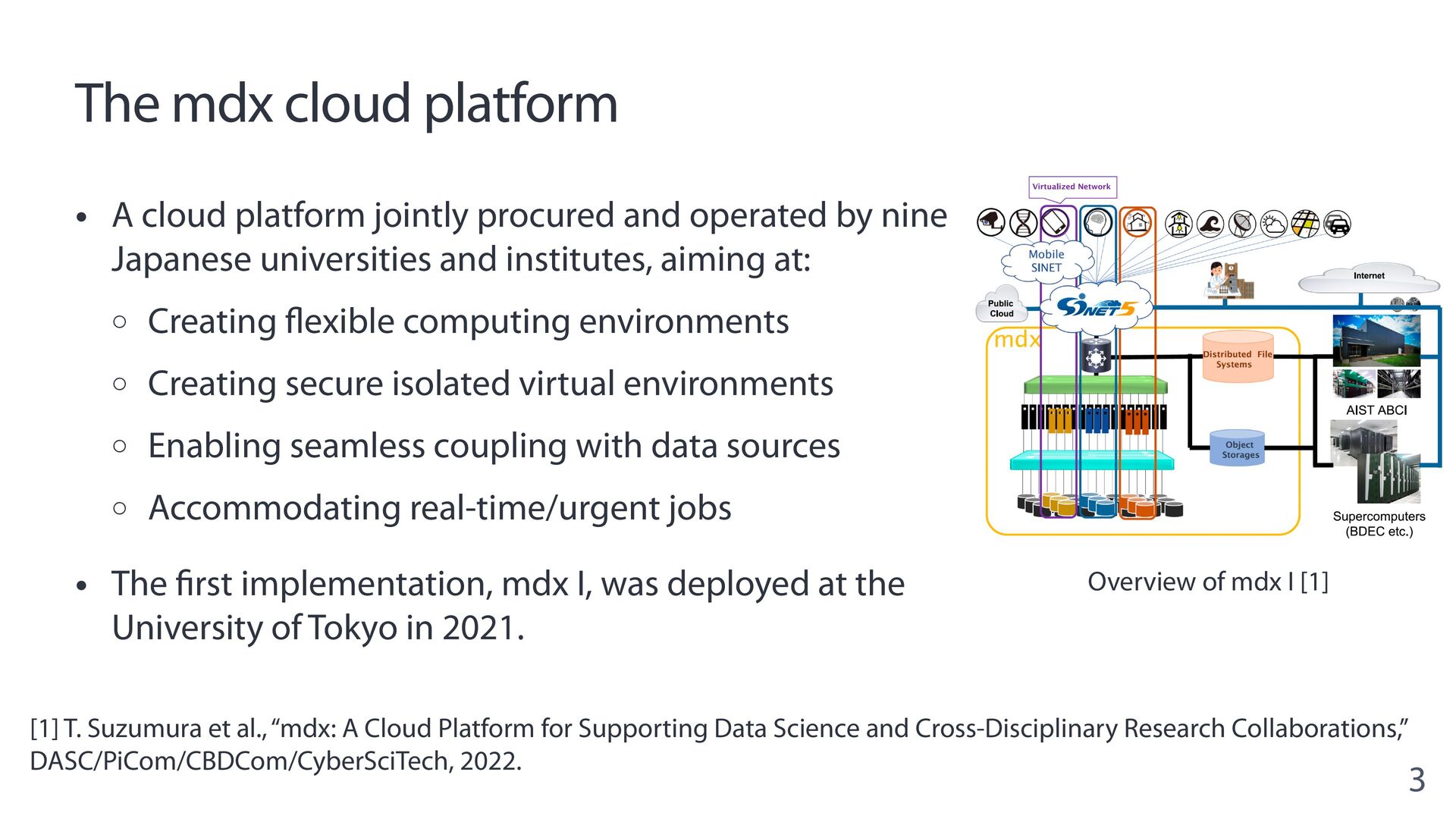{kind=link}
{kind=link}
{kind=link}
