Presentation slides for the HKSTS 2023 conference, titled "Dynamic Optimization of Transportation Infrastructure Investment based on Subgame Perfect Equilibrium."
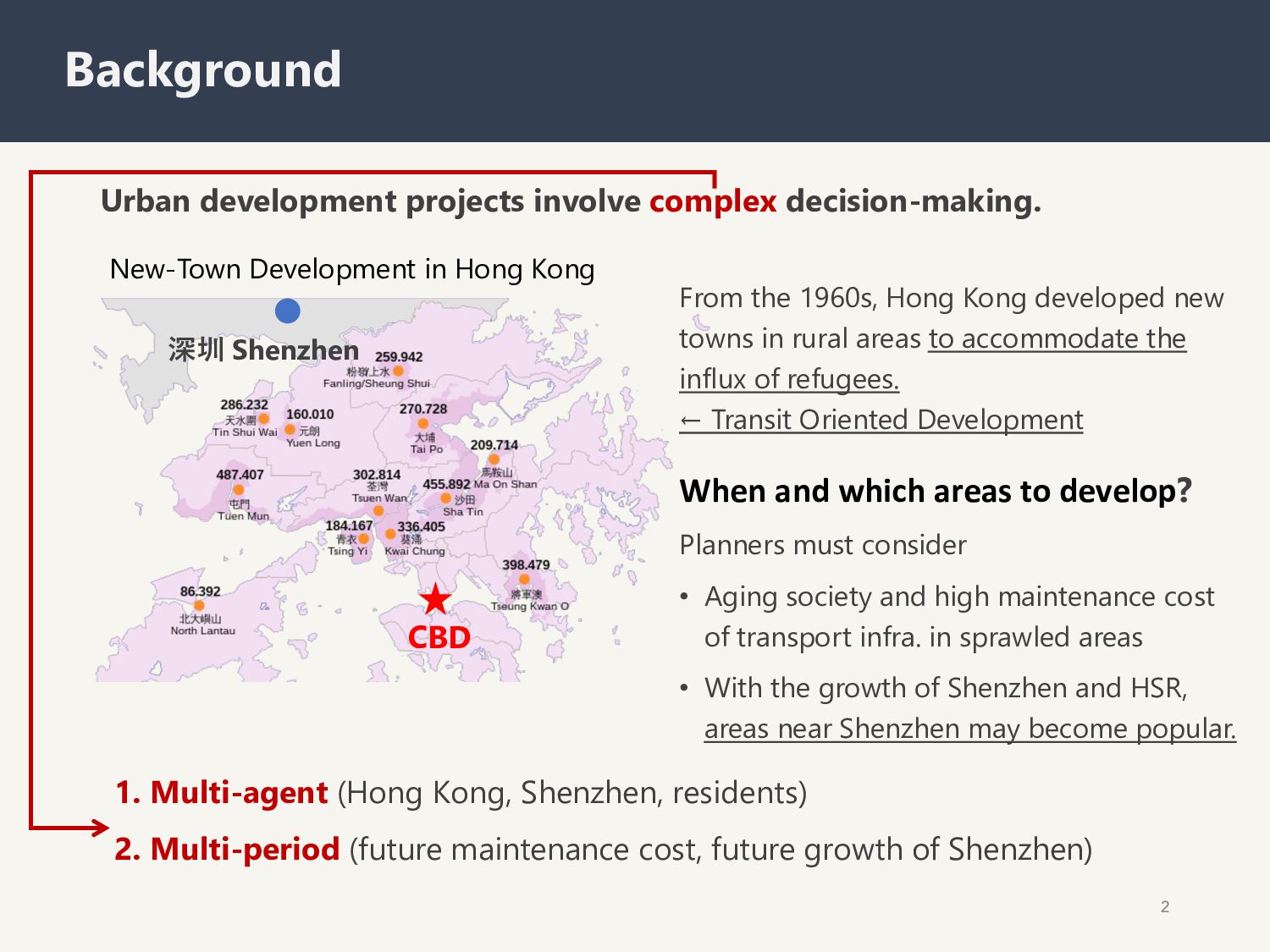
New-Town Development in Hong Kong CBD From the 1960s, Hong Kong developed new towns in rural areas to accommodate the influx of refugees. ← Transit Oriented Development When and which areas to develop? Planners must consider • Aging society and high maintenance cost of transport infra. in sprawled areas • With the growth of Shenzhen and HSR, areas near Shenzhen may become popular. 1. Multi-agent (Hong Kong, Shenzhen, residents) 2. Multi-period (future maintenance cost, future growth of Shenzhen)
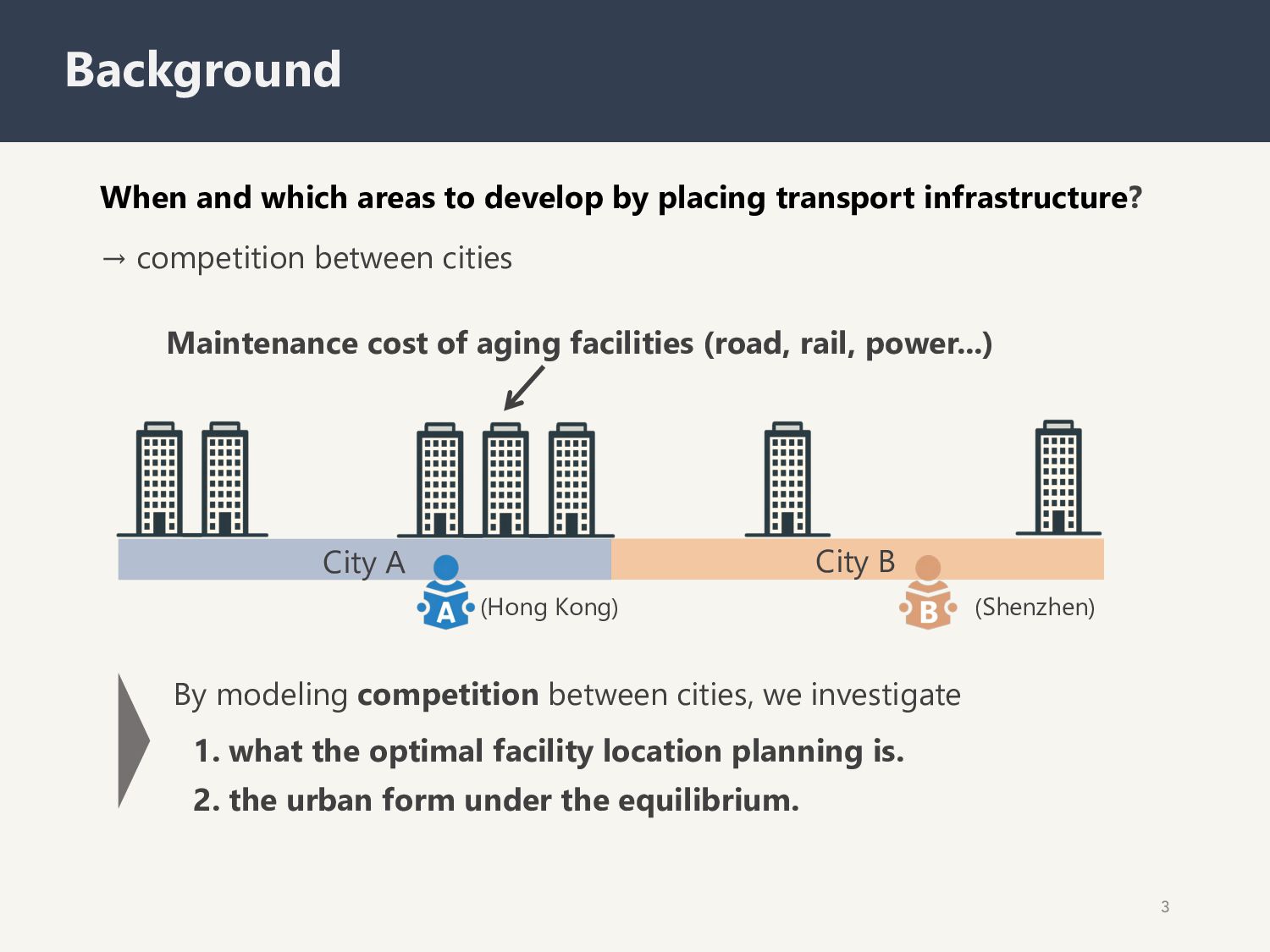
