= {1, 2, 3, 1000}. Ubiquitous in database or search engines. tests: x ∈ S? intersections: S ∩ S unions: S ∪ S differences: S ∖ S Jaccard Index (Tanimoto similarity) ∣S ∩ S ∣/∣S ∪ S ∣ 2 1 2 1 2 1 1 1 1 2 3
iterators (jump to first value ≥ x) Rank: how many elements of the set are smaller than k? Select: find the kth smallest value Min/max: find the maximal and minimal value 4
imutable. sorted arrays ( s t d : : v e c t o r < u i n t 3 2 _ t > ) hash sets ( j a v a . u t i l . H a s h S e t < I n t e g e r > , s t d : : u n o r d e r e d _ s e t < u i n t 3 2 _ t > ) … bitsets ( j a v a . u t i l . B i t S e t ) compressed bitsets 6
on 64‑bit words. Given index x , the corresponding word index is x / 6 4 and within‑ word bit index is x % 6 4 . a d d ( x ) { a r r a y [ x / 6 4 ] | = ( 1 < < ( x % 6 4 ) ) } c o n t a i n s ( x ) { r e t u r n a r r a y [ x / 6 4 ] & ( 1 < < ( x % 6 4 ) ) } 8
fast! Roughly three instructions (on x64)... i n d e x = x / 6 4 - > a s i n g l e s h i f t m a s k = 1 < < ( x % 6 4 ) - > a s i n g l e s h i f t a r r a y [ i n d e x ] | - m a s k - > a l o g i c a l O R t o m e m o r y (Or can use BMI's b t s .) On recent x64 can set one bit every ≈ 1.65 cycles (in cache) Recall : Modern processors are superscalar (more than one instruction per cycle) 9
3} and {1, 3} can be computed as AND operation between 0 b 1 0 1 1 and 0 b 1 0 1 0 . Result is 0 b 1 0 1 0 or {1, 3}. Enables Branchless processing. 10
n [ 0 . . . n ] o u t [ i ] = A [ i ] & B [ i ] Recent x64 processors can do this at a speed of ≈ 0.5 cycles per pair of input 64‑bit words (in cache) for n = 1 0 2 4 . 0.5 m e m c p y runs at ≈ 0.3 cycles. 0.3 11
one‑value look‑up. But they have poor data locality and non‑trivial overhead... h 1 < - s o m e h a s h s e t h 2 < - s o m e h a s h s e t . . . f o r ( x i n h 1 ) { i n s e r t x i n h 2 / / " s u r e " t o h i t a n e w c a c h e l i n e ! ! ! ! } 16
this: v a r d = S e t < I n t > ( ) f o r i i n 1 . . . s i z e { d . i n s e r t ( i ) } / / v a r z = S e t < I n t > ( ) f o r i i n d { z . i n s e r t ( i ) } This blows up! Quadratic‑time. Same problem with Rust. 17
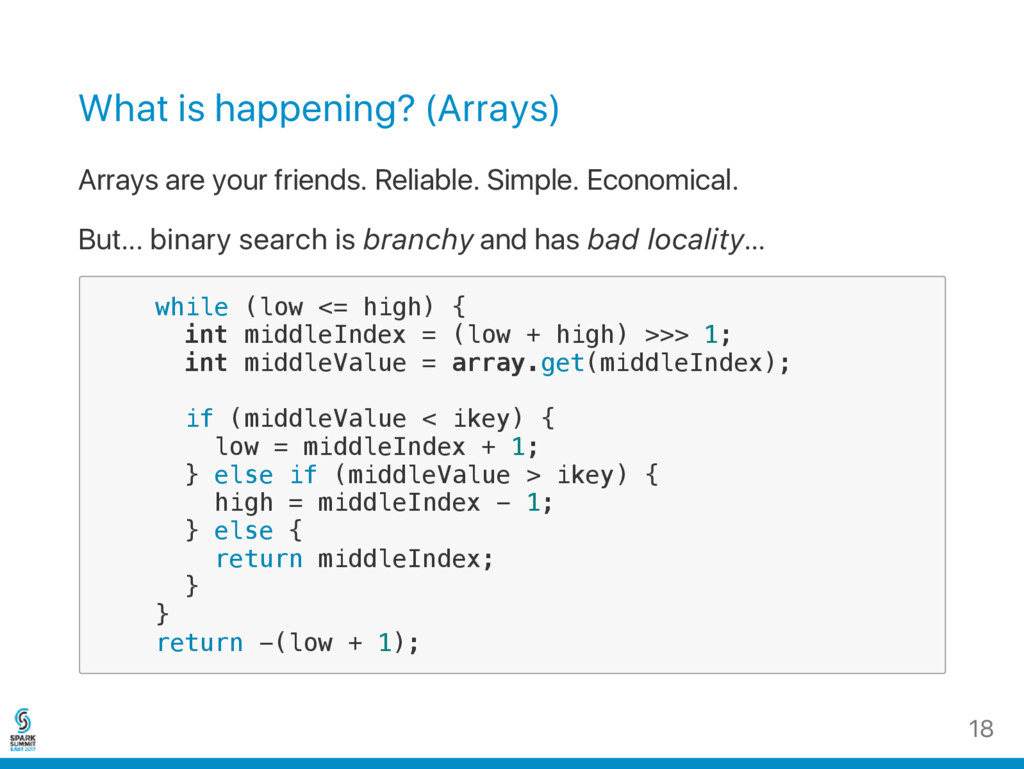
Economical. But... binary search is branchy and has bad locality... w h i l e ( l o w < = h i g h ) { i n t m i d d l e I n d e x = ( l o w + h i g h ) > > > 1 ; i n t m i d d l e V a l u e = a r r a y . g e t ( m i d d l e I n d e x ) ; i f ( m i d d l e V a l u e < i k e y ) { l o w = m i d d l e I n d e x + 1 ; } e l s e i f ( m i d d l e V a l u e > i k e y ) { h i g h = m i d d l e I n d e x - 1 ; } e l s e { r e t u r n m i d d l e I n d e x ; } } r e t u r n - ( l o w + 1 ) ; 18
0s or 1s. Use run‑length encoding (RLE) Example: 000000001111111100 can be coded as 00000000 − 11111111 − 00 or <5><1> using the format < number of repetitions >< value being repeated > 20
value x, its chunk index is x ÷ 2 (16 most significant bits). For each chunk, use best container to store least 16 significant bits: a sorted array ({1,20,144}) a bitset (0b10000101011) a sequences of sorted runs ([0,10],[15,20]) That's Roaring! Prior work: O'Neil's RIDBit + BitMagic 16 22
L1 cache) Attempts to select the best container as you build the bitmaps Calling r u n O p t i m i z e will scan (quickly!) non‑run containers and try to convert them to run containers 23
( p o p c n t ) to count the number of 1s in a word. Cheap to keep track of the number of values stored in a bitset! Choice between array, run and bitset covers many use cases! 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}