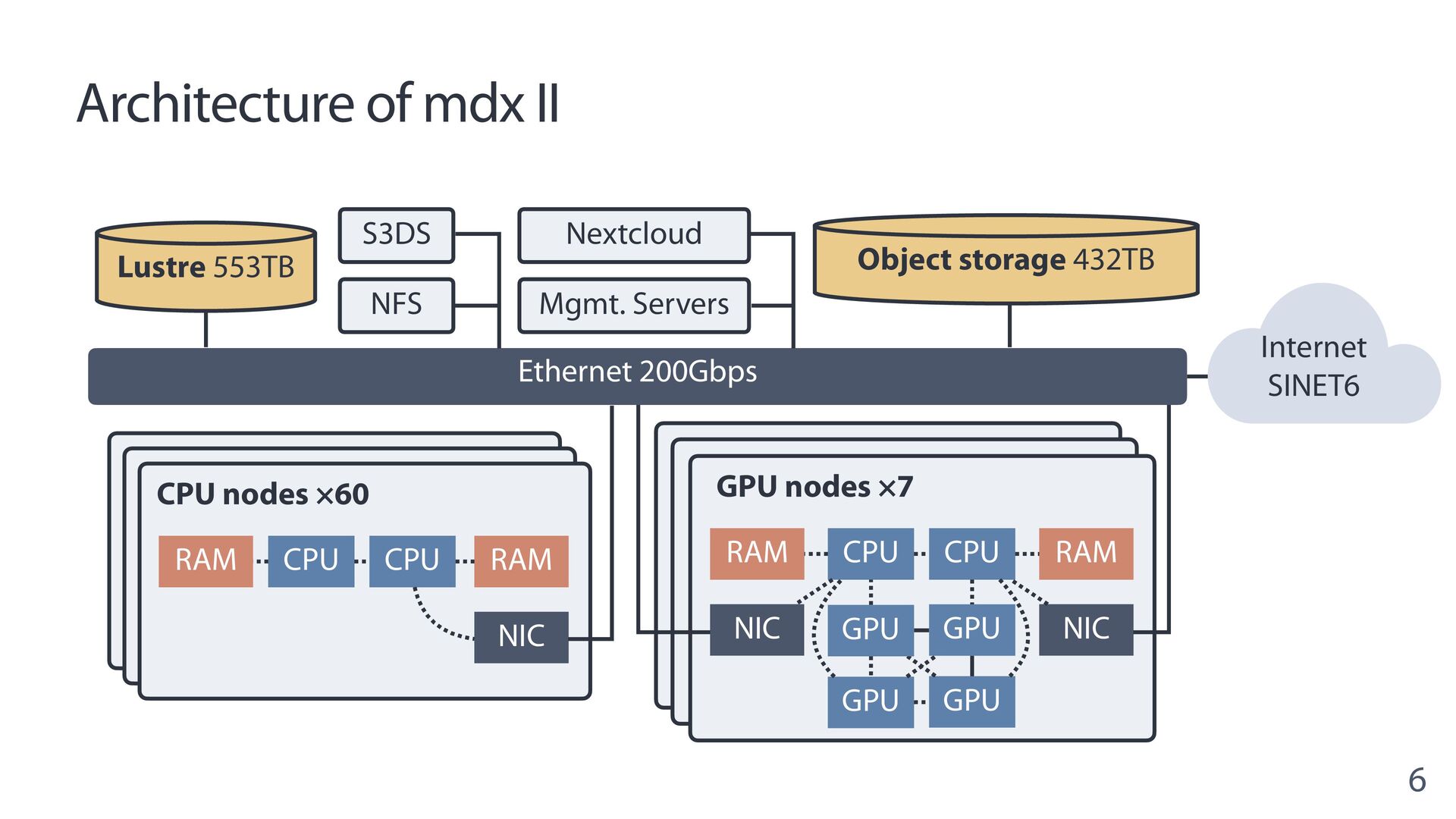{kind=link}
{kind=link}
{kind=link}
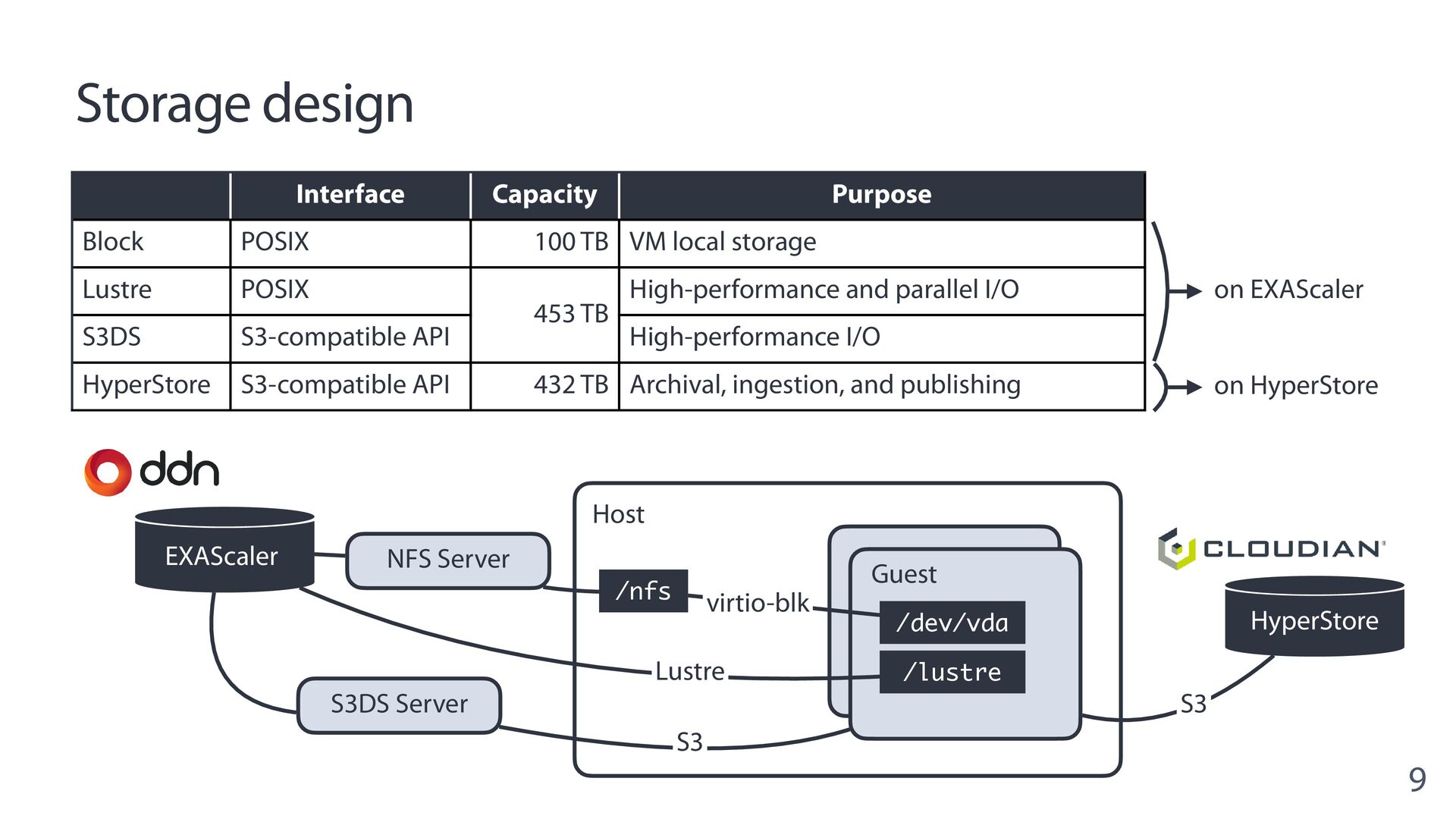