→ competition between cities 3 Background By modeling competition between cities, we investigate 1. what the optimal facility location planning is. 2. the urban form under the equilibrium. City A City B Maintenance cost of aging facilities (road, rail, power...) (Hong Kong) (Shenzhen)
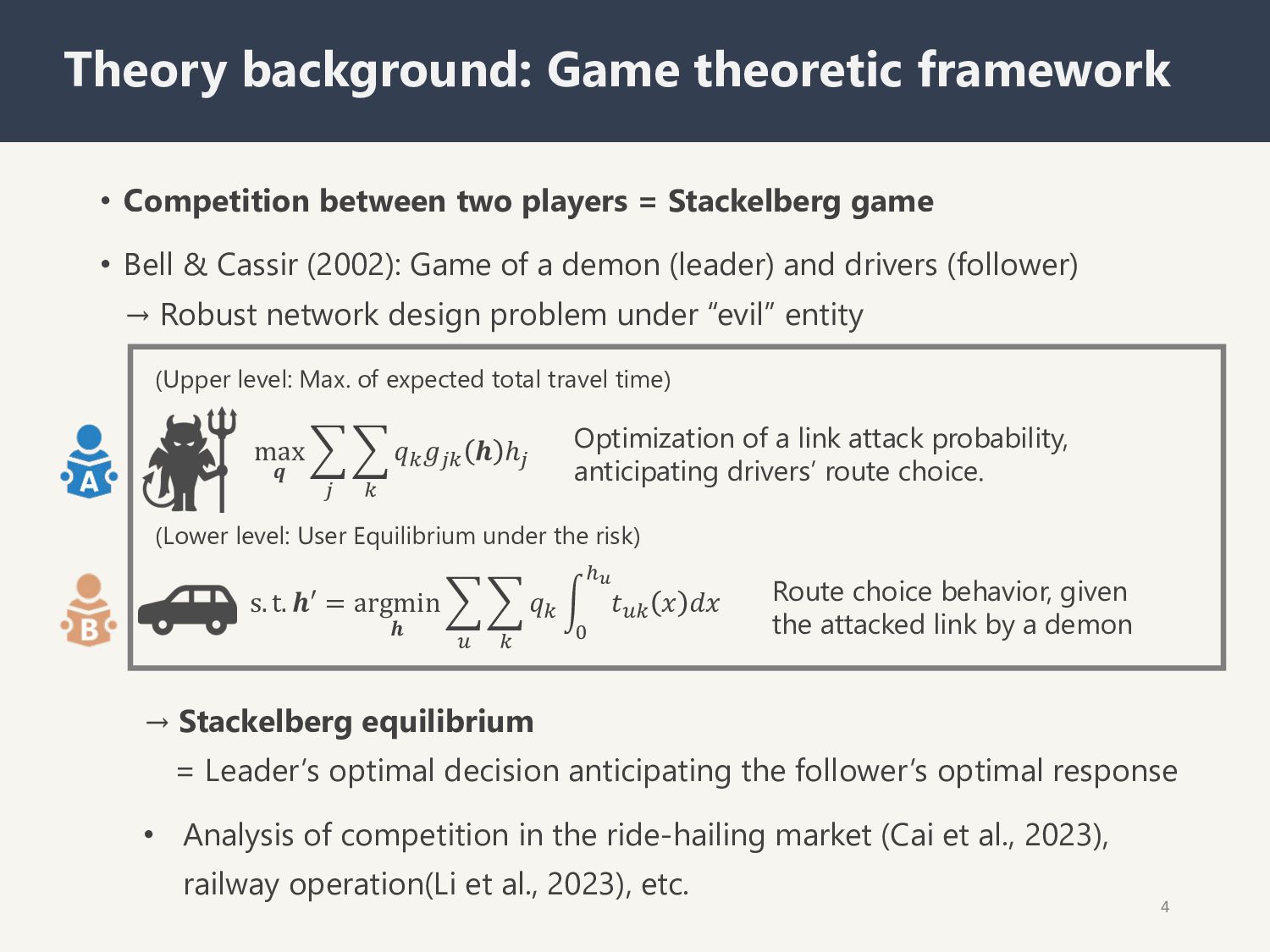
& Cassir (2002): Game of a demon (leader) and drivers (follower) → Robust network design problem under “evil” entity 4 Theory background: Game theoretic framework Optimization of a link attack probability, anticipating drivers’ route choice. max 𝒒 $ " $ # 𝑞#𝑔"# 𝒉 ℎ" s. t. 𝒉′ = argmin 𝒉 $ % $ # 𝑞# 2 & '! 𝑡%# 𝑥 𝑑𝑥 (Upper level: Max. of expected total travel time) (Lower level: User Equilibrium under the risk) Route choice behavior, given the attacked link by a demon → Stackelberg equilibrium = Leader’s optimal decision anticipating the follower’s optimal response • Analysis of competition in the ride-hailing market (Cai et al., 2023), railway operation(Li et al., 2023), etc.
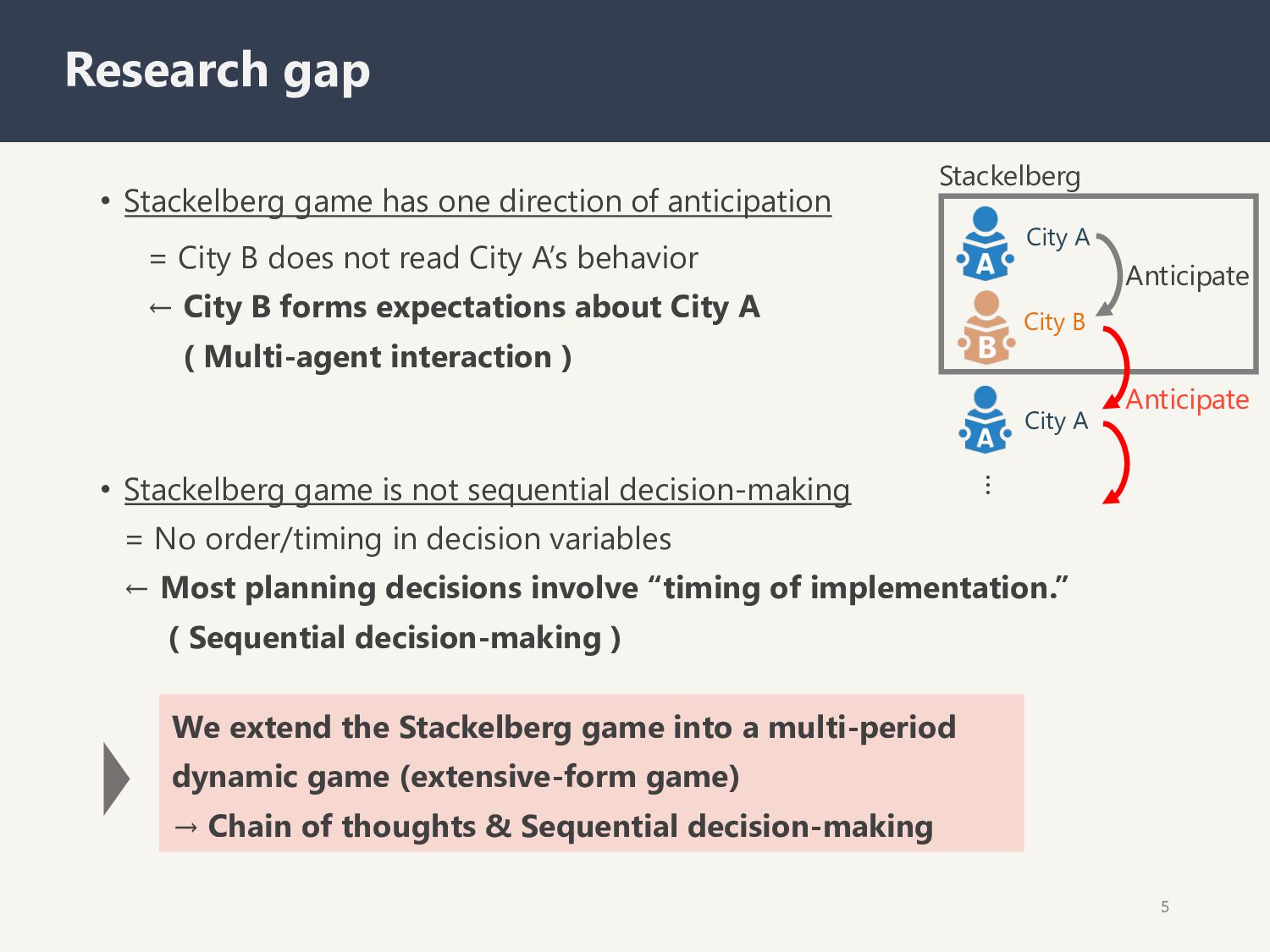
B does not read City A’s behavior ← City B forms expectations about City A ( Multi-agent interaction ) 5 Research gap City A City B Anticipate Stackelberg City A Anticipate … We extend the Stackelberg game into a multi-period dynamic game (extensive-form game) → Chain of thoughts & Sequential decision-making • Stackelberg game is not sequential decision-making = No order/timing in decision variables ← Most planning decisions involve “timing of implementation.” ( Sequential decision-making )
applied Multi-Agent Reinforcement Learning to solve large-scale extensive-form games. → Deep reinforcement learning for large-scale settings • AI-based urban planning (Zheng et al., 2023) Optimization of land use and road network • AI Agent as Urban Planner (Qian et al., 2023) Multi-Agent Reinforcement Learning (MARL) for location decisions of planners, residents, and developers • AI Economist (Zheng et al., 2022) Optimal taxation policy considering rational expectations of residents/planners • Various approaches for bi-level opt. to obtain the Stackelberg equilibrium Iterative calculation, Genetic algorithm, Variational inequality, MPEC, etc.