{kind=link}
{kind=link}
{kind=link}
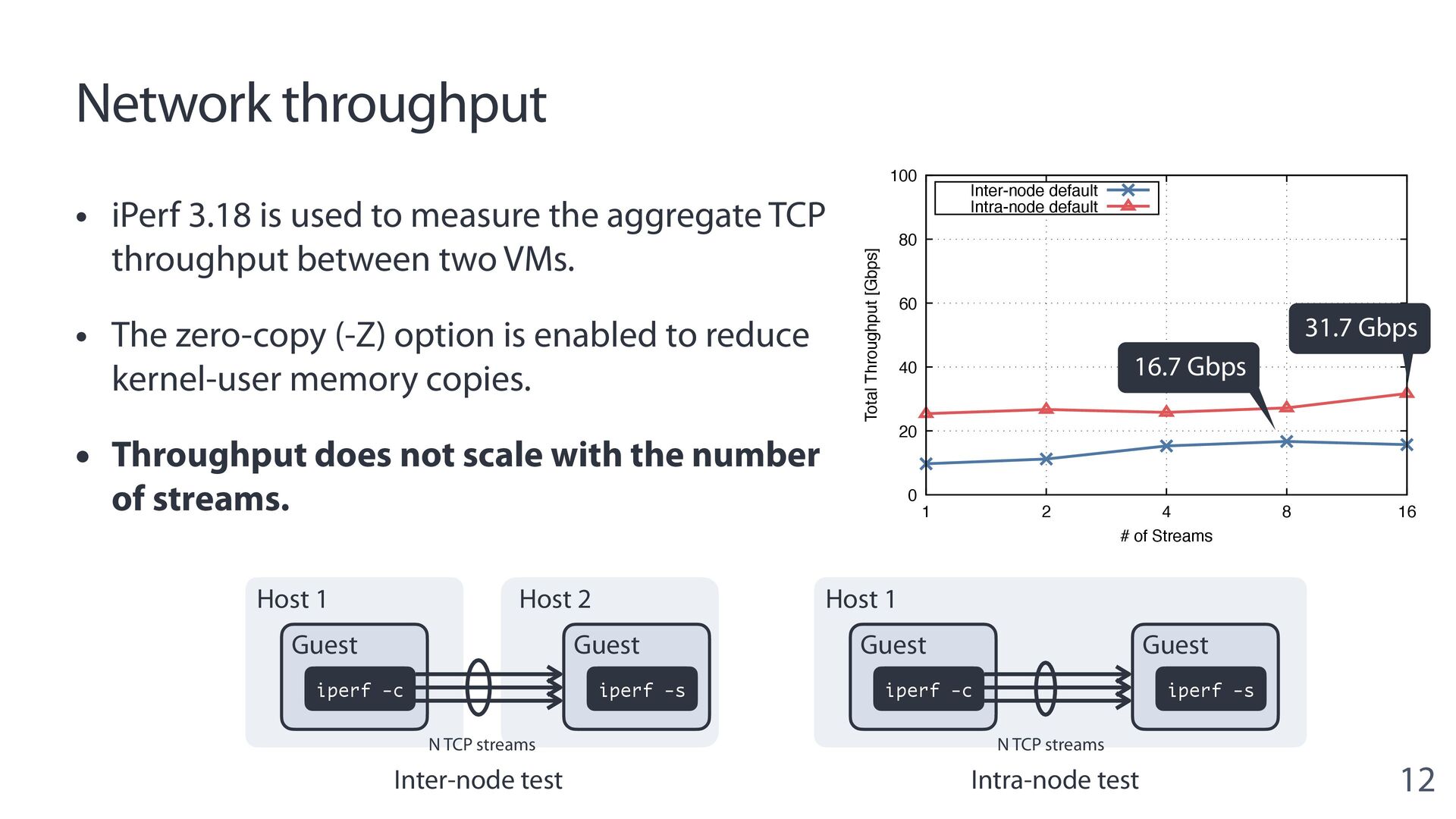