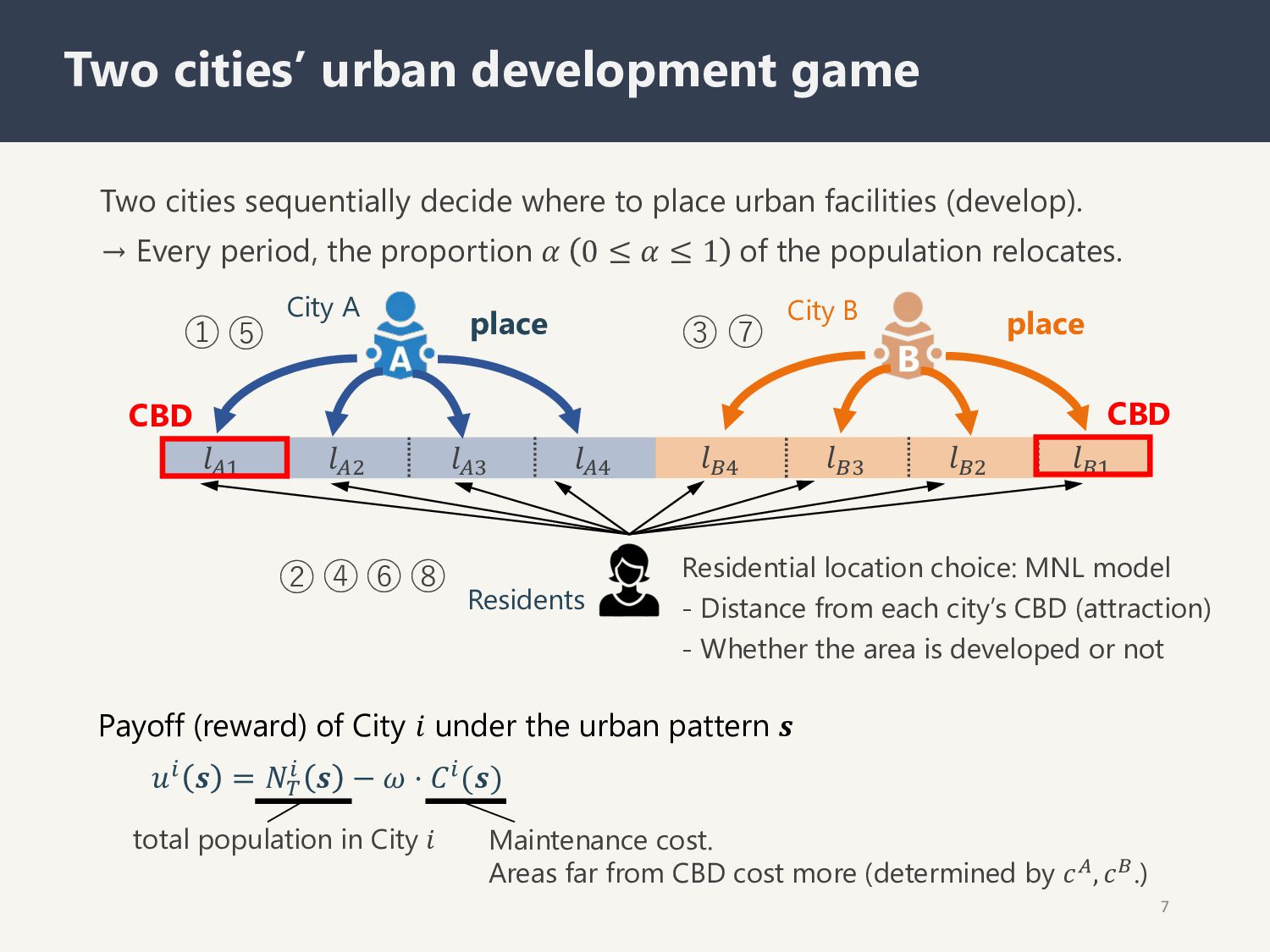
facilities (develop). → Every period, the proportion 𝛼 0 ≤ 𝛼 ≤ 1 of the population relocates. 7 Two cities’ urban development game City A Residents place ① Residential location choice: MNL model - Distance from each city’s CBD (attraction) - Whether the area is developed or not ② place ③ ⑤ ④ ⑥ ⑦ ⑧ 𝑢! 𝒔 = 𝑁" ! 𝒔 − 𝜔 ⋅ 𝐶!(𝒔) Payoff (reward) of City 𝑖 under the urban pattern 𝒔 total population in City 𝑖 Maintenance cost. Areas far from CBD cost more (determined by 𝑐(, 𝑐).) CBD CBD 𝑙#$ 𝑙#% 𝑙#& 𝑙#' 𝑙(' 𝑙(& 𝑙(% 𝑙($
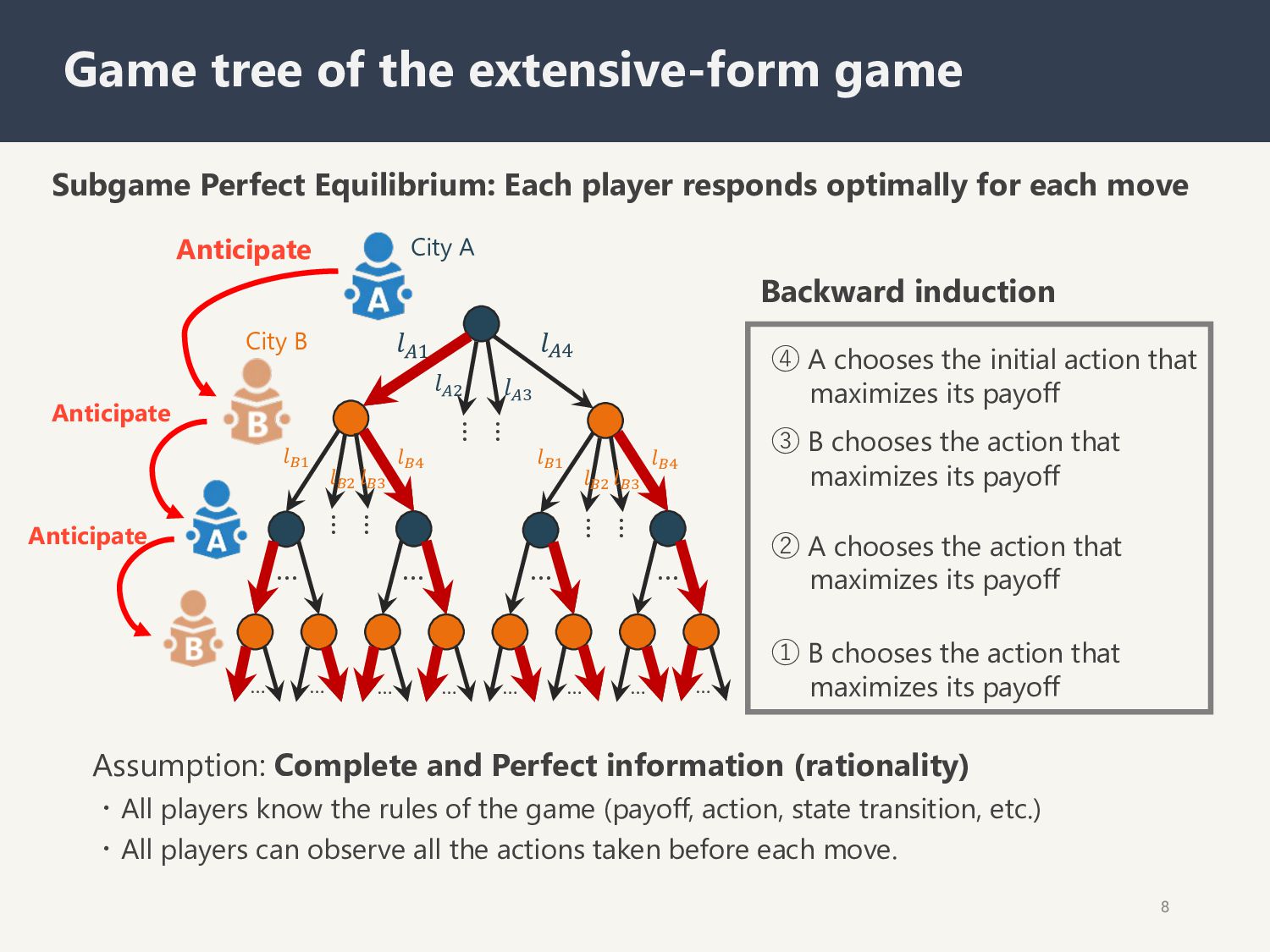
… … … … … … … … 𝑙(* 𝑙(+ 𝑙"# 𝑙"$ 𝑙!" 𝑙!# 𝑙!$ 𝑙!% 𝑙!" 𝑙!# 𝑙!$ 𝑙!% City A City B 8 Game tree of the extensive-form game ① B chooses the action that maximizes its payoff ② A chooses the action that maximizes its payoff ③ B chooses the action that maximizes its payoff ④ A chooses the initial