{kind=link}
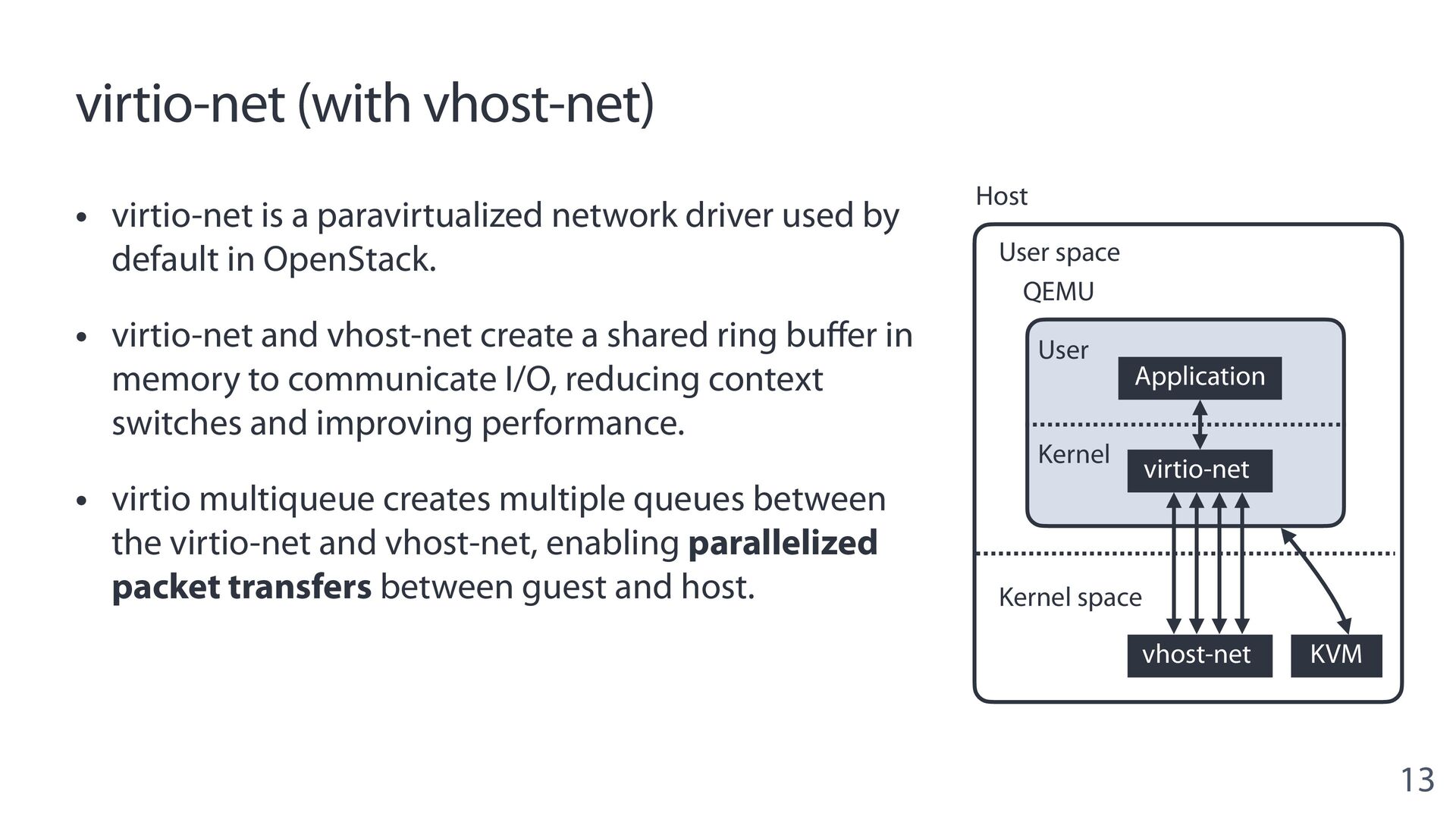{kind=link}
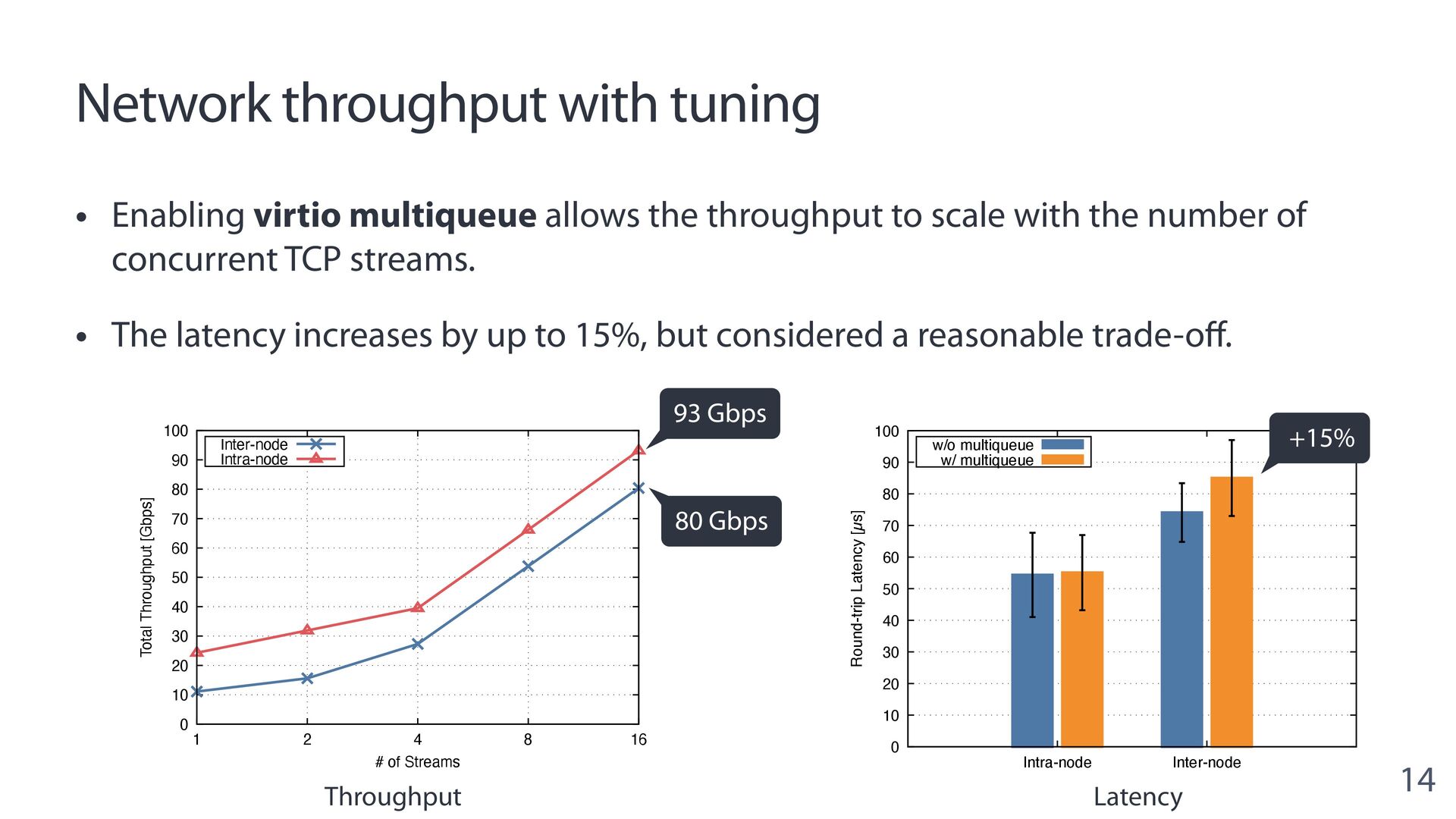{kind=link}
{kind=link}
{kind=link}
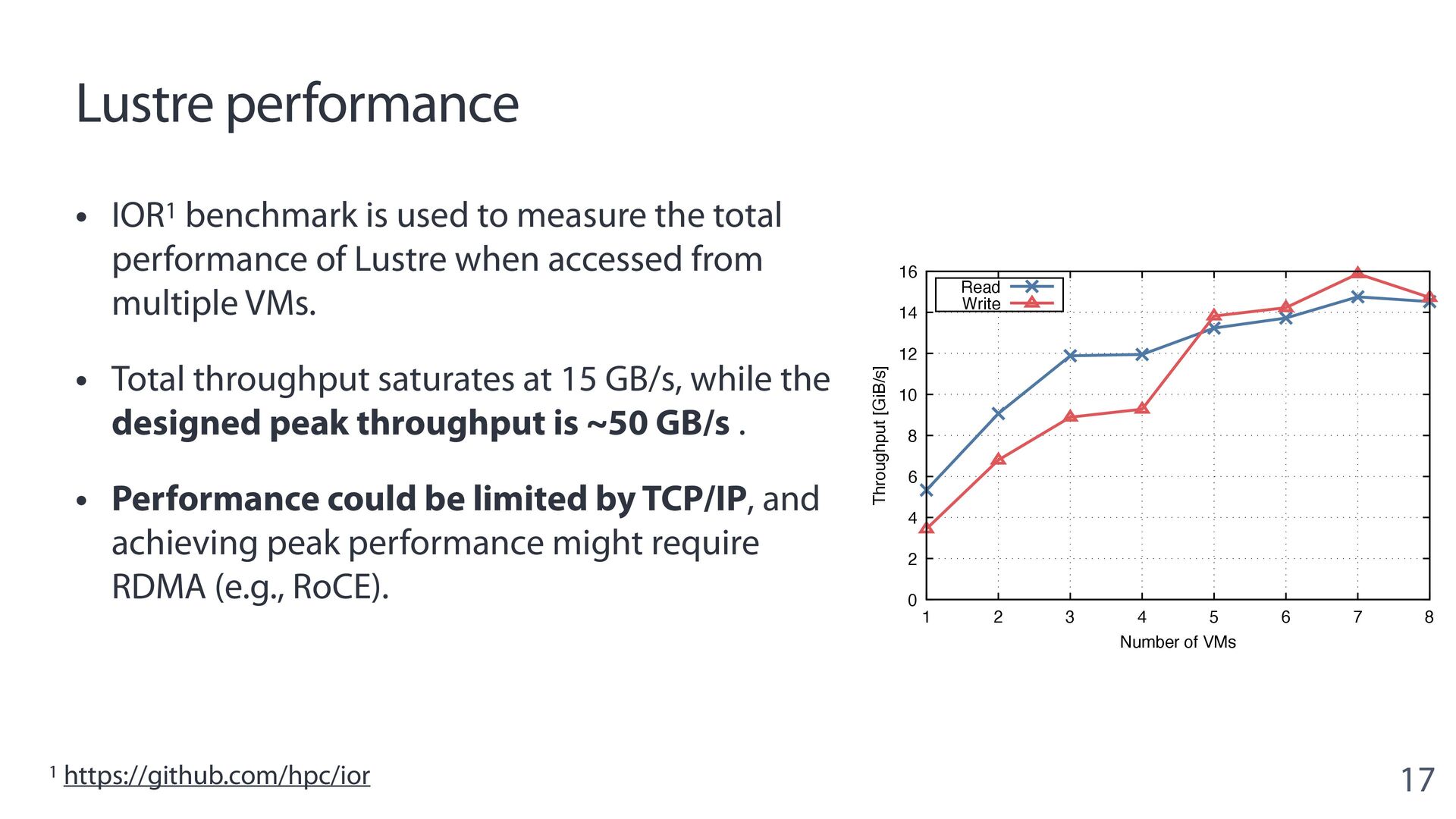