action that maximizes its payoff Backward induction Subgame Perfect Equilibrium: Each player responds optimally for each move Assumption: Complete and Perfect information (rationality) ・All players know the rules of the game (payoff, action, state transition, etc.) ・All players can observe all the actions taken before each move. Anticipate Anticipate Anticipate
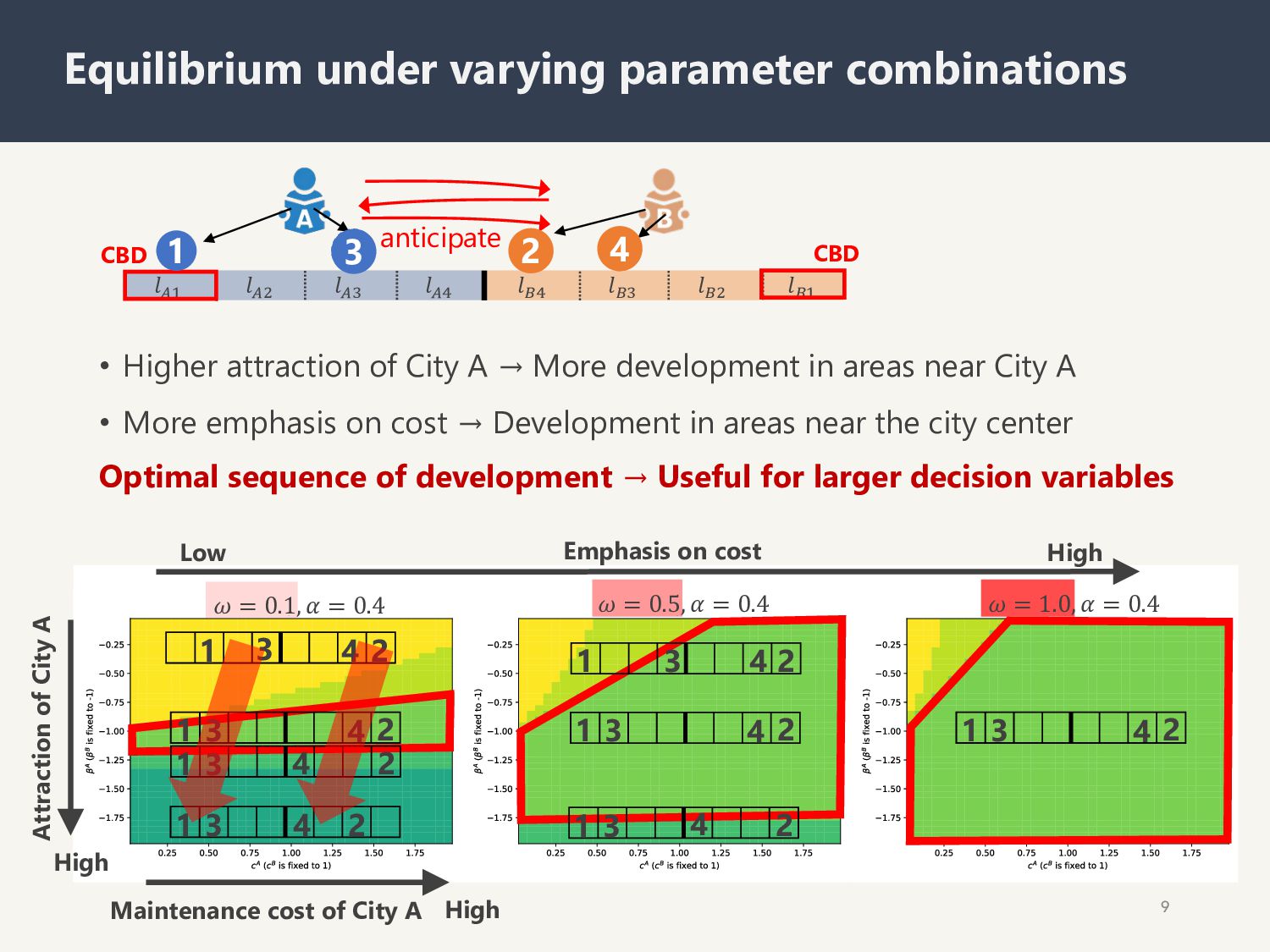
= 0.4 𝜔 = 0.5, 𝛼 = 0.4 𝜔 = 1.0, 𝛼 = 0.4 High Attraction of City A 1 2 3 4 3 2 1 4 3 2 1 4 3 4 1 2 3 2 1 4 3 2 1 4 3 2 1 4 3 2 1 4 Emphasis on cost Low High CBD CBD !!" !!# !!$ !!% !&% !&$ !&# !&" anticipate 2 4 1 3 2 3 4 Optimal sequence of development → Useful for larger decision variables Maintenance cost of City A High • Higher attraction of City A → More development in areas near City A • More emphasis on cost → Development in areas near the city center