{kind=link}
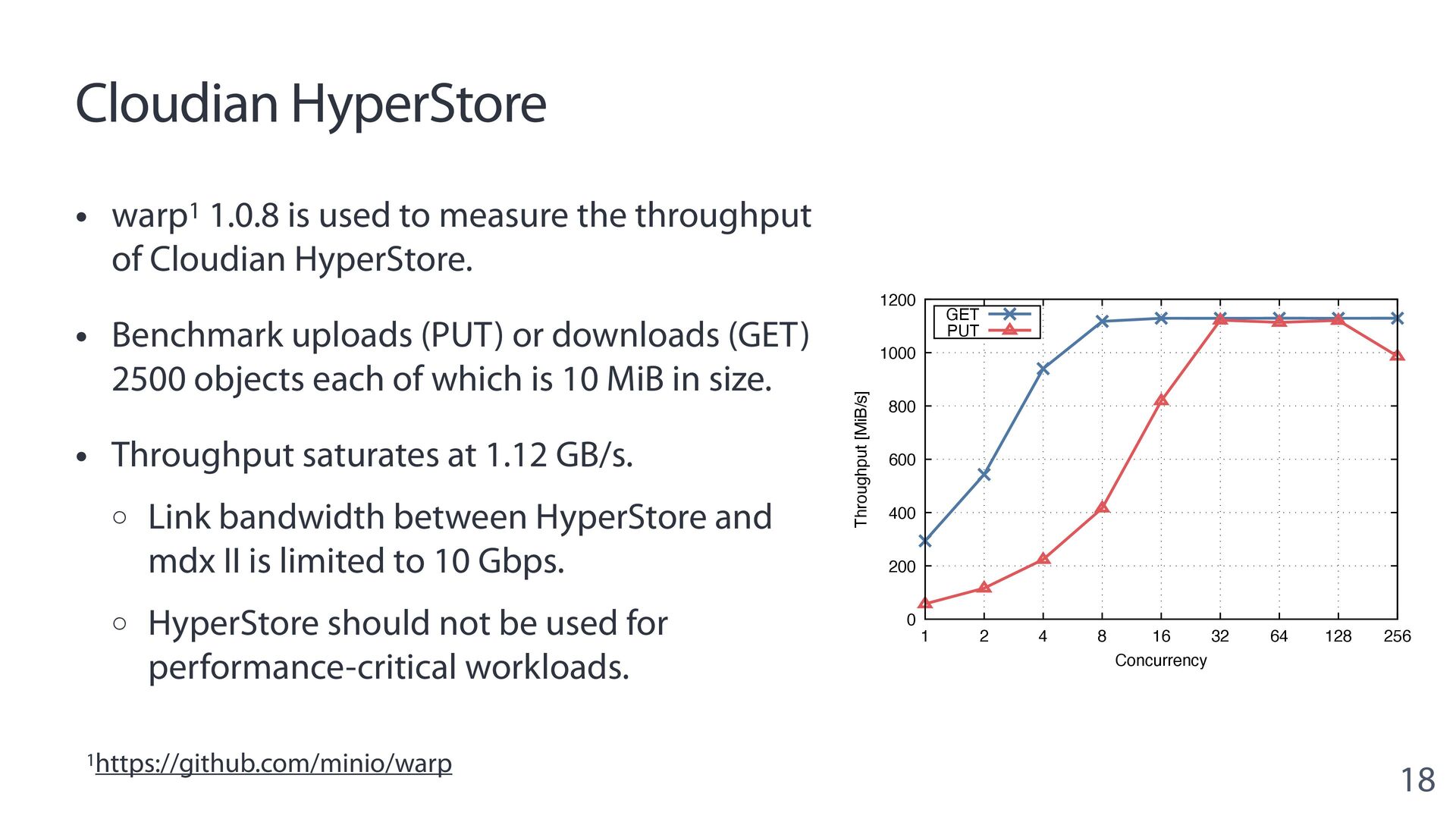{kind=link}
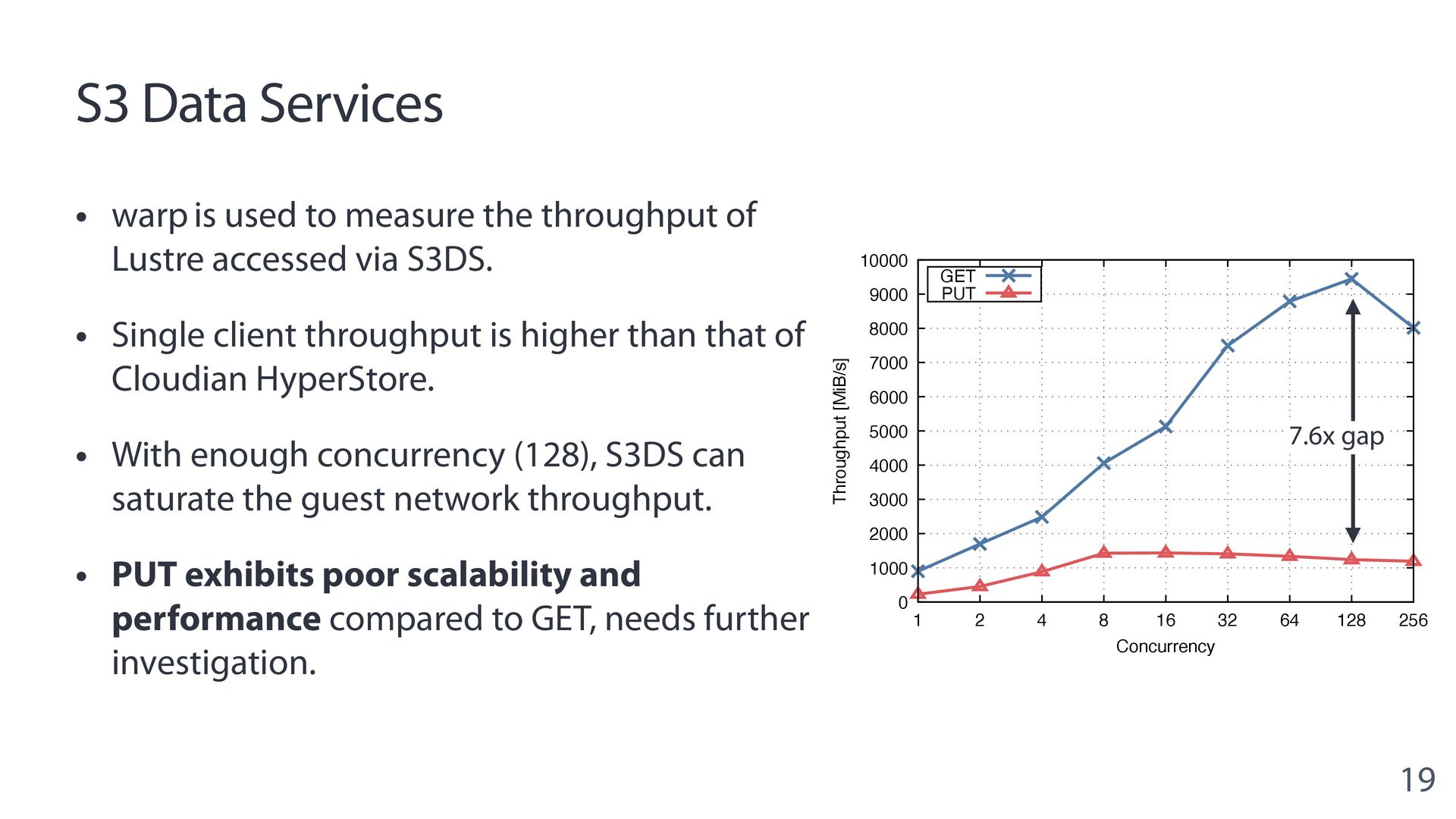{kind=link}
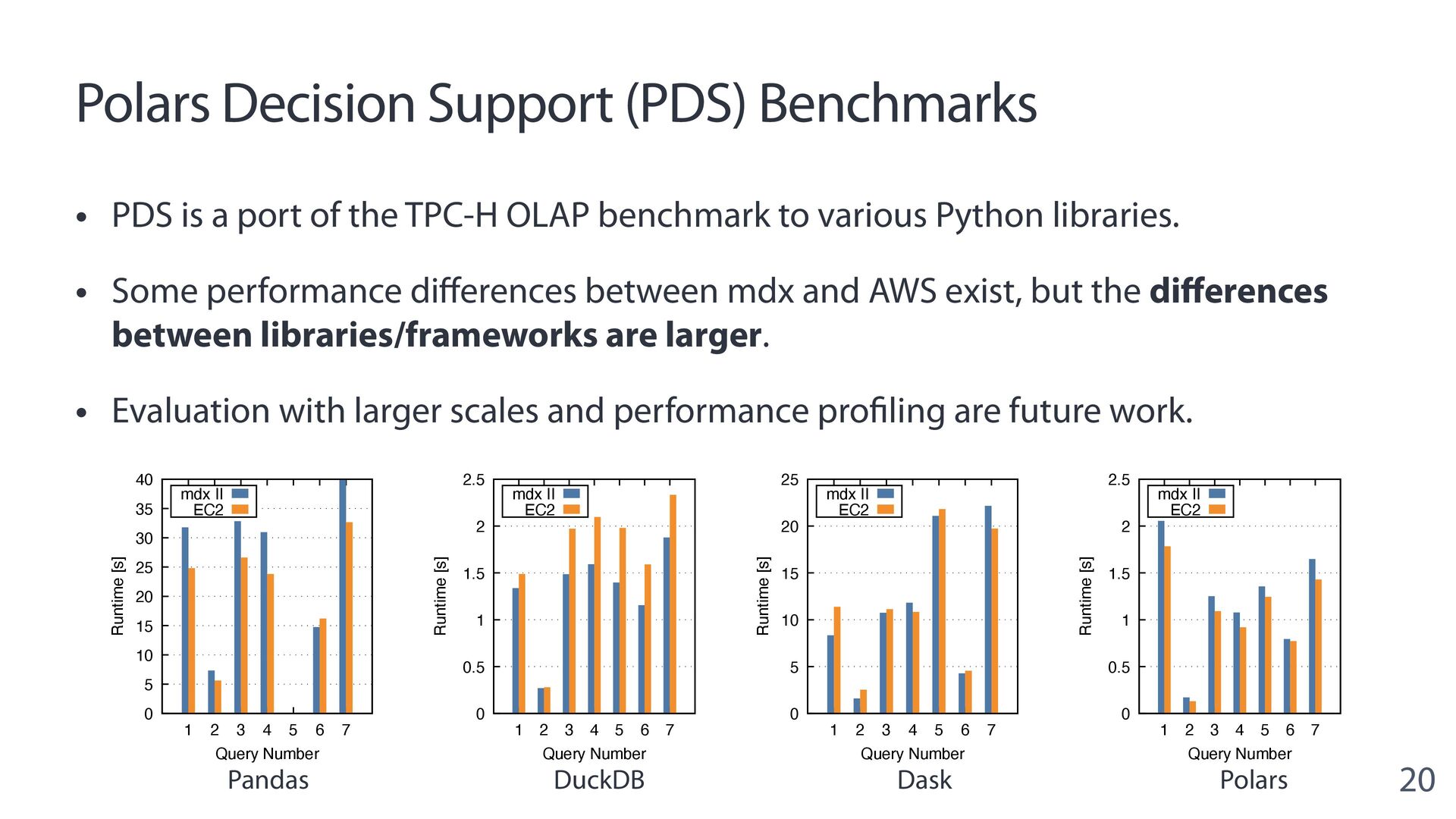{kind=link}