space Difficult to calculate the solution by backward induction 10 Extension to Multi-Agent Reinforcement Learning Multi-Agent Reinforcement Learning (MARL) DNN approximates the state value function and optimal policy … … … … … … … … … … … … … … … … … … !!" !!# !!" !!# $!" $!# $!$ $!% $!" $!# $!$ $!% City A City B Zone 4 10 10 10 18 Period 2 2 4 6 20 Calc. time 0.04 sec. 1 sec. 3 hours 3.5 years 1038 years ※ 10-4 sec. for evaluation of 1 game node ↑ case of the next section Calculation time of backward induction
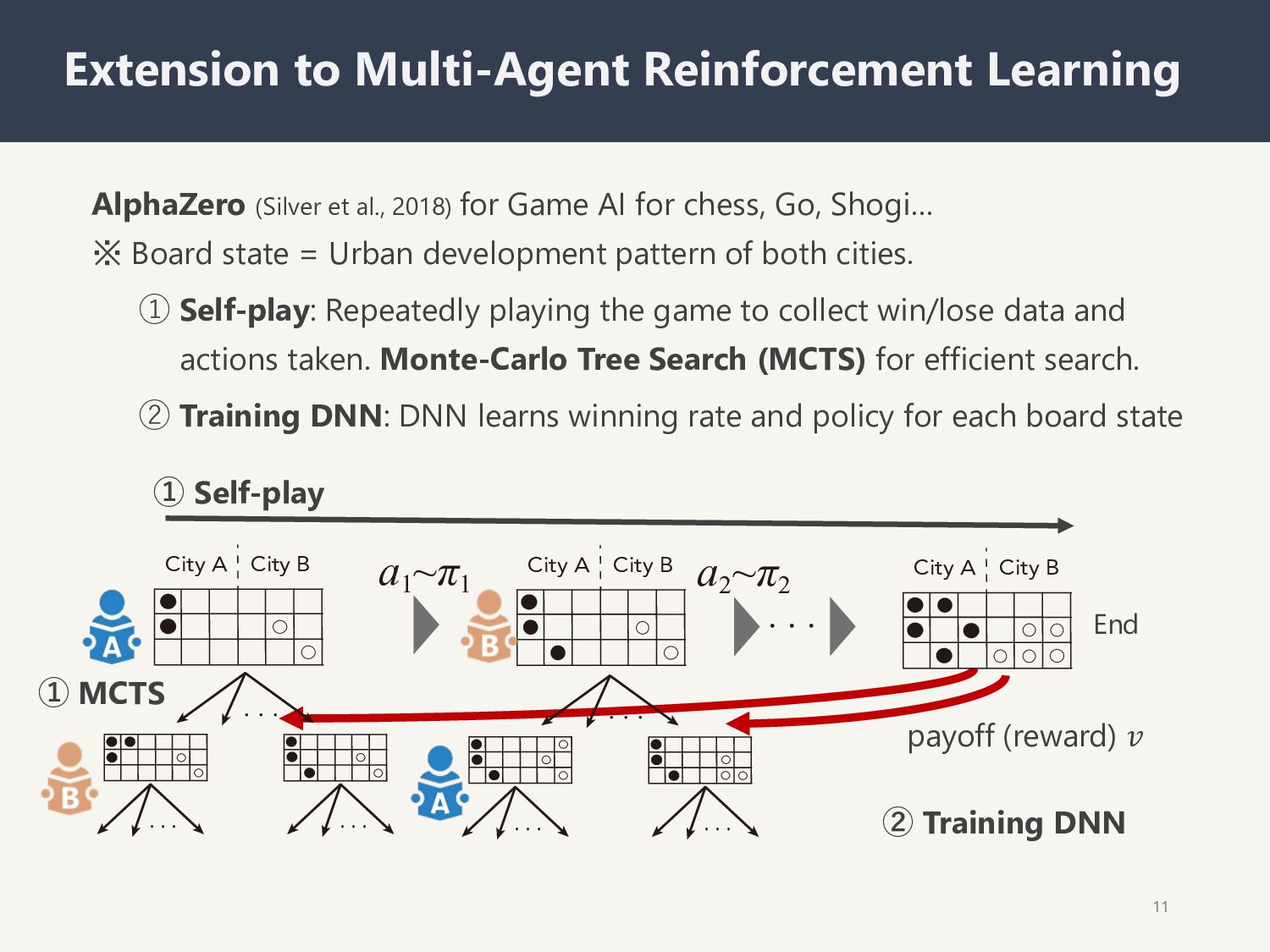
(Silver et al., 2018) for Game AI for chess, Go, Shogi… ※ Board state = Urban development pattern of both cities. ① Self-play: Repeatedly playing the game to collect win/lose data and actions taken. Monte-Carlo Tree Search (MCTS) for efficient search. ② Training DNN: DNN learns winning rate and policy for each board state ① MCTS ① Self-play City A City B a1 aʌ1 a2 aʌ2 ɾɾɾ City A City B City A City B ɾɾɾ ɾɾɾ ɾɾɾ ɾɾɾ ɾɾɾ ɾɾɾ payoff (reward) 𝑣 End
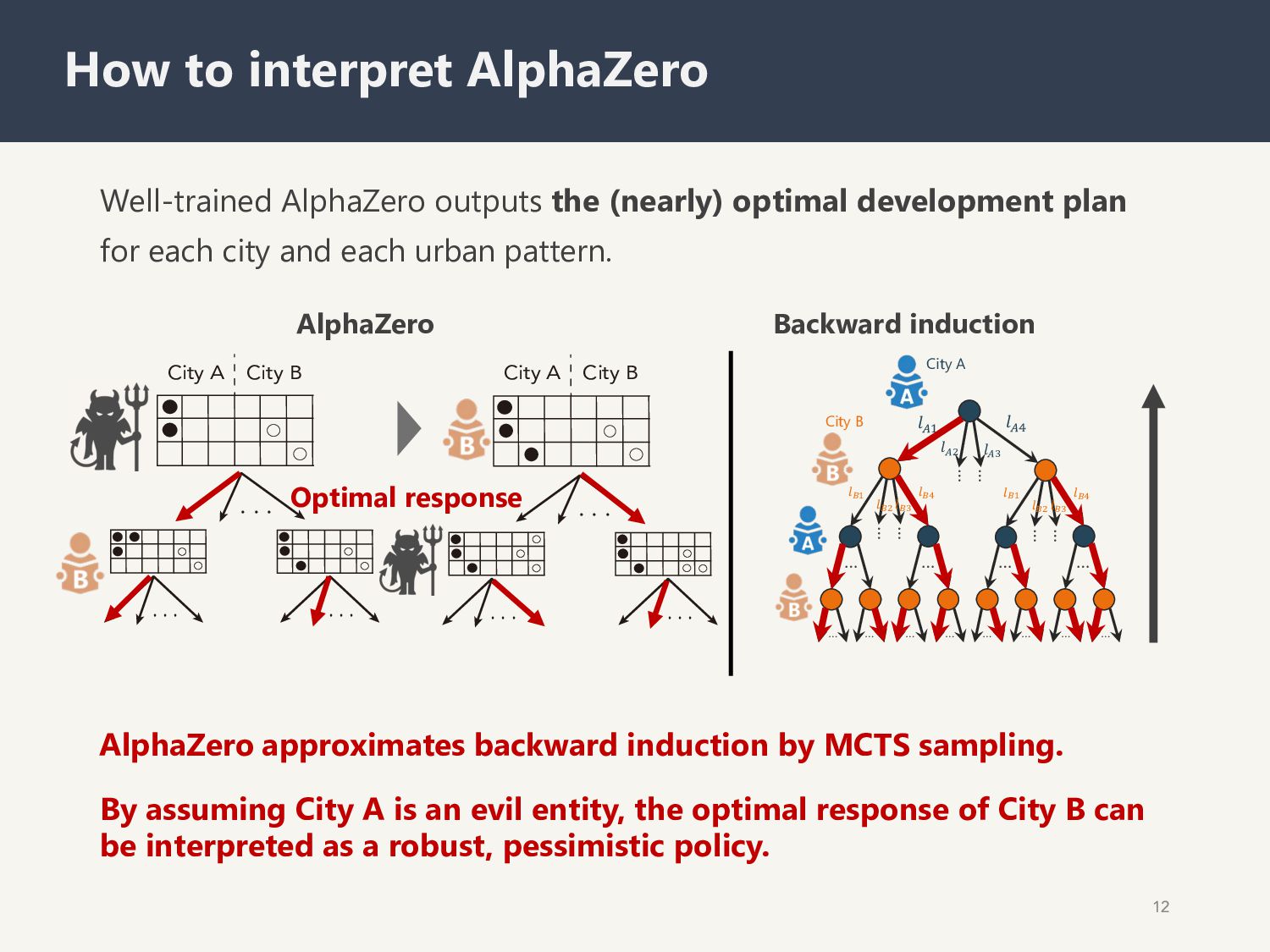
city and each urban pattern. 12 How to interpret AlphaZero AlphaZero approximates backward induction by MCTS sampling. By assuming City A is an evil entity, the optimal response of City B can be interpreted as a robust, pessimistic policy. Backward induction … … … … … … … … … … … … … … … … … … !!" !!# !!" !!# $!" $!# $!$ $!% $!" $!# $!$ $!% City A City B AlphaZero City A City B City A City B ɾɾɾ ɾɾɾ ɾɾɾ ɾɾɾ ɾɾɾ ɾɾɾ Optimal response
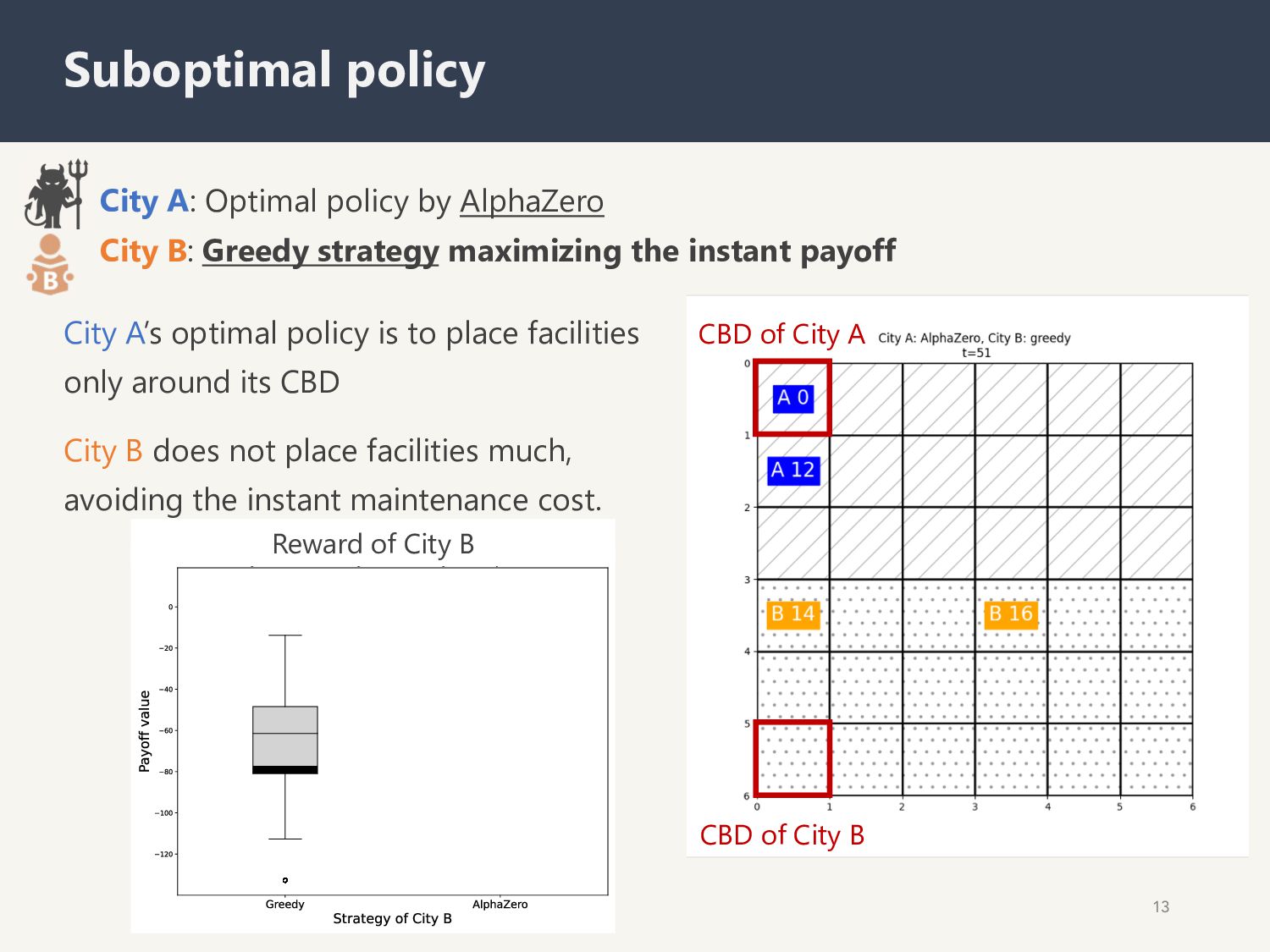
maximizing the instant payoff 13 Suboptimal policy CBD of City A CBD of City B City B does not place facilities much, avoiding the instant maintenance cost. City A’s optimal policy is to place facilities only around its CBD Reward of City B
AlphaZero City B: Optimal policy by AlphaZero CBD of City A CBD of City B Reward of City B City B’s optimal policy is not to develop. ← In these parameters, each city cares much about cost.
game ü Mutual interaction and expectation ü Sequential decision-making → Dynamic Network Design Problem for optimal policy sequence • Multi-Agent Reinforcement Learning for large-scale games ü AlphaZero for approximating dynamic programming by sampling → Analysis of games with complex action spaces and multiple periods Future work / Discussion • Analytical formulation of dynamic games→ dynamic opt., differential games • Assumption of imperfect information • Extension to general MARL, not only 2-player zero-sum game
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![16 Thank you! Slides → Contact [email protected]](https://files.speakerdeck.com/presentations/62f68bb9a8ae49e18ea704d12e79f4b8/slide_15.jpg){kind=link}