{kind=link}
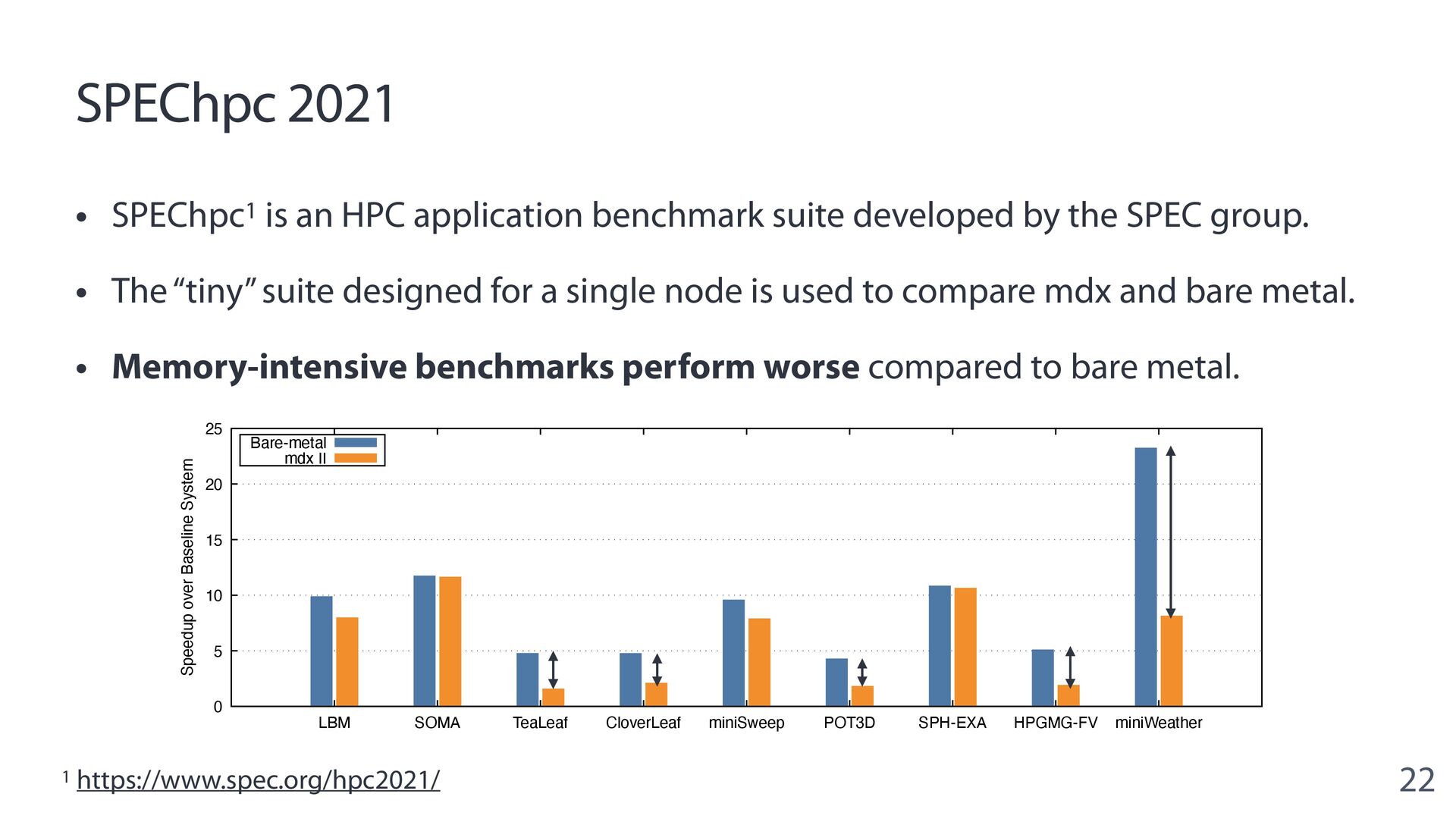{kind=link}
{kind=link}
{kind=link}